This project uses a pressure touch pad under a sheet of paper to detect the location of a marble on top of that sheet of paper. The coordinates of the marble are then sent to my Axidraw which moves (while drawing a line) directly to the marble. As the pen held by the Axidraw is attempting to go to exactly where the marble is, this attempt will knock the marble away, leading to the whole sequence repeating itself.
Over time, this makes the Axidraw chase the ball around the touch pad, all the while making a record of the approximate path that the marble takes.
Most of my documentation is on my website but I will try to summarize a bit of it here.
Radiance fields are a (somewhat) newer type of 3D representation. Gaussian splats and NeRFs are view-dependent representations of real life objects, meaning that the image rendered relies of what POV the camera is positioned in. This makes these radiance fields ideal for objects that are reflective, transparent, or translucent, A.K.A. dead things in jars.
For this final project, I mainly worked on coordinating with the Carnegie Museum of Natural History to capture their specimen and make new splats. This is my last attempt at using Postshot. I changed the way I captured the specimen, by using stagnant lighting and videoing around the target. However, moving forward, it would make the most sense to me to using the aruco targets to establish a ground truth and fix the results from the sfm algorithm. There are parts of the draco video and most apparent in other frogs video where you can see that the point clouds are misaligned between different angles. This seems to be a pretty consistent issue, likely due to various artifacts (or lack thereof) in the glass. To combat this, I will be using the code from the original paper and nerfstudio to generate the splats, to have more control over the sfm.
I’m pretty excited to see where this project continues to go. I’ve met so many interesting people (from PhD students to people who’ve worked at Pixar) via talking about this project at our final exhibition or at a poster session. Rest assured, at some point next semester, I will be making a website of pickled things.
This project uses the optical properties of a flatbed scanner to generate normal maps of flat objects, and (eventually) 3d models of them.
I leverage heavily from this paper:
Using the work of Skala, Vaclav & Pan, Rongjiang & Nedved, Ondrej. (2014). Making 3D Replicas Using a Flatbed Scanner and a 3D Printer. 10.1007/978-3-319-09153-2_6.
This project is a result of a hurdle from my Penny Space project for the typology assignment for this class. In scanning 1000 pennies, I encountered the problem where the same penny, if scanned from different orientations, results in a different image. This resulted in having to manually align all 1089 pennies, but this project explores why this behavior occurs and how it can be harnessed
Why does this behavior occur?
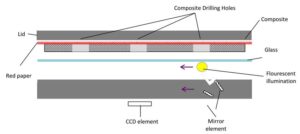
flatbed scanners provide a linear source of light. This is sufficient for photographic flat objects, but when scanning objects with contours, contours perpendicular to the direction of the light will appear dimmer, whereas parallel ones will appear brightness due to reflection. This means we can use brightness data to approximate the angle the surface is oriented, and use that to reconstruct a 3d surface.
Pipeline:
4x 2d scans
-> scans are aligned
-> extract brightness values at each pixel of 4 orientations
-> compute normal vector at each pixel
-> surface reconstruction from normal vector
More Detail:
Scanning:
Object is taped to a registration pattern and scanned at 90 degree increments, than aligned with one another via control points on the registration pattern
Brightness Extraction
Images are converted to grayscale to extract the brightness value at each pixel.
Normal Reconstruction
A bunch of math.
Surface Reconstruction
A bunch more math.
Initial Results
Improved Results
After finding some mathematical issues + fixing type errors in my implementation, here is a better normal map:
and associated obj:
What’s Next?
Possible Refinements:
Add filtering of brightness and / or normal vectors
4x 2d scans
-> scans are aligned
-> extract brightness values at each pixel of 4 orientations
-> PROCESS SIGNAL
-> compute normal vector at each pixel
-> PROCESS SIGNAL
-> surface reconstruction from normal vector
This project was such a great learning experience for me even though it didn’t turn out how I expected. I made two master max patches; one involving all of the steps for receiving and sending information to the serial port of the arduino and one for transforming information received into a legible signal full of various oscillators. The idea remained the same from the initial writeup of identifying key parts of the voice and decomposing them into various signals able to be sent out to a synthesizer.
The initial idea – have the ability to talk to or sing with the synth to control its output. I wanted to do this using CV or control voltage. By sending the Arp 2600 (synthesizer) a signal between zero and five volts the synth can respond almost immediately to whatever input I send that to.
The first thing is translating information from my microphone into digital information that can be further processed. I decided to go with using the teachable machine route and training a model on my voice to give interactivity but also a classifier to go by. However, teachable machine cannot be loaded into max given some package compatibility issues. So, with Golan’s help I was able to take my teachable machine and load it into a p5 sketch, then send the information (classifier and confidence level of the sound) to a bridge (node.js) over osc to receive all of this information and convert it in any way I find fit using max msp.
In my first patch, the idea was to send out a series of notes, similar to a sequencer once a sound was identified, but I only got so far as to send out a different sound depending on the confidence of the sound as a result of the arduino having issues receiving data.
But first the signals have to be converted to a format that the synth can read. The synth can receive digital signals that aren’t cv data, but they can’t control the arp in the same way. I wanted to use a combination of both to have a sort of consistency in the way they worked together. Kind of like one of the oscillators being part of the voice signal and the rest of the quality information being used to control the pitch or envelope of the sound. The littlebits have a cv bit that allow me to simply send the littlebits arduino a signal between 0 and 255 and then convert those numbers to cv data.
The edited patch instead of going to the arduino is sent to various preset oscillators and changes sound depending on the classifier it is given.
Both patches together are shown below
Below I have some video documentation of how things work:
Welcome to my final project post – it’s so sad that the class is coming to an end.
Since I experimented with two projects for the final output, I’ll be walking through Identity Collections (the original aim, capturing faces) first.
Inspiration
After creating two projects focused on surveillance where I was merely the observer putting myself in these situations to capture the invasive, I wanted to push myself and the piece I was making. I wanted to incorporate projection and interaction to make the viewer directly engage with the work, where they are forced to think about the implications of their own face being used or kept within a collection, and how they feel about that idea.
The questions I really wanted to investigate/answer were:
How would people react if their face or identity was captured in a way that blurred the boundaries of consent?
Would the invasive nature of this act stay with them afterward, influencing their thoughts or feelings?
Would they reflect on the ethical implications of image capture and its invasive presence in everyday life?
Brainstorming Concept
The concept drastically changed throughout the semester.
I’ve always had this idea of manipulating people’s faces in real time that would manipulate their mouth to speak. This is technically my idea for senior capstone/studio, but I wanted to see if something could get up and running in the class to capture faces in real time. After lots of really valuable conversations with Golan and Nica, we came to the following conclusions:
1. There is a strong possibility that it just wont work: I won’t get the reaction that I’m looking for, and I may experience a lot of difficulties that I didn’t ask for both backlash from the viewer and/or technical difficulties.
2. It is possible to make it work, reverse projection would be key, but it is beyond my current technical limit especially with the time we have left. I didn’t know Touch Designer well before we started off.
So we changed it, and after talking with Golan, he had an interesting idea about collecting faces in a terrarium like way:
I loved this idea of collection, moving it the faces to one place to another, so to test my technical skills while also capturing faces, the essence of the capture. I set off to capture the faces dynamically into a grid, and felt the terranium level would be the next level of the project if I could get there.
Concept
I’m severely interested in using the viewer as the entity, to further their interaction and engagement directly into the performance. I aimed to use facial capture software using Touch Designer in real time to create a visual experience that allowed viewers to directly interact with the captured collection of faces, extracted from viewers that came before them. I wanted to incorporate projection and interaction to make the viewer directly engage with the work, where they are forced to think about the implications of their own face being used or kept within a collection, and how they feel about that idea.
The questions I really wanted to investigate/answer were:
How would people react if their face or identity was captured in a way that blurred the boundaries of consent?
Would the invasive nature of this act stay with them afterward, influencing their thoughts or feelings?
Would they reflect on the ethical implications of image capture and its invasive presence in everyday life?
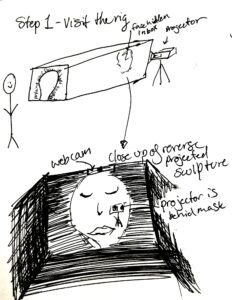
Capture System
I played around with what the rig would look like – shoutout Nica for saving the wooden box, and thank you Kelly for donating the wooden box to my cause (along with the wood glue, thank you <3 )
STEP 1 – Visit the rig (Wooden Box)
The idea with this step was the initial step that forces the viewer to choose: do you want to interact or not, and if you do, there’s a slight price that comes with it. Meaning on the outside of the box where the face is, I could write out the words “putting your face in this hole means you give consent to have your face captured and kept” (in need of more eloquent wording, but you get the picture). This was an element Nica & I talked about often, and I loved the subtlety of the words outside of the box.
Recent Find: In my senior studio, I actually had a live stream feed into the piece I was working on and I wrote “say Hi to the Camera”. Most people were completely fine with looking into the camera to see themselves in the piece, however 2 or 3 out of the 45 that came to visit, were adamant about NOT having themselves on screen. Once they were assured it wasn’t actually recording, they looked at the camera and viewed the piece for themselves
TLDR: I think most people would stick their head in?…
STEP 2 – Touch Designer does it’s thing!
more in-depth info in challenges
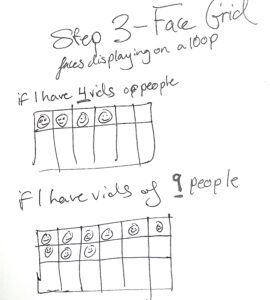
STEP 3 – Projected Face Grid – Dynamically updates!
Now here’s where I’ll talk about Touch Designer in depth.
The piece needed to complete the following:
Capture a video in real time using an HDMI Webcam!
Capture the video on cue, I decided to use a Toggle Button, meaning I am manually tapping record
Video uploads in unique suffix to a folder on my desktop (person1, person2, etc)
Touch Designer could read ALL the files in order on my desktop AND could read the most updated file
Grid dynamically changes regarding how many videos there are!!!!!!! (rows/cols change)
Most recent video is read and viewed in the Table COMP
Video within the grids play on a loop and don’t stop even when the grid changes dynamically
Now 1-5 were completed as seen in the video! But 6-7were insanely aggravating.
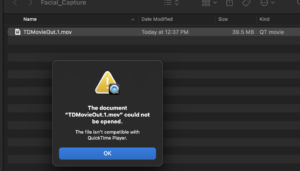
The biggest problem was that I should have gone to the PC earlier when I first saw the challenge in taking the recording using the Mac.
TLDR: TD was recording in Apple ProRes, but it wasn’t reading the recording when I needed to upload it back into the grid.
When I first encountered the first challenge of recording on Touch Designer and uploading the video to the desktop, I talked with M (thank you M), and we changed the recording of the video from H.264 to Apple ProRes (the only video that could be recorded using a Mac). So at this point, we got the *recording* of the video to work and upload to the desktop. I thought we’d be fine!
Nope!
I had the TD code working, and used Select DAT to read the most recent file in the Facial_Capture folder, and would use Movie In CHOP to read the video and upload it into the Table COMP. But Touch Designer writes that it was “Warning: Failed to Open File” when using Apple Pro Res.
Turns out, Touch Designer needs to be able to encode and decode the recording and there are some idk license complications with Apple, which makes it SO difficult.
SO I tried to record with NotchLC & Hap/HapQ, but even though they download to desktop, the files with the recordings in them DON’T OPEN OR READ!!!!!! They also just won’t be read in TD.
This brought the question of could I export the file manually to an MP4 or a better file version and then send it back in to TD. Nope. This also somewhat defeats the purpose of real time.
Then, I found out that the newest version of Touch Designer SHOULD be able to encode/decode using Apple Pro Res, but then I realized I am on the newest version of Touch Designer. The following article seems like it needs Apple Silicon to work? I don’t feel like that’d be such a big impact, but it just may be because the article states it works with the Apple Silicon chip.
“On macOS, both the Movie File In TOP and Movie File Out TOP have the additional benefit of supporting hardware decoding (depending on the Mac’s hardware). This means that Mac users will be able to take full advantage of Apple Silicon’s media engine for encoding and decoding.3” https://interactiveimmersive.io/blog/outputs/apple-prores-codec-in-touchdesigner/
Anywho, these are just the glimmers of the tech difficulties, but the most solvable reason is that I just needed to test and play with a PC. I was so focused on getting the code to work before I switched over to a PC, and looking back I think I was looking at the steps a little to methodically, and should have played/experimented with the PC from the beginning. Now I need a PC and will borrow one from Bob for the entirety of next semester so I won’t have this problem again. Even though it was a pain, I am pretty confident about my ways around Touch Designer now which is quite exciting that I achieved part of the goal on this assignment.
Outcome & Next Steps
As for the design/materials for the rest of the rig, I have everything:
Kelly’s box , black felt, paint, sharpie (rig)
transparent mask, the frosted spray paint (Reverse projection)
mini projector, webcam, tripod stands, extension cords (electronics)
I’m excited to play around with this next semester and see what can come about, since I’m hoping to present something similar at Senior Studio. I’m pretty confident I can get it to work knowing what I know now. Hopefully I can get more technical and explore more interactive works.
Now let’s move on to what was actually presented…
Printed Impressions.
I wanted to make sure I showed something at the final exhibition, and went back to edit my second project.
How does the sequence of the printing process vary between individuals, and to what extent are students aware of the subtle surveillance from a nearby individual when completing their routine actions?
What event did I choose to capture? Why this subject?
I chose to capture Carnegie Mellon students who are printing out assignments, surveilling their behaviors and habits in this mundane yet quick routine. After a lot of trial and error, I realized the simplicity of observing individuals in this sequence of entering the print station, scanning their card, waiting, foot-taping, and either taking the time to organize p or leaving their account open—creates an impression of each person over time and reveals subtle aspects of their attention to their surroundings, details, and visual signals of stress over time.
I chose this particular subject because not many people would be aware of subtle surveillance when doing such a mundane task, I thought it could also probe more of a reaction, but to my surprise, most people were unaware of my intentions.
What were the project updates?
The biggest takeaway I heard from the critiques were to “extract more of the absurdities,” meaning how could I zero in on what made the people interesting as they printed. Did they fidget? How did they move? How did they interact with the printer? Were they anxious? Calm? Were they quick/fast? Were they curious as to why I was in the space? I really loved the concepts simplicity on something so mundane and was interested to see just how different people were.
Here were some comments that stood out to me:
“Key question: do people print their documents in different ways? Is there something unique about the way people do such a banal thing? It’s been said that “the way you do anything is the way you do everything”. Did you find this to be true during these observations? ”
“I’m glad that you found such a wonderfully banal context in which to make discoveries about people. (I’m serious!) Be sure to reference things like Kyle McDonald’s “exhausting a crowd”, the Georges Perec “An Attempt at Exhausting a Place in Paris”. ”
“I agree that it is hard, like Golan said, to extract information and the interesting bits out of the videos themselves. Maybe what Kim did using voice overs with the Schenley project or subtitles, stalking(?) observations, anthropological notes? But I wonder what more can come out of the project and how can discussions of surveillance and privacy begin from what’s been captured. ”
“I admire you for being a dedicated observer, but I wonder if the privacy issues of this project have been discussed.”
“The collection of people is so interesting because I think I know like 2-3 of them. I think your presence still effects the results and how these people act.”
Video Reasoning
When I went to revise, I realized I had to make them more focused on the act themselves, so I revised the videos to see the similarities within each piece. Did they print the same, similar fidgeting, similar actions of looking at the paper, similarities in looking back to see what I was doing there. I reorganized the videos, but I was actually having a lot of trouble with how to organize them, or if I was doing the project injustice by stitching them all together in this way. My biggest question was how could I show just how powerful these little moments are, how can I help guide the viewer to see what they need to focus on. That thought translated into finding the similarities. I thought about the narration, but was unsure how to write in this format of videos stitched together that I thought it’d be a bit confusing, which is why I didn’t take that route.
Outcome & Next Steps
After talking with Golan, we agreed that the piece wasn’t strong just as a visual video and actually fell flat because the viewers just couldn’t understand what was happening. They needed clear guidance which translated into the need for an audio narration or captions that narrated what was going on. He also explained that it was perfectly fine to focus on each video instead of stiching the moments all together, literally creating a typography of videos accompanied with the narrating captions/audio. I really like this collected idea, and want to focus on it for my next revision. I think the stitching together in this way takes away from the magic of the creep cam and the work. In order to truly focus on the piece, I need to emphasize each video and person.
CMU Soul Keepers helped me appreciate the landscape maintenance work and also made me realize that no one knows the landscape as well as they do. No one has occupied every square foot of campus as completely as a maintenance worker, and you can see that in a composite image like the one of Steve below.
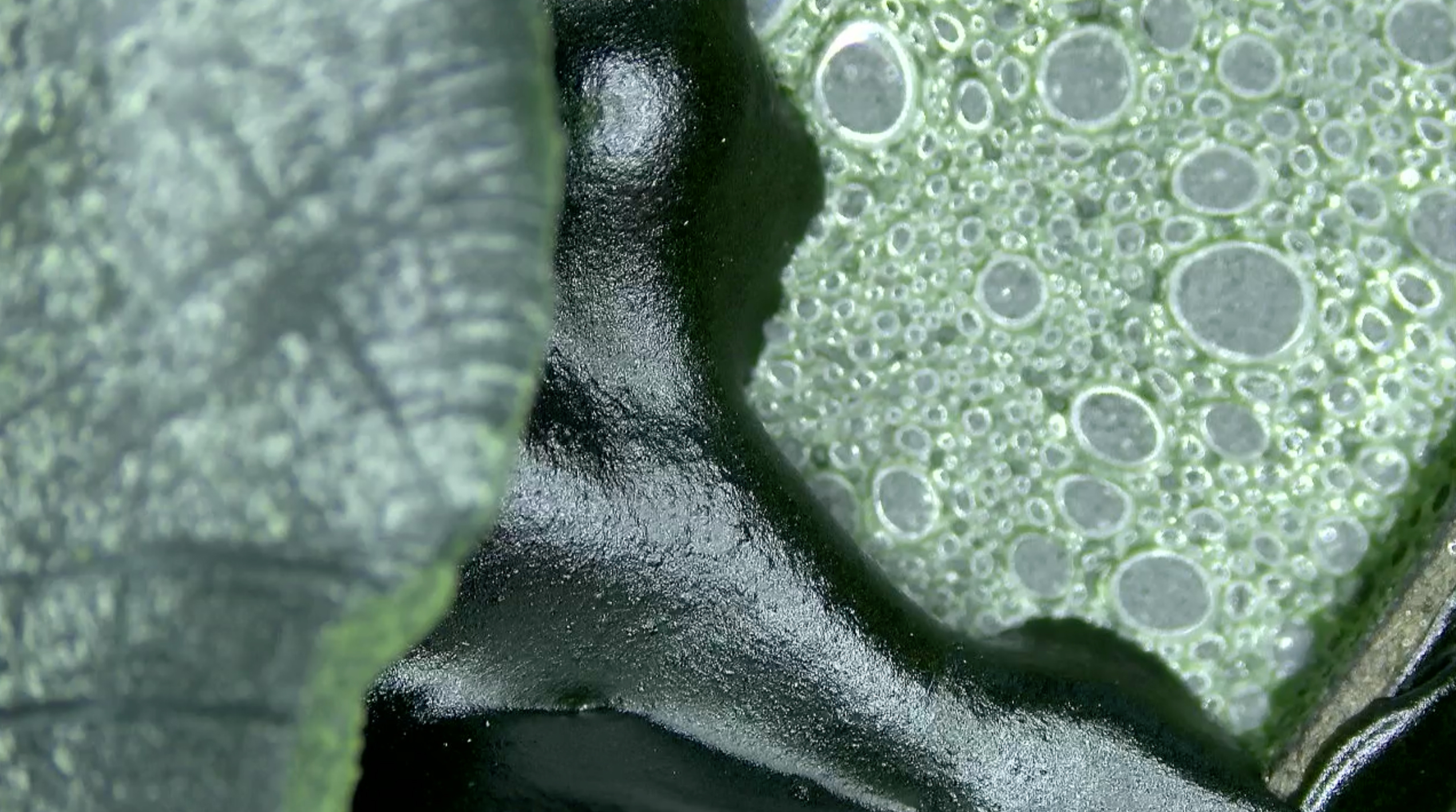
An Attempt At Exhausting a Park in Pittsburgh, is what I called my microscopy explorations over the semester because, since project 1, I’ve spent many hours observing and capturing parts of Schenley Park. The observations started when I was using the trail cam. Because I spent so much time in the park for project 1 (I was worried the camera would be stolen), and because I was trying to find and capture some mysterious phenomena, I began collecting small items from the park, like rocks, flowers, acorns, etc. After our spectroscope intro with Ginger, I became very excited about looking at almost anything under a microscope. For our final project exposition, I showed some of my favorite microscopic videos and stills.
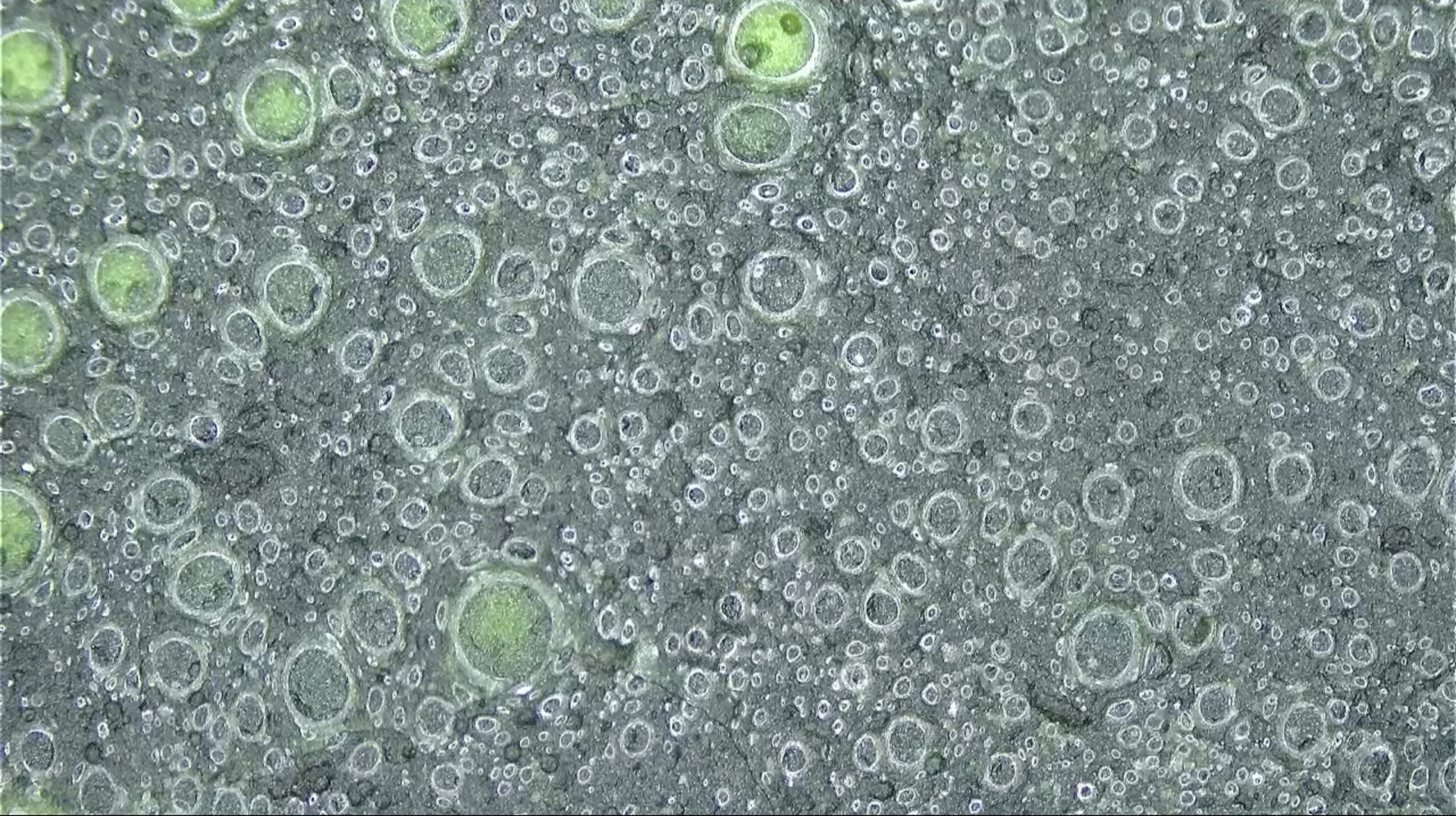
Algae Water from Panther Hollow LakeAlgae Water from Panther Hollow Lake
Pollen on a flower found in Schenley ParkPollen on a flower found in Schenley ParkZoomed out view of the pollinated flower
The shock of finding a bug on a leaf that was invisible to the naked eye really stunned me, it made me understand the leaf in a way I had never considered before, it became a whole landscape of its own, the world, or part of the world of this tiny bug. I needed to share this excitement, which is why when my boyfriend came to visit over fall break, I told him to come with me to Schenley Park and collect leaves, flowers, pond water/algae, and more so that we could look at it under the microscope. The recordings from my first video are all from that day. I would like to eventually show more people microscopic views of the world—I think it would be especially meaningful if they look at things they collect themselves—and record their reactions. As suggested, I do think it would be super fun to get a bunch of drunk people to record their observations of microscopic life. Perhaps in the spring, when life is reborn, I can try this again.
Bug found in a tiny patch of moss (tiny to me)
On a reference note… Early in the semester, when I was working on the first project, which involved using the trail cam in Schenley Park, Golan referenced Perec’s An Attempt At Exhausting a Place in Paris. Funny, I had just read the book over the summer, as well as Perec’s Species of Spaces, and was planning to try to do the same with a place in Pittsburgh. My training and professional work as a landscape architect made me obsessed with the idea of “sense of place,” which I think connects quite well the course concept of “quiddity.” Over the years, a lot of people have asked me what my “style” is as a landscape architect, and the best answer I can think of for that is: I don’t exactly have a style, because on each site, what I want to do is honor the place, honor the genius loci. If I have a style, it would be “honor the genius loci.” Anyway, I was trying to find new ways of “knowing” the landscape, of “exhausting” the landscape, of understanding “sense of place,” and through this class, especially through my microscopy studies, my idea of “place” totally shifted… perhaps we experience a sense of place at a human scale, but in each place, there are worlds within worlds.
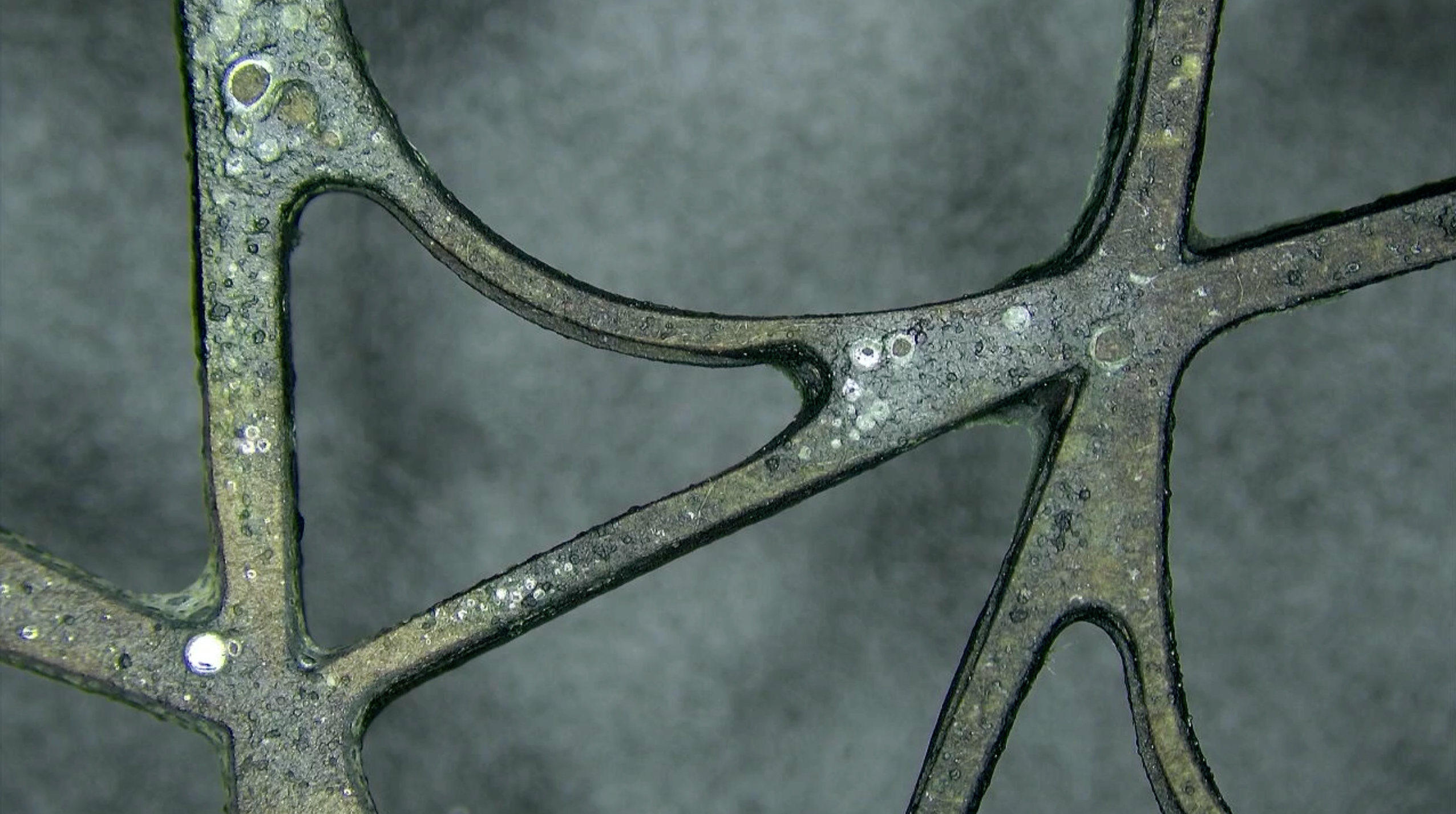
Also, for our final exhibition, I printed some of my favorite microscope images, which are of bioplastic samples I made for Dana Cupkova’s class. In a failed bioplastic experiment, my bioplastics grew very gross but cool-looking mold on them and I was super excited to look at the mold and the bioplastics under the microscope. I brought my friend Audrey to see it and she was super into it to –we made the bioplastics together.
Video Player
Media error: Format(s) not supported or source(s) not found
a mixture of bioplastic texturesa thin coat of spirulina over a piece of laser cut chipboarda thin coat of spirulina over a piece of laser cut chipboardAir dried spirulina bioplasticThe side of the bioplastic that dried against aluminum foilthe foil dried side looks like a satin textilethe rigid angular shape is a laser cut piece of chipboard I poured the spirulina bioplastic mixture on top of
I would have liked to have taken both of these projects further. Mario (orange-vested landscaper) did suggest I record him clearing the snow next semester. If things are not too crazy for me then… I’d like to make more time for the landscape maintenance documentation project. In the future, for me or someone else, it might be interesting or fun to recording different people doing different types of landscape maintenance in different places. Like how does the place influence the type of work that is done? How does the tool shape the work? And vice versa, how does the work shape the place? I imagine documenting landscape maintenance work in the parks, and I’d love to do more leaf-blowing captures since those are actually so satisfying to see. I know leaf blowing is not the best for ecosystem health… but it’s important for pedestrian for the sidewalks to be free of slippery leaves… everything is complex, right?
Really this class gave me a great appetite for exploration through experimental capture. For example, right now, I’m on a plane flying to Bolivia. I wish I had the trail cam with me. I wonder what kind of creatures I might be able to document with a trail cam in La Paz. I think of the speedy vizcachas you catch glimpses of, I think of all the street dogs, and of course the people. I really hope that someday I can have the time and the means to pursue these kinds of projects because doing them makes me feel so excited and overall happy.
a vizcacha I bet I could capture on a trail cam if I brought it to La PazA GIF I made from a video of my teleferico ride in La Paz, I used LICEcap to make this GIF, thanks for sharing this tool!
Insights:
At the beginning of this class I mentioned that I was interested and worried about tech addiction, my own, but also the screentime of those around me. I’m definitely not anti-tech, but I do think that my health or overall life-enjoyment would improve if I spent less time on screens. Using my phone for example, to explore and record things that were happening outside, feels like a positive use of the technology I often feel I use in an unhealthy way. (the real culprit, I think is social media).
It seems obvious now that I say it, but I think that there are ways of using technology that actually connect you to a place, or “nature.” For example, when we use a lens to augment our perception and expand our sense of what’s “real” or what’s there… this is to see something that is invisible to human eyes… for example, things that are too small, too slow, too fast, too large. Through this class I saw something that was too small for me to see (tiny bugs), but also things that were too slow for me to fully appreciate or understand otherwise (like landscape maintenance work).
Closing Thoughts:
I wish I had an ExCap class every semester. I’m hoping to pursue projects started in this class in the future, and I’ve also started a list of things I’m excited to try in the future thanks to this class:
+ Slow-motion video with the Edgertronic (I’ll be back!!!)
+ I want to try to capture soundwaves generated through wavefield synthesis (if possible) using the Edgertronic, a smart set-up, mirrors and lasers?
+ More video editing with a ChatGPT – FFMPEG pipeline (while looking through Sam’s Github!)
+ Tilt-Shift– I’ll try again.
+ Gaussian Splats– Lorie’s Dead Things In Jars was super cool and I want to try out the splats someday.
+ Axi-Draw– I didn’t even know Axi-draw existed before learning about Marc’s work. I definitely want to try it out sometime and I really appreciated Marc’s projects and questioning what is worth drawing via axi-draw instead of another means.
+ Touch Designer – Abby’s interactive display was very nice and is something I’d like to try sometime.
+ Eulerian Magnification – Cathleen’s body magnification videos are super interesting and I’d like to try it on people who are at the gym or something.
+ A typography of tree hollows, maybe 3D scans? Maybe videos? Idk but I’m sure something interesting is going on inside the tree hollows.
In the previous investigations via Eulerian Video Processing and ultrasound sensors, I saw the minute changes of my body–I saw how my pulse move and my heart beats with me completely unaware. It really felt as though the body is another creature separate from me.
So I wanted to further investigate the pulsing of the body and hear it, receiving information from it as though conversing with another entity.
Further Eulerian Works
Work using low ram computer, scale factor (similar to resolution to get better images) = 0.5 out of 1.
My Process:
Stabilize –> Magnify
Holding still is really hard! I used tracking stabilization to see if it makes a difference–for most videos, it did.
I then changed up the levels of all the parameters to see the differences they made. In the higher frequency ones you can see it moving really fast, which is still slightly confusing to me as my pulse normally doesn’t move that fast.
PARTS:
These are just all the parts I did, scroll through, though the ear is particularly interesting.
Parts that didn’t work well:
In these I felt that the image did not look great. I wanted to use a higher scale factor but:
My computer’s ram is far too low to support that. So I moved to the school’s computer.
New videos
These used the same videos but just better scale factor. It is interesting how as the scale factor moves up the exaggeratedness of the magnified movements goes down.
Myoware + hearing muscles
I tried so many wirings to make it work. It took me so long because I read that you should use an isolator for these sensors for them to work safely. I had the adafruit isolator and kept trying different setups with a pi so that the power goes through the isolator, but nothing worked.
culprit in question
So I ended up just not using an isolator. Fortunately (but also annoyingly), it worked fine :-(. I read through the sensor and max/msp reads a txt file to make these sounds according to the output.
I very wrongly used my final draft to write my final project text so this might look different from how I presented it.]=
I wanted to further investigate the pulsing of the body and hear it, receiving information from it as though conversing with another entity.
What didn’t work:
myoware
lytro
I felt that the image did not look great, wanted to use a higher scale factor but:
My computer’s ram is far too low to support that.
Further Eulerian Works
Work using low ram computer, scale factor (similar to resolution to get better images) = 0.5 out of 1.
My Process:
Stabilize –> Magnify
Holding still is really hard! I used tracking stabilization to see if it makes a difference–for most videos, it did.
I then changed up the levels of all the parameters to see the differences they made. In the higher frequency ones you can see it moving really fast, which is still slightly confusing to me as my pulse normally doesn’t move that fast.
These are just all the parts I did, scroll through, though the ear is particularly interesting.
At the beginning of the semester, I was more interested in the capturing system or more of the aesthetic of the final output. In these final projects, I grew more interested to the subject of what I was capturing.
During the Person-in-Time project, I wanted to capture the “moments” when I am with my college friends and represent it in a form that is memorable for me to reflect back on later.
My first iteration of this project was called, “Cooking in Concert”, where I recorded us cooking food together. Having lived with each other for two years and cooking countless meals together, my roommates and I naturally formulated cooking stations and drills. Through this project, I wanted to capture our working patterns and interaction within such a small closed space in an abstract representation.
After this project, I realized I wanted to integrate more spatial elements in the representation. Although I personally preferred this abstract visualization because I wanted to focus on our moving patterns and interactions, I received feedback that it felt too distant from my intention of capturing a wholesome moment with friends.
Therefore in my second iteration, I wanted to create a capture that closely replicates my memory of the moment. After our critique, I thought more about asking the question of what brings people together. And does this reason shape how you interact with each other?
Outcome
(I was absent during the actual event, so there is no other documentation.)
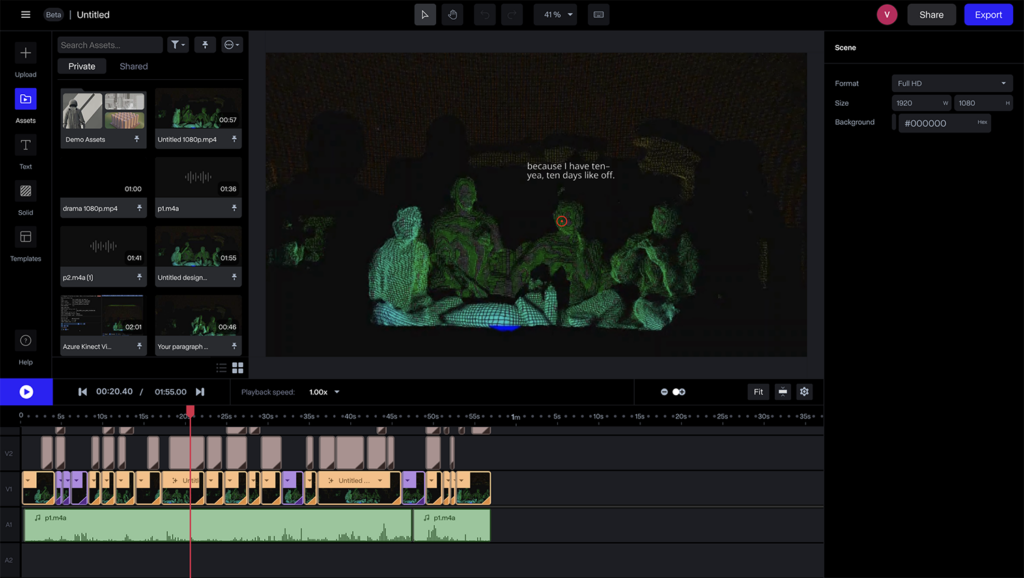
I really liked this point-cloud visual because it only had points facing the kinect camera. From the back, it looks like empty shells, which goes inline with how the light from the tv only lights up the front side of our bodies. I also liked how fragmented and shattered it looks because it represents how my memories also bound to come apart and have missing pieces here and there. In this iteration my focus was not necessarily on the movement but to capture the essence of the moment to observe us when we are all observing something else. To take note of some details or interaction that I do not remember because my memory is only a puzzle piece of the whole picture. This project got me to think about how people who share the moment have different perspectives of that same moment.
Capture “system”
With the Azure Kinect camera I spatially captured my interaction with my friends when we regularly meet every Saturday 7pm at our friend’s apartment to watch k-dramas together. The setting is very particular because we watch in the living room on the tv we hooked up the computer to and all four of us sit in a row on the futon while snacking.
I also set up a supplementary go-pro camera to time lapse our screening, in case the Kinect recording failed. Thankfully, it did not. Lastly, I also recorded our conversations during the screening on my computer. Then, as I explain later on, I use runwayml to transcribe the audio recording and motion tracking to integrate the dialogue component to the capture.
Challenges +Updates from last post
I was able to build the application for transformation_example with command lines on terminal, but even after running it, it did not properly output anything …
Therefore, I tried to use Touch Designer instead. Touch Designer worked great with live data, as my demo shows.
However, it can not read the depth data in the mkv files. From searching up similar cases to mine, only the Kinect Viewer can interpret the depth and RGB data so I would need to export it as a .ply before bringing it into Touch Designer or other programs.
I have tried other suggested methods like mkvtoolnix, etc, but they did not seem to work great either.
Therefore, I decided to focus more on integrating the dialogues into the scenes. I used runwayml to transcribe the audio to get the rough timeline.
Then, I edited parts that were interpreted incorrectly. Lastly, I used its motion tracking to attach the speech to each person.



















 were completed as seen in the video! But 6-7
were completed as seen in the video! But 6-7 were insanely aggravating.
were insanely aggravating.