I’m interested in illustrating facial collection in real time as a visual experience allowing viewers to interact with the captured collection of faces, extracted from viewers that came before them.
Attempted Output
STEP 1 – Visit the rig (Wooden Box)
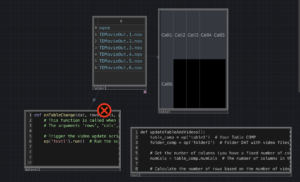
STEP 2 – Touch Designer does it’s thing!
Touch Designer
Recording is OFF
Recording is ONMOVs saved to file!File names & Video Cells
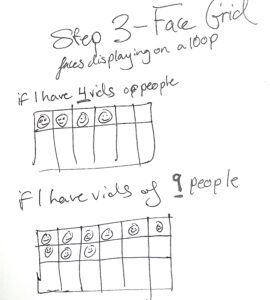
STEP 3 – Projected Face Grid – Dynamically updates!
How to capture the video – Toggle Button, meaning I am manually tapping record *I cannot figure out automation, and this isn’t important to me in this iteration.
Video uploads in unique suffix to a folder on my desktop(person1, person2, etc)
Touch Designer can read ALL the files in order on my desktop
Grid dynamically changes regarding how many videos there are!!!!!!! (rows/cols change)
I NEED TD TO PULL THE VIDEO INTO THE TABLE COMP
PLAY THE VIDEO ON A LOOP!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
THEN I’M DONE!!!!!!
Next Steps
Fix the Rig ft. Kelly’s Wooden Box
Cut out the holes for the face
Cut out the holes for the reverse projection sculpture
Put black felt/paper inside so it’s super dark!
Write some words on the outside of the face hole of “you putting your face inside here means you consent to your video being saved” (smth more ethical and better worded)
Test Projection / Installation
Making sure everything is clear to the viewer the flow of the installation
Is it a surprise if they see other people’s faces on the screen???
Thank you Kelly you kind soul for donating your wood box – ILYYYYYYY <3
On the last episode of alice’s ExCap projects… I was playing around with stereo images while reflecting on the history of photography, the spectacle, stereoscopy and voyeurism, and “invisible” non-human labor and non-human physical/temporal scales and worlds. I was getting lost in ideas, so for this current iteration, I wanted to just focus on building the stereo macro capture pipeline I’ve been envisioning earlier (initially because I wanted to explore ways to bring us closer to non-human worlds* and then think about ways to subvert the way that we are gazing and capturing/extracting with our eyes… but I need more time to think about how to actually get that concept across :’)).
*e.g. these stereo videos made at a recent residency I was at (these are “fake stereo”) really spurred the exploration into stereo
Anyway… so in short, my goal for this draft was to achieve a setup for 360, stereoscopic, focus-stacked macro images using my test object, moss. At this point, I may have lost track a bit of the exact reasons for “why,” but I’ve been thinking so much about the ideas in previous projects that I wanted to just see if I can do this tech setup I’ve been thinking about for once and see where it takes me/what ideas it generates… At the very least, now I know I more or less have this tool at my disposal. I do have ideas about turning these images into collage landscapes (e.g. “trees” made of moss, “soil” made of skin) accompanied by soundscapes, playing around with glitches in focus-stacking, and “drawing” through Helicon’s focus stacking algorithm visualization (highlighting the hidden labor of algorithms in a way)… but anyway… here’s documentation of a working-ish pipeline for now.
Feedback request:
I would love to hear any thoughts on what images/what aspects of images in this set appeal to you!
STEP 1: Macro focus-stacking
Panning through focal lengths via pro video mode in Samsung Galaxy S22 Ultra default camera app using macro lens attachment
Stacked from 176 images. Method=C (S=4)
Focus stacked via HeliconFocus
Actually, I love seeing Helicon’s visualizations:
And when things “glitch” a little:
Stacked from 37 images. Method=A (R=8,S=4)
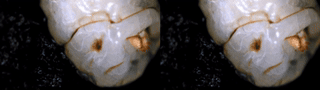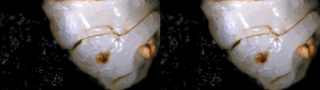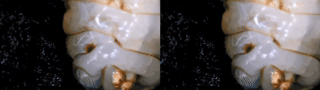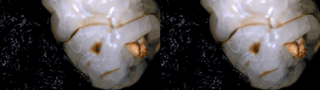
I took freehand photos of my dog’s eye at different focal lengths (despite being a very active dog, she mainly only moved her eyebrow and pupil here).
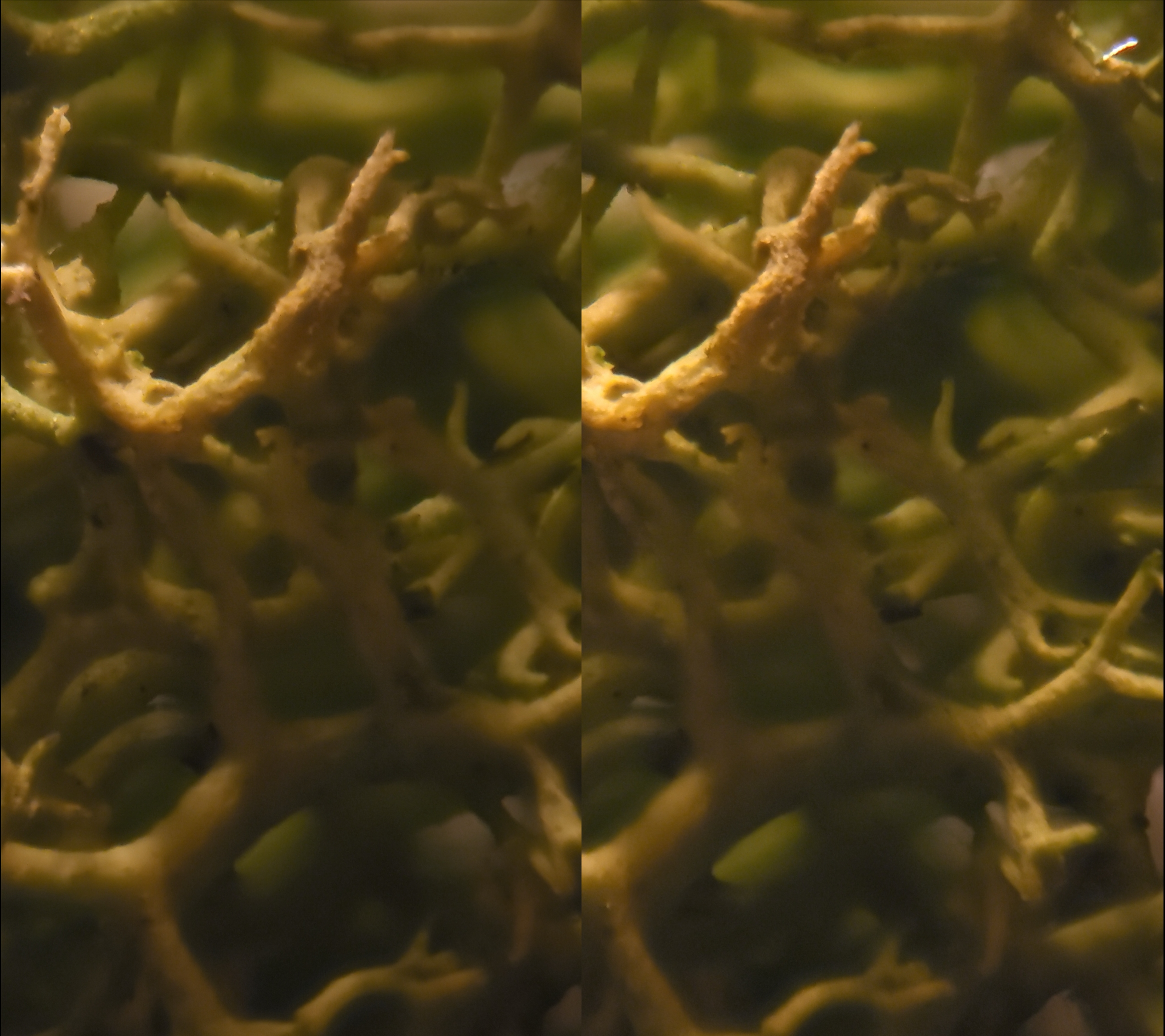
2. Stereo macro focus-stacked
Stereoscopic pair of focus-stacked images. I recommend viewing this by crossing your eyes. Change the zoom level so the images are smaller if you’re having trouble.
Red-Cyan Anaglyph of the focus-stacked image. This should be viewed via red-blue glasses.
3. 360 Stereo, macro, focus-stacked
Video Player
Media error: Format(s) not supported or source(s) not found
I would say this is an example of focus stacking working really well, because I positioned the object/camera relative to each other in a way that allowed me to capture useful information throughout the entire span of focal lengths allowed on my phone. This is more difficult when capturing 360 from a fixed viewpoint.
Setup:
Take stereo pairs of videos panning through different focal lengths, generating the stereo pair by scooting the camera left/right on the rail
Rotate turntable holding object and repeat. To reduce vibrations from manipulating the camera app on my phone, I controlled my phone via Vysor on my laptop.
Convert videos (74 total, 37 pairs) into folders of images (HeliconFocus cannot batch process videos)
Batch process focus stacking in HeliconFocus
Take all “focused” images and programmatically arrange into left/right focused stereo pairs
Likewise, programmatically or manually arrange into left/right focused anaglyphs
Overall, given that the cameral rail isn’t essential (mostly just used it to help with stereo pairs; the light isn’t really necessarily either given the right time of day), and functional phone macro lenses are fairly cheap, this was a pretty low-cost setup. I also want to eventually develop a more portable setup (which is why I wanted to work with my phone) to avoid having to extract things from nature. However, I might need to eventually transition away from a phone in order to capture a simultaneous stereo pair at macro scales (lenses need to be closer together than phones allow).
The problem of simultaneous stereo capture also remains.
Video Player
Media error: Format(s) not supported or source(s) not found
Focus-stacked stereo pairs stitched together. I recommend viewing this by crossing your eyes.
Focus-stacked red-blue anaglyphs stitched together. This needs to be viewed via the red-blue glasses.
The Next Steps:
I’m still interested in my original ideas around highlighting invisible non-human labor, so I’ll think about the possibilities of intersecting that with the work here. I think I’ll try to package this/add some conceptual layers on top of what’s here in order to create an approximately (hopefully?) 2-minute or so interactive experience for exhibition attendees.
Some sample explorations of close-up body capture
Video Player
Media error: Format(s) not supported or source(s) not found
I want to capture these memorable last moments with my college friends in a form where I can visit later on in the years when I want to reminisce.
I decided to document a representative “group activity” which is how me and my roommates move around and work together in our small kitchen by setting up a GoPro camera and observing our moving patterns.
I then recreated a 3d version of scene so that we can view the movements more immersively. I wanted to work with depth data in this next iteration of the project, so I used a Kinect this time.
Azure Kinect
Kinect is a device designed for computer vision that has depth sensing, RGB camera, and spatial audio capabilities.
My Demo
WHO
After my first iteration capture of a moment when we cook together, I wanted to choose another moment of interaction. With the Kinect I wanted to spatially capture my interaction with my friends when we regularly meet every Saturday 7pm at our friend’s apartment to watch k-dramas together. The setting is very particular because we watch in the living room on the tv we hooked up the computer to and all four of us sit in a row on the futon.
I was especially drawn to this 3D view of the capture and want to bring it into Unity so I could add additional properties like words from our conversation and who is addressing who and so on.
HOW
Now comes my struggle…:’)
I had recorded the capture in a file called mkv, which is a format that includes both depth and color data. In order to bring it into Unity to visualize this I would need to transform each frame of data as a ply, or point clouds.
I used this Point Cloud Player tool by keijiro to display the ply files in Unity. And I managed to get the example scene working with the given files.
However, I faced a lot of trouble converting the mkv recording into a folder of ply files. Initially, it just looked like this splash of points when I opened it in Blender.
After bringing it into MeshLab and playing with the colors and angles, I do see some form of face. However, the points weirdly collapse in the middle like we are being sucked out of space.
Nevertheless I still brought it into Unity, but the points are very faint and I could not quite tell if the points above are correctly displayed below.
Next Steps…
Find alternative methods to convert to ply files
Try to fix my current python code
Or, try this transformation_example on the Github (I am stuck trying to build the project using Visual Studio, so that I can actually run it)
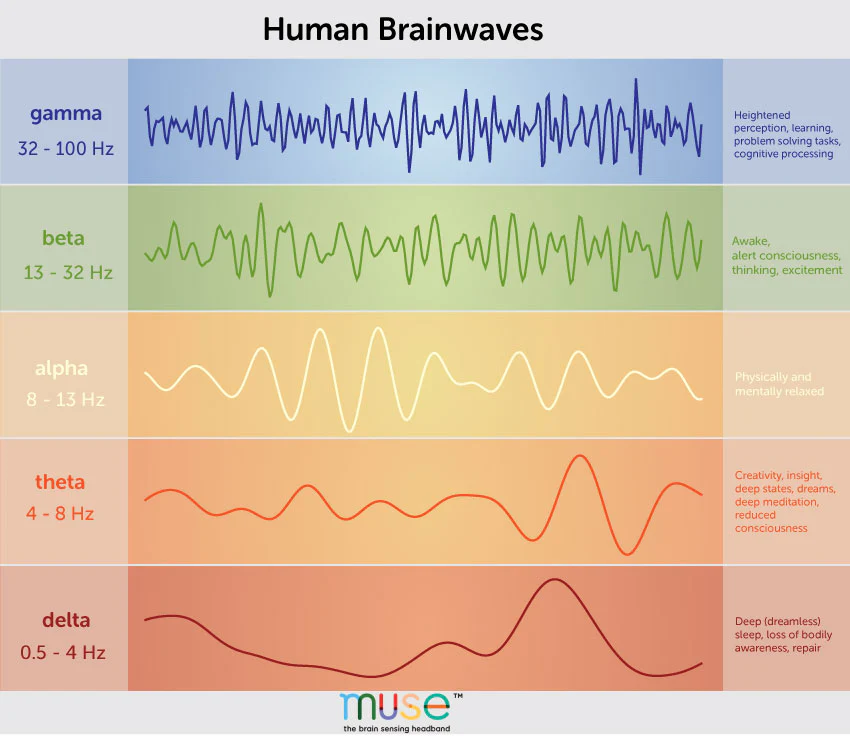
This mixed reality experience uses a headset and a brain sensing headband to create an immersive before bedtime experience. While lying on a bed with the devices on, participants see a fence appear in front of them. In the augmented view, sheep jump over the fence, moving from one side of the bedroom to the other. The sheep’s movements are controlled by the participant’s brainwave patterns (from EEG data, which is a method to record an electrogram of the spontaneous electrical activity of the brain).
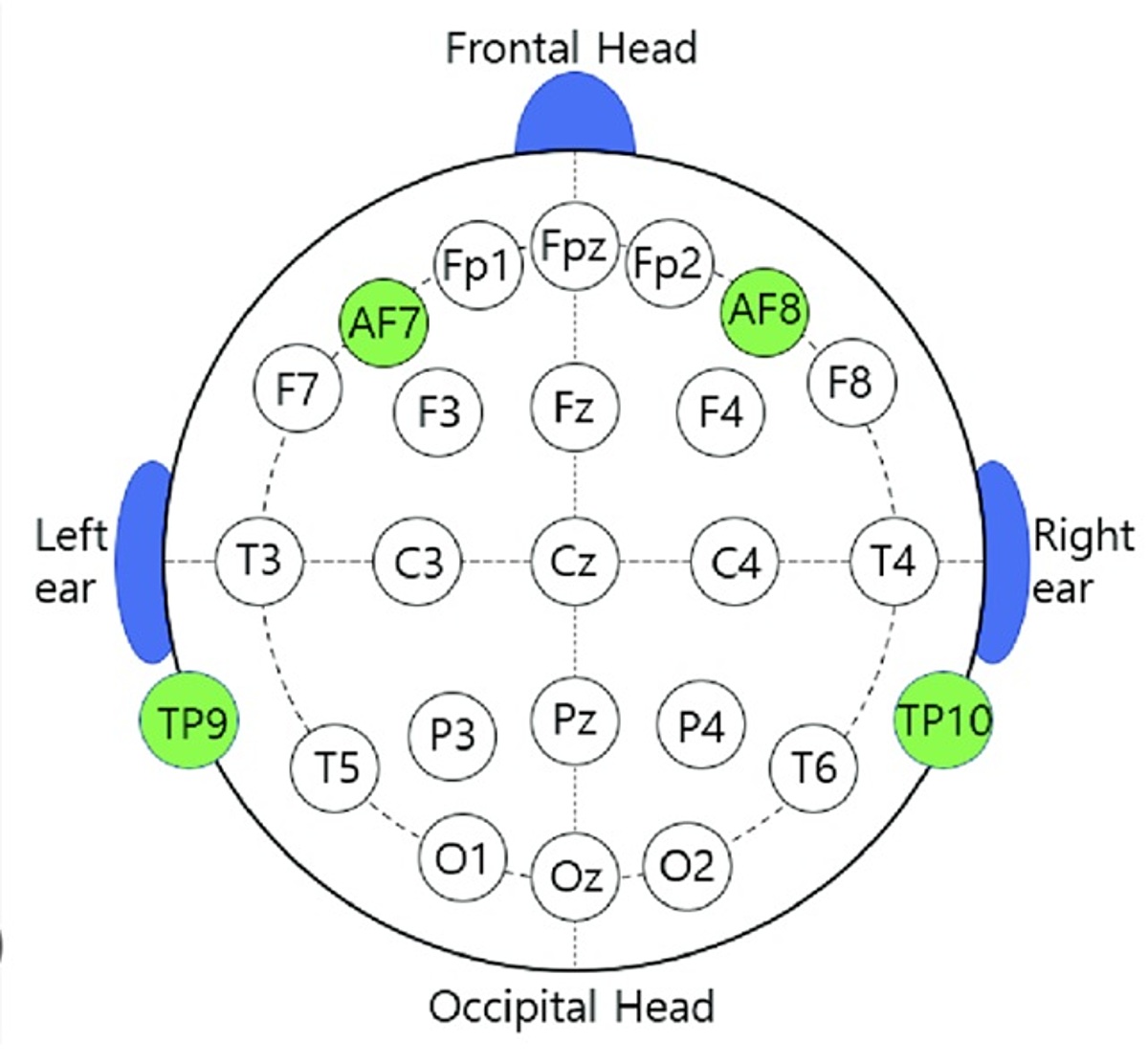
TP9 and TP10: Temporal Lobes & AF7 and AF8: Prefrontal Cortex
Currently I’m only dealing with values that has to do with their focus level (calculated based on mathematical relations between brainwaves). Users can also use blinking to count the sheep, though the blink detection values are still being fine tuned to improve accuracy.
In short, I captured the undersides of Pittsburgh’s worst bridges through photogrammetry. Here’s a few of the results.
For the final project, I wanted to revise and refine the presentation of my scans and also expand the collection with more bridges. Unfortunately, I spent too much time worrying about taking new captures/better captures that I didn’t focus as much as I should have on the final output, which I wanted to ideally be either augmented reality experience, or a 3d walkthrough in Unity. That being said, I do have a very rudimentary (emphasis on rudimentary) draft of the augmented reality experience.
(Youtube is insisting that this video be uploaded as a short so it won’t embed properly)
As I work towards next Friday, there’s a few things I’d like to still implement. For starters, I want to add some sort of text that pops up on each bridge that has some key facts about what you’re looking at. I also currently don’t have an easy “delete” button to remove a bridge in the UI, but I haven’t figured out how to do that yet. Lower on the priority list would be to get a few more bridge captures, but that’s less important than the app itself at this point. Finally, I cannot figure out why all the bridges are somewhat floating off the ground, so if anyone has any recommendations I’d love to hear them.
I’m also curious for feedback if this is the most interesting way to present the bridges. I really like how weird it is to see an entire bridge just like, floating in your world where the bridge doesn’t belong, but I’m open to trying something else if there’s a better way to do it. The other option I’m tossing around would be to try some sort of first person walkthrough in unity instead of augmented reality.
I just downloaded Unity on Monday and I think I’ve put in close to 20 hours trying to get this to work over 2.5 days… But after restarting 17 times I think I’ve started to get the hang of it. This is totally out of my scope of knowledge, so what would have been a fairly simple task became one of the most frustrating experiences of my semester. So further help with Unity would be very much appreciated, if anyone has the time!! If I see one more “build failed” error message, I might just throw my computer into the Monongahela. Either way, I’m proud of myself that I have a semi functioning app at all, because that’s not something I ever thought I’d be able to do.
Thanks for listening! Happy end of the semester!!!!
He makes these awesome full-room camera obscuras in his home and even hotel rooms.
I was particularly inspired by his terrain works, where he uses natural terrains and camera obscuras to mimic impressionist paintings.
This was motivated because I intend to use it in part of a longer-term project. Eventually, I want to get it to the level where I can record clear live videos through this.
This served as my first attempt at making a prototype.
I was given a fresnel lens with a focal length of 200mm but in my research, this would also work with a common magnifying glass. The only downside of this kind of substitution seemed to be that it would produce a less sharp image.
The basic setup is pretty basic, it’s essentially a box within a box with a piece of parchment paper attached to the end of the smaller box. The fresnel was attached with electrical tape and painter’s tape to a frame I had already made for another project.
Process:
During building the box, it was nighttime, so I played around using lights in the dark.
It was looking surprisingly ok.
I went ahead and finished a rough model.
Video Testing:
Further thoughts:
To expand, I want to get it to a better clarity and experiment with using different materials for the projection screen.
I saw this great video where they used frosted plastic and a portable scanner to extract the projected image, which I am super interested in pursuing.
The end goal is to have something I can run around town with and get reliable results, make content, and experiment with the form.
In this interactive digital art project, I explore the emotional and energetic effects of being observed versus being alone. Using Unity as the primary platform, I’ve created a digital “me”—Little Bosi—who resides within a 3D living space on a computer screen. Little Bosi reacts differently based on the presence or absence of an audience, offering a poignant reflection on isolation and human connection, inspired by my own experiences during the pandemic and its aftermath.
Concept
This project delves into the transformative power of attention. During the pandemic, I endured long periods of solitude, disconnected from people and outside signals. Weeks would pass without meaningful interactions, and sometimes I would go days without speaking a word. It felt as though I lived inside a box, cut off from the external world. During that time, my mental state was one of exhaustion and sadness.
The process of emerging from that state highlighted how every interaction and moment of attention from others created ripples in my internal world. A simple gaze or fleeting connection could shift my emotional energy. This concept inspired the idea for Little Bosi: an embodiment of these emotional dynamics and a visual representation of how being seen impacts the human spirit.
Interaction Mechanics
When Alone: Little Bosi enters an emotional down state, expressing sadness, boredom, and exhaustion. The digital character performs actions such as slouching, sighing, and moving lethargically. The world around Little Bosi gradually fades to a monochromatic tone, symbolizing emotional depletion.
When Observed:
When someone approaches the screen, Little Bosi transitions to an interactive state, showing joy and energy. Actions include smiling, waving, and sitting upright. The environment regains its vibrancy and color.
Techniques
3D Scanning: I used Polycam to scan 3D models of myself (Little Bosi) and my living room to create a digital space resembling my real-life environment.
Animation Development: The animation library was built using online motion assets, which were refined through IK rigging and manual keyframe adjustments. Transition animations were crafted to ensure smooth movement between emotional states.
Placeholders: For the current concept and testing phase, video placeholders are used to represent animations while final transitions are being completed in Unity’s Animator.
Interactive Coding: Unity’s OpenCV plugin powers the interaction system. Using the plugin’s object detection and face recognition models, the camera identifies the presence and position of individuals in front of the screen. This data triggers Little Bosi’s behavioral state:
Face Detected: Activates interactive state.
No Face Detected: Switches to solitude mode.
Reflection
The project aims to create a “living space” that bridges the digital and emotional realms. By using 3D modeling, animations, and environmental changes, I evoke the contrasting experiences of loneliness and connection. The audience becomes an integral part of the narrative; their presence or absence directly influences the digital world and Little Bosi’s emotional state. Through this work, I hope to resonate with audiences who may have faced similar feelings of loneliness, reminding them of the importance of connection and the subtle ways we leave traces in each other’s worlds.
Next Steps
Finalizing animation transitions in Unity’s Animator to seamlessly connect Little Bosi’s emotional states.
Enhancing the environmental effects to amplify the visual storytelling.
Expanding the interaction mechanics, possibly incorporating more complex gaze dynamics or multi-user scenarios.
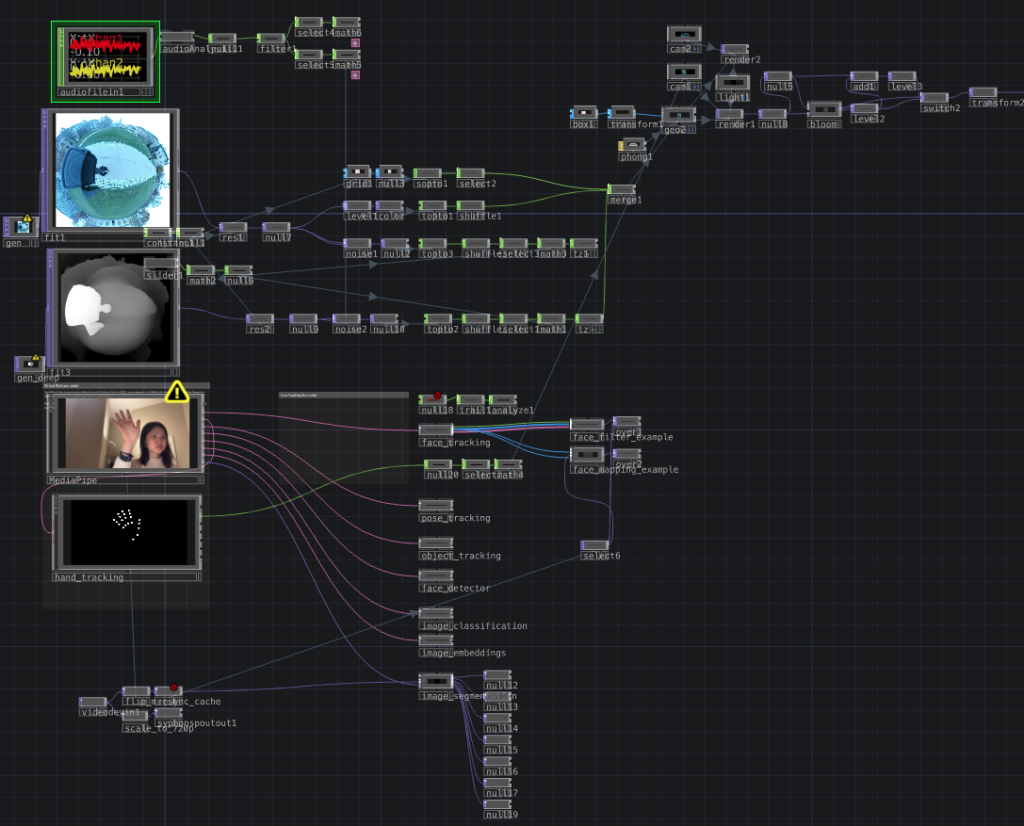
I seek to pixelate a flat, two-dimensional image in TouchDesigner and imbue it with three-dimensional depth. My inquiry begins with a simple question: how can I breathe spatial life into a static photograph?
The answer lies in crafting a depth map—a blueprint of the image’s spatial structure. By assigning each pixel a Z-axis offset proportional to its distance from the viewer, I can orchestrate a visual symphony where pixels farther from the camera drift deeper into the frame, creating a dynamic and evocative illusion of dimensionality.
Capture System
To align with my concept, I decided to capture a bird’s-eye view. This top-down perspective aligns with my vision, as it allows pixel movement to be restricted downward based on their distance from the camera. To achieve this, I used a 360° camera mounted on a selfie stick. On a sunny afternoon, I walked around my campus, holding the camera aloft. While the process drew some attention, it yielded the ideal footage for my project.
Challenges
Generating depth maps from 360° panoramic images proved to be a significant challenge. My initial plan was to use a stereo camera to capture left and right channel images, then apply OpenCV’s matrix algorithms to extract depth information from the stereo pair. However, when I fed the 360° panoramic images into OpenCV, the heavy distortion at the edges caused the computation to break down.
Moreover, using OpenCV to extract depth maps posed another inherent issue: the generated depth maps did not align perfectly with either the left or right channel color images, potentially causing inaccuracies in subsequent color-depth mapping in TouchDesigner.
Fortunately, I discovered a pre-trained AI model online Image Depth Map that could directly convert photos into depth maps and provided a JavaScript API. Since my source material was a video file, I developed the following workflow:
Extract frames from the video at 24 frames per second (fps).
Batch processes 3000 images through the Depth AI model to generate corresponding depth maps.
Reassemble the depth map sequence into a depth video at 24 fps.
This workflow enabled me to produce a depth video precisely aligned with the original color video.
Design
The next step was to integrate the depth video with the color video in TouchDesigner and enhance the sense of spatial motion along the Z-axis. I scaled both the original video and depth video to a resolution of 300×300. Using the depth map, I extracted the color channel values of each pixel, which represented the distance of each point from the camera. These values were mapped to the corresponding pixels in the color video, enabling them to move along the Z-axis. Pixels closer to the camera moved less, while those farther away moved more.
To enhance the visual experience, I incorporated dynamic effects synchronized with music rhythms. This created a striking spatial illusion. Observing how the 360° camera captured the Earth’s curvature, I had an idea: what if this could become an interactive medium? Could I make it so viewers could “touch” the Earth depicted in the video? To realize this, I integrated MediaPipe’s hand-tracking feature. In the final TouchDesigner setup, the inputs—audio stream, video stream, depth map stream, and real-time hand capture—are layered from top to bottom.
Outcome
The final result is an interactive “Earth” that moves to the rhythm of music. Users can interact with the virtual Earth through hand gestures, creating a dynamic and engaging experience.
Critical Thinking
Depth map generation was a key step in the entire project, thanks to the trained AI model that overcame the limitations of traditional computer vision methods.
I feel like the videos shot with the 360° camera are interesting in themselves, especially the selfie stick that formed a support that was always close to the lens in the frame, which was very realistic and accurately reflected in the depth map.
Although I considered using a drone to shoot a bird’s-eye view, the 360° camera allowed me to realize the interactive ideas in my design. Overall, the combination of tools and creativity provided inspiration for further artistic exploration.
When Ginger came to teach us spectroscopy, and we were asked to collect samples outside to look at under a microscope, I unexpectedly discovered a microscopic bug when looking at a leaf from outside (I could’t see it with my plain, human eyes). This made me curious about what else I was missing. Then, for my first project, I spent so much time in Schenley Park (I was trying to exhaust it- à la Perec). In how many ways could I get to know Schenley Park? What was interesting in it?
In October, I collected a bunch of samples (algae from Panther Hollow lake, flowers, twigs, rocks, leaves, etc.) and brought them to the studio to see what I could find in a deeper look. Below is a short video highlighting only a small portion of my micro explorations. A lot of oohs, ahh, and silliness.
Last week, Richard Pell told us about focus stacking! I wanted to try using this technique to make higher resolution images from some of my videos. While the images are not super high resolution because they are made from extracted video stills, you are still able to see more detail in one image with the stacking. I ran a bunch of my captures through heliconFocus to achieve this. Below are my focus stack experiments along with GIFs of the original footage to show the focus depth changing.
Focus Stacking Captures:
Pollinated Flower Petals.
Stacked from 30 images. Method=A (R=8,S=4)
Stacked from 30 images. Method=C (S=8)
Focus Stacking – Blue Flower
Stacked from 11 images. Method=A (R=8,S=4)
Stacked from 11 images. Method=C (S=4)
Focus Stacking – Dry Moss
Stacked from 31 images. Method=A (R=8,S=8)
Stacked from 31 images. Method=B (R=8,S=8)
Focus Stacking – Bugs on Flowers
Stacked from 148 images. Method=C (S=4)
Stacked from 148 images. Method=A (R=8,S=4)
You can see the movement of the bug over time like this!!
I also did this with a tiny bug I saw on this leaf, you can see its path.
depth map
Stacked from 51 images. Method=A (R=3,S=1)
Next, you can see some bugs moving around on this flower
Now Mold!
A single strand of moss
Stacked from 44 images. Method=A (R=10,S=5)
Stacked from 44 images. Method=B (R=10,S=7)
Stacked from 44 images. Method=C (S=7)
A flower bud
Stacked from 70 images. Method=C (S=6)
Stacked from 70 images. Method=A (R=10,S=5)
Stacked from 70 images. Method=B (R=10,S=5)
Having done these microscopic captures for fun in October and really enjoying this close-up look at things, and being so mesmerized by the bugs lives, I wanted to spend an extraordinary amount of time just looking at the same types of bugs found on Schenley organic matter for my final project. On November 25th, I set out again to collect a plethora of objects from Schenley Park- including flowers, strands of grass, twigs, acorns, stones, algae+water from the pond, charred wood and more… I eagerly brought them to studio… wondering what bugs I’d see. But of course, it had gotten cold. After an hours-long search under the microscope, I did find one bug. But by the time I found the bug, I was exhausted (and interested in other things).
In an Attempt at Exhausting A Park In Pittsburgh. (Schenley Park), I ended up exhausting myself.
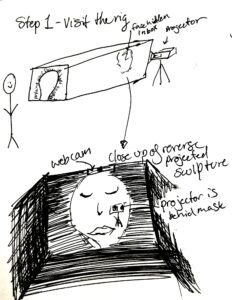


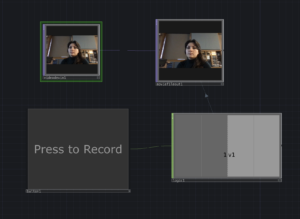
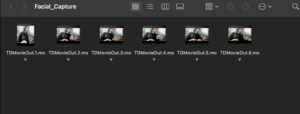

 How to capture the video in real time- Webcam!
How to capture the video in real time- Webcam! I NEED TD TO PULL THE VIDEO INTO THE TABLE COMP
I NEED TD TO PULL THE VIDEO INTO THE TABLE COMP