I very wrongly used my final draft to write my final project text so this might look different from how I presented it.]=
I wanted to further investigate the pulsing of the body and hear it, receiving information from it as though conversing with another entity.
What didn’t work:
myoware
lytro
I felt that the image did not look great, wanted to use a higher scale factor but:
My computer’s ram is far too low to support that.
Further Eulerian Works
Work using low ram computer, scale factor (similar to resolution to get better images) = 0.5 out of 1.
My Process:
Stabilize –> Magnify
Holding still is really hard! I used tracking stabilization to see if it makes a difference–for most videos, it did.
I then changed up the levels of all the parameters to see the differences they made. In the higher frequency ones you can see it moving really fast, which is still slightly confusing to me as my pulse normally doesn’t move that fast.
These are just all the parts I did, scroll through, though the ear is particularly interesting.
Mic – computer – little bits (arduino + cv) – audio amplifier – arp
Inside the Computer: Teachable machine to p5.js to max msp out to the analog pipeline
Themes:
Dealing with Loss – Audio Degeneration
My concept is focusing on the idea of losing someone close to you for whatever reason and I want to make a performance out of this using the arp 2600. The digital (capture ) component of this is focusing on removing various phonemes from my voice in real time to either single out or remove completely the specified sounds.
First step– get the system working to use cv to send out different qualities of the signal as a cv to control the arp. This is working
Training using teachable machine – finding it’s quirks – consistency in volume I think vocal dynamics isn’t such a great way to train this model – prediction is that it becomes confused
Current headache – Max has odd syntax quirks that aren’t currently compatible with the arduino syntax <numbers>, however they definitely want to talk to each other.There is some conversion edit I have to make. When I send information i get an error which ends the process of sending the numbers, but I get a blink confirming that my setup is almost correct. – just found out / solved it !!!
Next steps – combining the teachable machine that is in p5.js(thanks golan), into max, then getting an output – transforming that output and hence sending it out to the arp. Performance (yay)
I aimed to explore capturing dance movements through a Motion Capture (Mocap) system, focusing on understanding its setup and workflow while creating an animation from the captured data.
Process
System Testing:
I used the Mocap Lab in the Hunt Library Basement. There are 10 motion capture cameras mounted to capture movement in the space.
Challenges and Adjustments:
Calibration was essential for accurate capture, involving a wand with sensors to determine the cameras’ locations.
Initial calibration was poor due to system neglect.
Solution: Adjusted camera positions to improve calibration.
Result: Calibration accuracy improved but hardware issues persisted, making complex motion capture difficult.
This project uses the optical properties of a flatbed scanner to generate normal maps of flat objects, and (eventually) 3d models of them.
I leverage heavily from this paper:
Using the work of Skala, Vaclav & Pan, Rongjiang & Nedved, Ondrej. (2014). Making 3D Replicas Using a Flatbed Scanner and a 3D Printer. 10.1007/978-3-319-09153-2_6.
This project is a result of a hurdle from my Penny Space project for the typology assignment for this class. In scanning 1000 pennies, I encountered the problem where the same penny, if scanned from different orientations, results in a different image. This resulted in having to manually align all 1089 pennies, but this project explores why this behavior occurs and how it can be harnessed
Why does this behavior occur?
flatbed scanners provide a linear source of light. This is sufficient for photographic flat objects, but when scanning objects with contours, contours perpendicular to the direction of the light will appear dimmer, whereas parallel ones will appear brightness due to reflection. This means we can use brightness data to approximate the angle the surface is oriented, and use that to reconstruct a 3d surface.
Pipeline:
4x 2d scans
-> scans are aligned
-> extract brightness values at each pixel of 4 orientations
-> compute normal vector at each pixel
-> surface reconstruction from normal vector
More Detail:
Scanning:
Object is taped to a registration pattern and scanned at 90 degree increments, than aligned with one another via control points on the registration pattern
Brightness Extraction
Images are converted to grayscale to extract the brightness value at each pixel.
resulting surface is at an angle, limiting resolution. This is (likely) an issue with my math…
Possible Refinements:
Add filtering of brightness and / or normal vectors
4x 2d scans
-> scans are aligned
-> extract brightness values at each pixel of 4 orientations
-> PROCESS SIGNAL
-> compute normal vector at each pixel
-> PROCESS SIGNAL
-> surface reconstruction from normal vector
Final ~Thing~ I want to make : web app to allow anyone to create 3d scans in this way! Coming soon.
Make a convincing narrative MV to the song Truisms 4 Dummies by Headache using a moving depth video.
I’ve been wanting to make something out of this song for a while, and I wanted to use the noisy output of a depth camera to convey an abstract narrative of the lyrics.
Inspo:
Faith Kim (2017) —Pittonkatonk festival immersive 3D project
I used the OAK-D Camera since it was compatible with my Mac and a Ronin S3 Mini gimbal for the most minimal setup/rig for capturing moving depth footage. Much of the work process was to get the technology to work. There weren’t too many ‘beginner-friendly’ resources out there with the OAK-D to TouchDesigner workflows but with help from A LOT of people (Nica, Alex, Kelly, Emmanuel,..) I got it to do the things. (Thank you)
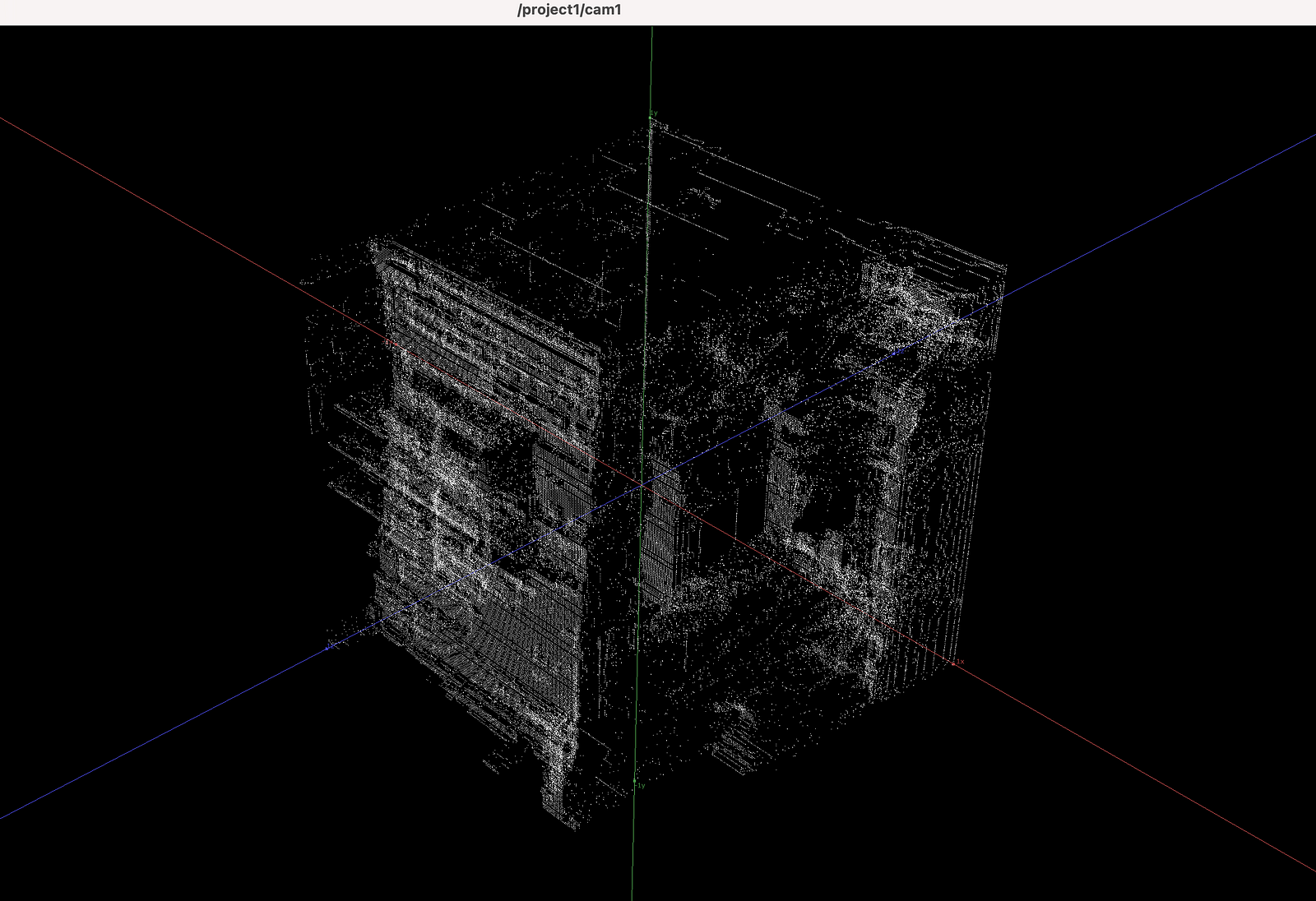
Direct Grayscale Depth Video Output
Touchdesignering….
TD takes data from the OAK camera (via a select operator) & Reorder TOP with vertical and horizontal ramps to map positions for instancing. This data flows to a Resolution TOP for formatting, then to a Null TOP, which passes it to a Geometry COMP (driven by a circle SOP and constant material) for instancing, and finally renders it to the screen.
How it looks with the gimbal setup.
Test vid of Lilian walking the walk
After getting the camera & rig to work successfully I went to shoot some clips for the song. Since the lyrics of the song are somewhat deep but also unserious, I thought matching those tones would be convincing.
Some test footage in different spaces:
Bathroom Mirror Find — Cubic space through angles of mirror reflection..
Theory: The OAK-D camera I used utilizes stereo vision algorithms (calculates depth by determining the disparity between corresponding points in the left and right images) instead of an infrared (IR) structured light system or Time-of-Flight (ToF) which uses the calculation of how light bounces off in space. So when it is placed where the mirror and the wall meet, it is still able to recognize the reflections and outputs it as another wall. (Could this be used to make virtual 3d space of mirrored spaces? mirrored realities? underwater? water reflections?)
Final Video (Final Video Featuring my friend Lucas)
I’m interested in illustrating facial collection in real time as a visual experience allowing viewers to interact with the captured collection of faces, extracted from viewers that came before them.
Attempted Output
STEP 1 – Visit the rig (Wooden Box)
STEP 2 – Touch Designer does it’s thing!
Touch Designer
Recording is OFF
Recording is ONMOVs saved to file!File names & Video Cells
STEP 3 – Projected Face Grid – Dynamically updates!
✅How to capture the video – Toggle Button, meaning I am manually tapping record *I cannot figure out automation, and this isn’t important to me in this iteration.
✅Video uploads in unique suffix to a folder on my desktop(person1, person2, etc)
✅Touch Designer can read ALL the files in order on my desktop
✅Grid dynamically changes regarding how many videos there are!!!!!!! (rows/cols change)
📍I NEED TD TO PULL THE VIDEO INTO THE TABLE COMP
📍PLAY THE VIDEO ON A LOOP!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
THEN I’M DONE!!!!!!
Next Steps
Fix the Rig ft. Kelly’s Wooden Box
Cut out the holes for the face
Cut out the holes for the reverse projection sculpture
Put black felt/paper inside so it’s super dark!
Write some words on the outside of the face hole of “you putting your face inside here means you consent to your video being saved” (smth more ethical and better worded)
Test Projection / Installation
Making sure everything is clear to the viewer the flow of the installation
Is it a surprise if they see other people’s faces on the screen???
Thank you Kelly you kind soul for donating your wood box – ILYYYYYYY <3
On the last episode of alice’s ExCap projects… I was playing around with stereo images while reflecting on the history of photography, the spectacle, stereoscopy and voyeurism, and “invisible” non-human labor and non-human physical/temporal scales and worlds. I was getting lost in ideas, so for this current iteration, I wanted to just focus on building the stereo macro capture pipeline I’ve been envisioning earlier (initially because I wanted to explore ways to bring us closer to non-human worlds* and then think about ways to subvert the way that we are gazing and capturing/extracting with our eyes… but I need more time to think about how to actually get that concept across :’)).
*e.g. these stereo videos made at a recent residency I was at (these are “fake stereo”) really spurred the exploration into stereo
Anyway… so in short, my goal for this draft was to achieve a setup for 360, stereoscopic, focus-stacked macro images using my test object, moss. At this point, I may have lost track a bit of the exact reasons for “why,” but I’ve been thinking so much about the ideas in previous projects that I wanted to just see if I can do this tech setup I’ve been thinking about for once and see where it takes me/what ideas it generates… At the very least, now I know I more or less have this tool at my disposal. I do have ideas about turning these images into collage landscapes (e.g. “trees” made of moss, “soil” made of skin) accompanied by soundscapes, playing around with glitches in focus-stacking, and “drawing” through Helicon’s focus stacking algorithm visualization (highlighting the hidden labor of algorithms in a way)… but anyway… here’s documentation of a working-ish pipeline for now.
Feedback request:
I would love to hear any thoughts on what images/what aspects of images in this set appeal to you!
STEP 1: Macro focus-stacking
Panning through focal lengths via pro video mode in Samsung Galaxy S22 Ultra default camera app using macro lens attachment
Stacked from 176 images. Method=C (S=4)
Focus stacked via HeliconFocus
Actually, I love seeing Helicon’s visualizations:
And when things “glitch” a little:
Stacked from 37 images. Method=A (R=8,S=4)
I took freehand photos of my dog’s eye at different focal lengths (despite being a very active dog, she mainly only moved her eyebrow and pupil here).
2. Stereo macro focus-stacked
Stereoscopic pair of focus-stacked images. I recommend viewing this by crossing your eyes. Change the zoom level so the images are smaller if you’re having trouble.
Red-Cyan Anaglyph of the focus-stacked image. This should be viewed via red-blue glasses.
3. 360 Stereo, macro, focus-stacked
Video Player
Media error: Format(s) not supported or source(s) not found
I would say this is an example of focus stacking working really well, because I positioned the object/camera relative to each other in a way that allowed me to capture useful information throughout the entire span of focal lengths allowed on my phone. This is more difficult when capturing 360 from a fixed viewpoint.
Setup:
Take stereo pairs of videos panning through different focal lengths, generating the stereo pair by scooting the camera left/right on the rail
Rotate turntable holding object and repeat. To reduce vibrations from manipulating the camera app on my phone, I controlled my phone via Vysor on my laptop.
Convert videos (74 total, 37 pairs) into folders of images (HeliconFocus cannot batch process videos)
Batch process focus stacking in HeliconFocus
Take all “focused” images and programmatically arrange into left/right focused stereo pairs
Likewise, programmatically or manually arrange into left/right focused anaglyphs
Overall, given that the cameral rail isn’t essential (mostly just used it to help with stereo pairs; the light isn’t really necessarily either given the right time of day), and functional phone macro lenses are fairly cheap, this was a pretty low-cost setup. I also want to eventually develop a more portable setup (which is why I wanted to work with my phone) to avoid having to extract things from nature. However, I might need to eventually transition away from a phone in order to capture a simultaneous stereo pair at macro scales (lenses need to be closer together than phones allow).
The problem of simultaneous stereo capture also remains.
Video Player
Media error: Format(s) not supported or source(s) not found
Focus-stacked stereo pairs stitched together. I recommend viewing this by crossing your eyes.
Focus-stacked red-blue anaglyphs stitched together. This needs to be viewed via the red-blue glasses.
The Next Steps:
I’m still interested in my original ideas around highlighting invisible non-human labor, so I’ll think about the possibilities of intersecting that with the work here. I think I’ll try to package this/add some conceptual layers on top of what’s here in order to create an approximately (hopefully?) 2-minute or so interactive experience for exhibition attendees.
Some sample explorations of close-up body capture
Video Player
Media error: Format(s) not supported or source(s) not found
I want to capture these memorable last moments with my college friends in a form where I can visit later on in the years when I want to reminisce.
I decided to document a representative “group activity” which is how me and my roommates move around and work together in our small kitchen by setting up a GoPro camera and observing our moving patterns.
I then recreated a 3d version of scene so that we can view the movements more immersively. I wanted to work with depth data in this next iteration of the project, so I used a Kinect this time.
Azure Kinect
Kinect is a device designed for computer vision that has depth sensing, RGB camera, and spatial audio capabilities.
My Demo
WHO
After my first iteration capture of a moment when we cook together, I wanted to choose another moment of interaction. With the Kinect I wanted to spatially capture my interaction with my friends when we regularly meet every Saturday 7pm at our friend’s apartment to watch k-dramas together. The setting is very particular because we watch in the living room on the tv we hooked up the computer to and all four of us sit in a row on the futon.
I was especially drawn to this 3D view of the capture and want to bring it into Unity so I could add additional properties like words from our conversation and who is addressing who and so on.
HOW
Now comes my struggle…:’)
I had recorded the capture in a file called mkv, which is a format that includes both depth and color data. In order to bring it into Unity to visualize this I would need to transform each frame of data as a ply, or point clouds.
I used this Point Cloud Player tool by keijiro to display the ply files in Unity. And I managed to get the example scene working with the given files.
However, I faced a lot of trouble converting the mkv recording into a folder of ply files. Initially, it just looked like this splash of points when I opened it in Blender.
After bringing it into MeshLab and playing with the colors and angles, I do see some form of face. However, the points weirdly collapse in the middle like we are being sucked out of space.
Nevertheless I still brought it into Unity, but the points are very faint and I could not quite tell if the points above are correctly displayed below.
Next Steps…
Find alternative methods to convert to ply files
Try to fix my current python code
Or, try this transformation_example on the Github (I am stuck trying to build the project using Visual Studio, so that I can actually run it)
This mixed reality experience uses a headset and a brain sensing headband to create an immersive before bedtime experience. While lying on a bed with the devices on, participants see a fence appear in front of them. In the augmented view, sheep jump over the fence, moving from one side of the bedroom to the other. The sheep’s movements are controlled by the participant’s brainwave patterns (from EEG data, which is a method to record an electrogram of the spontaneous electrical activity of the brain).
TP9 and TP10: Temporal Lobes & AF7 and AF8: Prefrontal Cortex
Currently I’m only dealing with values that has to do with their focus level (calculated based on mathematical relations between brainwaves). Users can also use blinking to count the sheep, though the blink detection values are still being fine tuned to improve accuracy.







 2 independent generations of lines
2 independent generations of lines
 Field
Field






















 Project Objective:
Project Objective: