This project was such a great learning experience for me even though it didn’t turn out how I expected. I made two master max patches; one involving all of the steps for receiving and sending information to the serial port of the arduino and one for transforming information received into a legible signal full of various oscillators. The idea remained the same from the initial writeup of identifying key parts of the voice and decomposing them into various signals able to be sent out to a synthesizer.
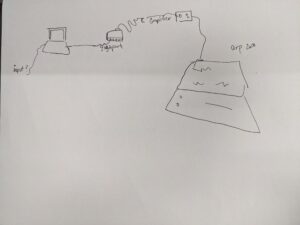
The initial idea – have the ability to talk to or sing with the synth to control its output. I wanted to do this using CV or control voltage. By sending the Arp 2600 (synthesizer) a signal between zero and five volts the synth can respond almost immediately to whatever input I send that to.

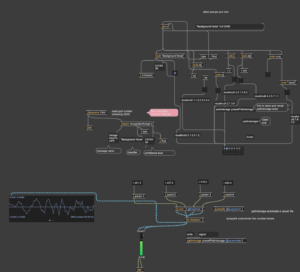
The first thing is translating information from my microphone into digital information that can be further processed. I decided to go with using the teachable machine route and training a model on my voice to give interactivity but also a classifier to go by. However, teachable machine cannot be loaded into max given some package compatibility issues. So, with Golan’s help I was able to take my teachable machine and load it into a p5 sketch, then send the information (classifier and confidence level of the sound) to a bridge (node.js) over osc to receive all of this information and convert it in any way I find fit using max msp.
In my first patch, the idea was to send out a series of notes, similar to a sequencer once a sound was identified, but I only got so far as to send out a different sound depending on the confidence of the sound as a result of the arduino having issues receiving data.
But first the signals have to be converted to a format that the synth can read. The synth can receive digital signals that aren’t cv data, but they can’t control the arp in the same way. I wanted to use a combination of both to have a sort of consistency in the way they worked together. Kind of like one of the oscillators being part of the voice signal and the rest of the quality information being used to control the pitch or envelope of the sound. The littlebits have a cv bit that allow me to simply send the littlebits arduino a signal between 0 and 255 and then convert those numbers to cv data.
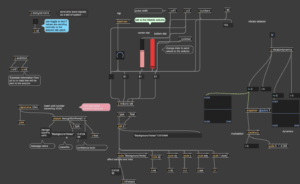
The edited patch instead of going to the arduino is sent to various preset oscillators and changes sound depending on the classifier it is given.
Both patches together are shown below
Below I have some video documentation of how things work: