Creating 3d Scans using a Flatbed Scanner

This project uses the optical properties of a flatbed scanner to generate normal maps of flat objects, and (eventually) 3d models of them.
I leverage heavily from this paper:
Using the work of Skala, Vaclav & Pan, Rongjiang & Nedved, Ondrej. (2014). Making 3D Replicas Using a Flatbed Scanner and a 3D Printer. 10.1007/978-3-319-09153-2_6.
Background:
tldr : this sucked, but opened up an opportunity
This project is a result of a hurdle from my Penny Space project for the typology assignment for this class. In scanning 1000 pennies, I encountered the problem where the same penny, if scanned from different orientations, results in a different image. This resulted in having to manually align all 1089 pennies, but this project explores why this behavior occurs and how it can be harnessed

Why does this behavior occur?
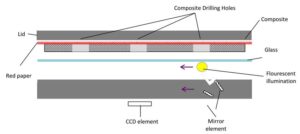
flatbed scanners provide a linear source of light. This is sufficient for photographic flat objects, but when scanning objects with contours, contours perpendicular to the direction of the light will appear dimmer, whereas parallel ones will appear brightness due to reflection. This means we can use brightness data to approximate the angle the surface is oriented, and use that to reconstruct a 3d surface.

Pipeline:
4x 2d scans -> scans are aligned -> extract brightness values at each pixel of 4 orientations -> compute normal vector at each pixel -> surface reconstruction from normal vector
More Detail:
Scanning:




Object is taped to a registration pattern and scanned at 90 degree increments, than aligned with one another via control points on the registration pattern
Brightness Extraction
Images are converted to grayscale to extract the brightness value at each pixel.
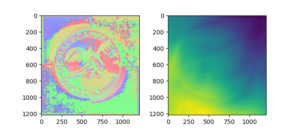
Normal Reconstruction
A bunch of math.
Surface Reconstruction
A bunch more math.
Initial Results


Improved Results
After finding some mathematical issues + fixing type errors in my implementation, here is a better normal map:


and associated obj:

What’s Next?
Possible Refinements:
Add filtering of brightness and / or normal vectors
4x 2d scans
-> scans are aligned
-> extract brightness values at each pixel of 4 orientations
-> PROCESS SIGNAL
-> compute normal vector at each pixel
-> PROCESS SIGNAL
-> surface reconstruction from normal vector