
I plan on making a slurp detector. I will be basing this off of Sam Lavigne’s videogrep – but for slurps. Google Teachable Machine also has a function to train an audio model, so I plan on extracting 1 second audio clips from my previous footage to get a prototype slurp model.
Author: friendlygrape
friendlygrape – final
Slurp detection gone wrong
I (tried) making a slurp detector.
What is this?
This is (intended) to be a command line slurp detection tool that would automatically embed captions into the video whenever a slurp sound appears. It would also produce an srt file, which would give you the time stamps of every slurp that occurred in the video.
Why is this interesting?
I particularly thought the idea of capturing just slurps was quite humorous and in line with my previous project with PersonInTime. Additionally, while preexisting human voice datasets, with the most well known one being AudioSet, do have tokens for classifying human sounds. However, their corpus of human sounds only contains digestive sounds pertaining to mastication, biting, gargling, stomach-grumbling, burping, hiccuping and farting. None of these are slurping, which I argue is the most important human digestive sound in the world. I feel like this is wasted potential, as many (many) people would benefit from being able to detect their slurps.
Where will/does/would this live?
This would live as a github repository/tool available for all to detect their slurps.
What does this build off of?
This work was primarily inspired by Sam Lavigne’s videogrep tool, which generates an srt file using vosk and makes supercuts of user-inputted phrases on videos. Audio classification tools have also been around, with some famous ones being tensorflow’s yamnet and OpenAi’s recent release, Whisper .
This work is a continuation of thoughts I had while completing my experiments for PersonInTime. In particular, I was thinking a lot about slurps when I fed my housemates all those noodles, which organically led to this idea.
Self-Evaluation
Where did you succeed, what could be better, what opportunities remain?
I failed in almost every way possible, since the slurp detector has yet to be made. Perhaps the way I’ve succeeded is by gathering research and knowledge about the current landscape of both captioning services on github and the actual exportable models used on teachable machine.
The thing itself
my slurp dataset which I will use to make my slurp detector
The Process
I started this process by first just trying to replicate Sam Lavigne’s process with vosk, the same captioning tool used in videogrep. However, I soon realized that vosk was only capturing the english works spoken, and none of the other miscellaneous sounds emitted by me and my friends.
So then I realized that in order to generate captions, I had to generate my own srt file. This should be easy enough, I foolishly thought. My initial plan was to use Google’s Teachable Machine to smartly create a quick but robust audio classification model based on my preexisting collection of slurps.
My first setback was stubbornly refusing to record slurps with my microphone. At first I was extremely averse to that idea because I had already collected a large slurp-pository from my other videos from PersonInTime, so why should I have to do this extra work of recording more slurps?
Well, naive me was unaware that Teachable Machine prevents you from uploading audio datasets that aren’t encoded using their method, which is basically a webm of the recording plus a json file stored in a compressed folder. Then, I thought to myself, it shouldn’t be too hard to trick teachable machine into thinking my slurp-set was actually recorded on the website, just by converting the file into an webm, and providing the appropriate tags in the json file.


This was my second mistake, since what the heck were frequencyFrames? The other labels were pretty self explanatory, but the only documentation I could find about frequency Frames was this one Tensorflow general discussion post where some guy was also trying to upload his own audio data to Teachable Machine. The code posted in that discussion didn’t work and I may have tried to stalk the questioner’s github to see if they posted the complete code (they did not). The person who responded, mentioned the same data for training with the speech_commands dataset, which was not what I wanted since it did not have slurps in it.
So after looking at this and trying to figure out what it meant, I decided my brain was not big enough at the time and gave up.
I decided to record on Teachable Machine in the worst way possible, recording with my laptop microphone while blasting my slurps-llection hopes that the slurps would be recorded. I did this with the aim to get something running. I still had the naiveté that I would have enough time to go back a train a better model, using some other tool other than Teachable Machine. (I was wrong)
So I finished training the model on teachable machine, and it worked surprisingly well given the quality of the meta-recorded dataset. However, I didn’t realize I was about to encounter my third mistake. Teachable Machine audio models only exported as TF.js or TFlite and not as keras, which was the model type that I was most used to handling. I had also already found a srt captioning tool on github that I wanted to base my modified tool off of (this one, auto-subtitle, uses Whisper oooo) but in python, and I thought the easiest way to combine the tools would be to load the model with plain Tensorflow. Determined to work with something I was at least somewhat familiar with, I tried converting the TF.js layered model into a TF saved model. To do this, I used the tfjs-converter that tensorflow already provided for situations like these. After some annoying brew issues, I converted the model to python. Which is where I’d encounter my fourth mistake.
What I didn’t realize while I was converting my model was that the teachable machines audio component is based off the the model topology of the Tensorflow.js Speech Commands model, which as the name implies is build on top of Tensorflow.js and there isn’t any documentation on non javascript implementations or work arounds, which ultimately dissuaded me from trying to test out whether my converted keras model would even work or not.
At this point, I thought, maybe I shouldn’t even be using Teachable Machine at all? (which was probably what I should’ve done in the first place, since the amount of time I’ve spent trying to work around unimplemented things would’ve been enough to train an audio classification model). I looked at RunwayML’s audio tools. Currently, their selection is very limited (4, noise reduction, silence gap deletion, caption production and real-time captioning), and it wasn’t exactly what I wanted either. I encountered the same problem as I did with vosk, it only recorded words.
At this point I turn to the almighty Coding Train videos to give me some more insight, and from there I learn about RunwayML-SDK, where you should be able to port your own trained models into their built-in tools. Wow, perfect! me thinks with excess zealotry. For when I hath opened the github repo, what did I see?
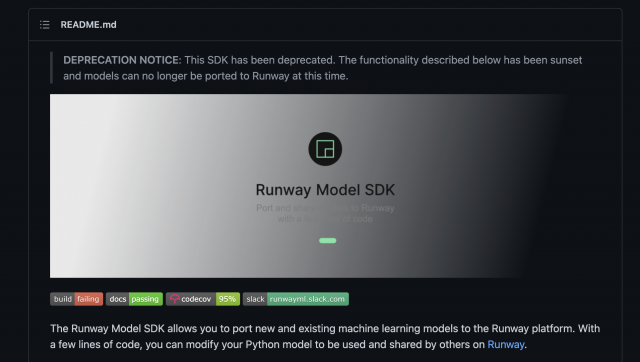
This repository was archived + deprecated LAST MONTH (November 8th 2022).
After a whimsical look at some p5.js (ml5 SoundClassifiers are default the microphone, with no documentation on other audio input sources on their website or in the code directly of which I could find) I was back a square one.
Although there are many captioning repositorys written in python, there are almost none that are written in javascript. The most I could find was this one, api.video, which is a fancier fork of another repository that basically is a wrapper for a transcription service, Authot (interesting name choice). They just send the video over the Authot, get the vtt file and return it as that.
At this point I realize that I’m back to square one. I initially wanted to use Teachable Machine because of personal time constraints; I thought it’d be an easier way for me to get the same final product. But given the kind of probing I had to do (completely in the dark about most of these things before this project), it was not worth it. Next steps for me would be to just train an audio classification model from scratch (which isn’t bad, I just allocated my time to the wrong issues) and take my captioning from there in python. For now, I have my tiny slurp dataset. :/
friendlygrape – PersonInTime
The Project:
For this project, I recorded my housemates eating various noodles with various cameras.
Process:
My primary research questions for this project were: Do my my housemates eat noodles differently? And if so, how?
I settled on this idea after spending some time with my family over fall break. During one dinner with my parents, I noticed how me and my dad peeled clementines differently: I peeled mine in a single continuous spiral while my dad preferred to peel off tiny scraps until a sizable pile accumulated on the dinner table.
This prompted me to think about how eating habits affect and translate to personalities. If you eat loudly and slouch, I assume you’re a lively and boisterous person. Similarly, if you eat quietly then I assume you’re a quiet person :/
I knew that I wanted to capture the quiddity of my housemates, for two reasons:
- I have known these people for all four years of undergrad, some for even longer.
- We live together and have lived together for the past 2 years. They already know about all of my shenanigans.
One of the hardest dishes to eat “politely” has got to be (in my opinion) a soupy bowl of noodles. If you’re not careful, they can splash everywhere. If your slurp game is nonexistent, you could end up with soup dribbling down your chin when you try to take a bite of noodle.
So I voiced my ideas to both Golan and Nica. After a couple of conversations with both of them, they each gave me many ideas about different ways I could record my housemates with a bowl of noodles.
So while I had initially just wanted to record some slurps, I realized I had to give my housemates a real challenge.
Experiment 1: Normal Eating
For this experiment, I just wanted a baseline for noodle comparisons. It didn’t take a lot of persuasion to get my housemates on board with this project (trade offer: I give you free food, you let me record you). I borrowed a camcorder and a shotgun microphone and sat each of my housemates down and recorded them all eating a bowl of noodles in one night. While there were some ingredients that varied between bowls (upon request of the eater to add ingredients they’d like) the base of the dish was still the same: ramen.
Here’s the video:
Something that was quite interesting about this result was that after filming, many of them said they felt the pressure from the camera just being pointed at them, that the noodles were very hot (oops), and they ate quicker because of the pressure. This was unfortunately expected from a direct recording. I had initially planned on putting a hidden camera somewhere in the house so that they wouldn’t notice they were being filmed, but I found it quite hard to find suitable hiding places for my camera. Plus, it’s very hard for me to lie to my housemates about random things, the moment I asked if I could make bowls of ramen for everyone out of nowhere I just spilled the beans.
I do think a hidden camera would have been interesting, perhaps in a different setting it would be a viable /more reliable experiment.
Experiment 2: 360 camera
This experiment entailed making a rig that would go in front of the wearer’s face while they were eating a bowl of noodles.
At first, I was given a Samsung Gear 360 camera to test out. Ultimately, after a night of fiddling with the camera, I decided that the accompanying software was shite (refused to work both on my phone and on my mac, they stopped supporting the app/desktop year ago) and gave up. I tried to manually unwarp the footage I got (double fisheye) with some crude methods.
Here’s a video of me eating some cheese + some other things.
I used very crude methods to unwarp the footage, and have included the ffmpeg commands used for the later two clips. Although I ultimately did not create the rig for the camera, since I couldn’t get the warp to look seamless enough, I do this think this is also a future experiment. Sidenote: (what I call) flat face photography is blowing my mind and I will be making more.
Experiment 3: a single noodle
For this experiment, I tried creating a single noodle to slurp. Since regular store bought noodles don’t come in outrageous sizes, I decided that making my own dough wouldn’t be too hard (first mistake).
I simply combined 11+ ounces of all-purpose flour with 5.5 ounces (combined) of water and 2 eggs. After kneading for a while, I knew I messed up the recipe. The dough was too sticky, and I most likely over-kneaded the dough trying to get the dough to a manageable consistency.
After I cut the dough into one continuous piece the “noodle” looked like this:

I then boiled the noodle, added some sauce, and gave it to one of my housemates to try.
This one in particular was a failure. Although they didn’t taste bad (according to said housemate), the noodles were way too thick and brittle, and it was almost like eating a pot full of dumpling skin. I think a future experiment would be to experiment with other dough recipes (using bread flour instead of all purpose, tweaking the water to flour ratio, time to let dough rest, adding oil) to see which would yield the longest “slurpable” noodle.
Experiment 4: Owl camera + Binaural Audio
This experiment was brought about after talking with Nica about my project. They asked if I had ever heard of the Owl camera, and I was surprised to learn that these hotshots are 360 footage + AI in ONE (wow :0 mind kablow). They’re used for hotshot zoom company meetings to allow people who are speaking at a meeting table to be broadcasted on the screen. I paired this device with a 3Dio Free Space binaural audio device, in hopes that I could capture some 360 SLURPING action.
These devices were relatively easy to use, the main difficulty was locating a circular table on campus: this one in particular is by the post office in the UC.
For the meal I prepared biang biang noodles in a cold soup with some meat sauce (a strange combination, but I wanted soup to be present for slurping). Biang Biang noodles are also super thick, so I thought it would be an interesting noodle to try. Ultimately this experiment became a mukbang of sorts.
Takeaways:
Overall, I think I was successful with this project in the fact that I completed what I set out to do with my initial research question. There were definitely many failures along the way as mentioned previously, but these failures only open up more pathways for exploration (in my opinion).
I’d definitely continue iterating on this project. There were many proposed experiments tossed around that ultimately I couldn’t do this time (but would love to do with more time). I also wanted to capture a group noodle eating session (out of one bowl). Another idea I had was to create a slurp detector (inspired by Sam Lavigne’s videogrep) so I could compile all the slurps from my noodle sessions, but I couldn’t get my audio detector to work in time. Golan had mentioned candele noodles as a kind of noodle particularly hard to slurp, and I think my housemates would be up to the challenge.
friendlygrape – PersonInTimeProposal
For my project, I plan on using OpenPose to record the skeletons of both me and my mother while we participate in a virtual dance lesson.
friendlygrape – twocuts
1 opening cut/setting: audio + body skeleton data of a zumba class
2 closing cut/observer: difference in movement and behavior
friendlygrape-TypologyMachine
The Project:
For this project, I conducted a study of bathroom deserts around CMU campus.
Process:
The research question: How long does it take to find a gendered vs gender-inclusive bathroom on campus?
I was particularly inspired by the NYT’s Ten Meter Tower project and Meaghan Kombol’s The Subway Lines, which both explore the experience of performing daily/non-daily tasks, such as diving off of a ten meter diving board or riding the subway. These projects compelled me to think about what tasks I do on a daily basis that I personally don’t pay much attention to. This is how I decided on going to the bathroom.
After talking with Nica about this project, the aim changed from just exploring areas of the campus where I go to the bathroom to figuring out and engaging with areas with severe bathroom deserts. By bathroom deserts, I mean floors or sometimes even whole buildings that do not offer a gender-inclusive facility, which are usually single-stalled rooms with appropriate signage (a toilet, no reference to “men” or “women” at all). This was a more compelling juxtaposition, since I still remember in my freshman year (circa fall 2019), I didn’t see any gender-inclusive bathrooms – they were all gendered.
This inaction extends further than CMU’s slow transition to better bathrooms; as acts of vandalism still occur (according to my friends even so far as last semester in the Gates Hillman Centers, and last year in Maggie Mo) against gender-inclusive signage. So this project transformed into a campus-wide search for both gendered and gender-inclusive restrooms.
To do this, I borrowed a GoPro HERO9 Black from SoA’s lending center as well as a GoPro harness. I then looked to an online interactive map of CMU’s campus which pointed out areas with single-stall gender-inclusive facilities (compiled by the All-Gender Restroom Access Committee, not really CMU). I wanted to search for locations + experiences I could see any student frequenting + having, like studying in the library, waiting in a classroom, going to a football game, or eating at a dining hall. So by looking both for common experiences + bathroom deserts, this project culminated in 8 total experiences, displayed in a 3 channel format, of me walking to and from bathrooms around campus.
While this project was less technical/computer based than my previous projects (which is a success in my book, since I needed to get my ass away from my computer, according to some), the process was just as long and stressful. There were many points during this project I got lost in the buildings on campus. Inclusive bathrooms were tucked away behind office suite doors, wood shops with chainlink fences, some even in different buildings altogether. I tried to faithfully find these bathrooms by following two rules.
- If there exists a bathroom in the same building as the one you are in currently (according to the map), seek out that restroom. Try to use elevators and ramps, but if there are stairs, note that there are stairs.
- If there does not exist a bathroom in the same building, try to find the closest bathroom (according to the map), and seek out that restroom.
- and keep looking for that bathroom until you find it.
I added in a half humorous/half jarring voiceover which reflected my thoughts while walking, reflecting both my anxiety in trying to find the bathroom but also the helplessness and ridiculousness of the paths I had to take, when all I wanted was to take a piss. A video in particular is a powerful medium because I can show my experience in real time. This is the actual time it took for me to find this bathroom. Now imagine if I really needed to go and watch the video again.
Takeaways:
Overall, I think I was successful with this project given my time constraints (stemming from personal circumstances which led to me missing three weeks of school). Time was not on my side during the production of this project, which in a way was communicated to my classmates during my critique on Sept 29.
I failed in terms of metrics. I initially wanted a pedometer to measure my steps taken, and perhaps a heartbeat monitor to measure my heart rate (I know for a fact it was higher trying to find the single-stall restrooms). A Map detailing the routes I took might have also been nice, but given the time constraints, I reduced this project to just the experience.
I’d do this project again with more time. There’s so many more bathroom deserts than just the 8 I recorded here, and so many metrics I could have added to enhance the experience of watching it.
Hunt Library
300 South Craig Street
Gates Hillman Centers
Doherty Hall
Baker/Porter Hall
Wean Hall
Resnik Food Hall
Gesling Stadium
friendlygrape – TypologyMachineProposal
My new project is examining bathroom deserts around campus. I will do so using a GoPro to recording my experience walking to and from the bathroom.
_____________old idea_________________
For my project I want to fine tune stable diffusion to output images in the style of common agricultural pests. I will then curate a collection of digital “pests” out of mundane prompts like “using the phone while talking to a person” and create an educational video about these pests (+generative video based on these images using the many tools available online like melobytes which I haven’t checked if it is legit but something similar) similar to something you’d find on national geographic kids or pbs kids from the early 2000s or before.
I am mainly inspired by these educational films from the mid 50s and 60s for the educational video aspect. In terms of the fine tuning, I am inspired by the recent fine tuning of stable diffusion on pokemon characters so that even unrelated prompts like “donald trump” are skewed towards this cartoonish art style.
After a little research into stable diffusion and realizing that I will need to spend money to train such a model, I am also looking at alternatives such as a recent addition called textual inversion, which is able to make unique tokens for stable diffusion for the purposes to customizing and/or debiasing the outputs of prompts.
friendlygrape – Reading-1
To be honest, I am not familiar with photographic techniques at all, so the discussion about the dry vs. wet collodion, variations in emulsions, kinds of plates, were all very new to me. I think these are all very cool processes to read about, but I think I would benefit to a video of some sort which explains this process with more imagery. One thing that I found particularly interesting, was the fact that you could expose a plate multiple times (might be silly but I really had no idea!).
I personally think there’s an artistic opportunity to be had in X-Ray technology. I personally like how macabre skeletons look under an X-Ray and I see some potential for humor, especially considering it has mainly medical connotations. I also like the idea of scientific representations of creatures being used with an artistic purpose. There’s also this underlying expectation to illustration and imaging in medicine and biology that whatever you are portraying is supposed to depict something from real life. I think playing around with that expectation, maybe by creating some fictional monsters that are X-rayed, or plants that do not and could never exist, but positing them as real, is very interesting.
friendlygrape – looking outwards
“Artificial Arboretum,” by Jacqueline Wu, is an academic-mimicking documentation of images of trees (“photogrammetrees”) that are captured on platforms like Google Earth (though Wu mentions Apple Maps as an alternative).
I think one thing that is particularly compelling about this piece is that these trees are digital “replicas” of trees found in real life, but are nothing like actual trees due to the way they were captured. These trees are also documented in a scientific way, listing the species and location, but more interestingly, size, status, and date accessed, which suggests a new form of species identification in the realm of online universes (and that perhaps digital species will live separate from their real life counterparts). There’s also a slight comical effect in seeing these short stubby little trees in a virtual space (XD).
I found the documentation surrounding this project to be lacking, and I think I wanted some more discussion from the artist about what exactly makes the photogrammetrees trees (even though they don’t look like tree trees). The artist has tagged this project as ongoing so I am interested in seeing how this is carried forward.

Website: https://cargocollective.com/jacqswu/Artificial-Arboretum