Trigger warnings! Violence. Karens. Dead people. Hurt dogs. Racism.
During street protests in 2020, the police behaved especially erratically: their motorcycle gangs lurked out of sight, then would pounce without warning. They would snatch protestors into unmarked white vans. They would demand we move out of the roadway and into Mellon park, and then claim the park was closed, and pepper spray us and arrest us for trespass.
I began to listen to police radio while at the protests, to predict the police so as to protect the most precarious among us. For example, my international student friends couldn’t afford to be arrested, for fear of them being deported. So we’d hopefully have a heads up with a pounce was imminent. I also heard them make fun of our protest and its cause: Black lives.
***
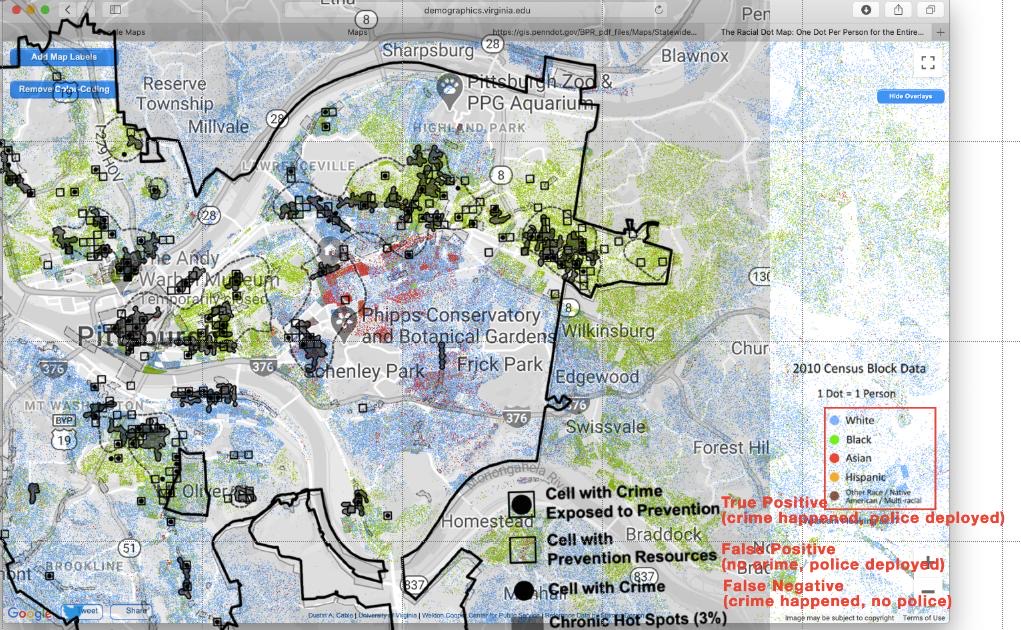
Carnegie Mellon partnered with the Pittsburgh Police to develop and deploy predictive policing software, using racist historical “crime” statistics to predict future crime. This was used to send police into “hotspot” disproportionately Black neighborhoods. After outcry, CMU claimed that the algorithm did not consider race as a factor, not fooling our history students who will tell you that racist laws lead to residential segregation, and our machine learning students who will tell you that therefore, under the blind eyes of machine learning, location is race .
***
So I built a system to record police scanner audio, used machine learning to transcribe it, and built a system to allow you to automatically search keywords and extract associated audio clips. I then fought with OpenAI’s Whisper to transcribe this – this is where most of my time was spent.
***
November 20th, 2022 was a cold day. At 8:25AM, it was about 20F, and fairly windy. I pressed the button to begin recording – and left it alone for 13 hours and 24 minutes.
****
06:18:55 – 06:19:00 “There’s no description of the male other than him being a black male.”
I wanted to know how police hear and speak about people. Predominantly and entirely unsurprisingly, individuals are collapsed into a gender and race description:
white: Black: total Male: 8 9 95 Female: 1 5 81 total: 38 43
Read all transcript snippets containing white, Black, male, or female here.
***
But also the more benign: dogs?
We hear about lost dogs, found dogs, threatening dogs, and threatened dogs. Read all dog transcript snippets here.
***
But like many beholders of algorithmic systems with a wealth of imperfect data, I struggle to know what meaning to intuit from it. Therefore, instead of presenting this as a finished piece, my canvas on which the last brush stroke has been cast, this is much more humble: a tool, for two people to make meaning together. This collaborative process is also in response to talking with Kyle McDonald, who suggested this become a tool for others to use, rather than a medium for a particularly situated “artist”.
I draw upon the feminist theorist Donna Haraway, and her notion of Situated Knowledges. Instead of attempting to assert a “view from nowhere”, instead: “feminist objectivity means quite simply [speaking from our] situated knowledges“. The result is knowledge that is “partial, locatable, critical” and much more honest than the once and for all facts declared in positivist science.
Under this tradition of ML, it makes sense to approach this as an epistemologically interpretive process – a far cry from the unwitting positivism of implied by the machine learning papers I read – and expect meaning to emerge through intersubjectivity. This then becomes an interactive, collaborative art piece, for people to make meaning together. This allows “located accountability” in technology production, that is, it allows us to be be known as the source of our knowledge claims, allows a discursive process to unfold, instead of presenting evident “truth” or “reality”.
***
How to use this:
- Press CMD+F, and search for a term.
- Click the link in the “Link” column
- Leave an anonymous comment. What does the snippet mean to you? What situated knowledge leaves you
- Respond to another’s comment. What intersubjectivity do you share? What don’t you?