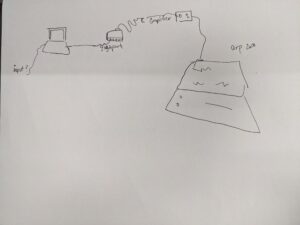
Basic idea:
Mapping and rearranging pixels of one image to form another.
Or, in the more ornate words of a friend based on a basic description of the project: “The machine projects the memory of the source image onto its perception of its incoming vision from the new image. Is it hallucinating? Or just trying to interpret the new stimuli in terms of past experiences?”
Questions:
- How much can an image’s constituent pixels be rearranged before it loses its original identity? Where/when does one thing end and another begin?
- Can the ways the pixels are changing reflect the different timelines on which different organisms and systems exist?
- Can Alice finish Project #2 for ExCap on time?

- (the answer is “yes?* but not to the desired effect”)
- *for some definition of yes
Inspiration:
Generally, I’m really inspired by media theoretical work from the likes of Hito Steyerl (e.g. poor image), Trevor Paglen (invisible image), Legacy Russell (Glitch Feminism), and Rosa Menkman (Glitch Manifesto). There are also definitely general inspirations from pixel sorting tradition.
Here’s a page out of Menkman’s Glitch Manifesto:

Three topics:
There were 2.5 topics through which I wanted to experiment (none of which I’ve been able to really flesh out yet):
1) Non-human labor of lichen and moss
1a) s1n0p1a x lichen/moss collaboration
2) the story of my friend/housemate Jane and me.

Non-human labor of lichen and moss:
My original idea around highlighting non-human labor: such as the enduring role of lichen and moss in restoring post-industrial landscapes and ways in which species persist alongside and in spite of human development. Lichen and moss are keystone species/genus that survived Earth’s last major extinctions. They grow slowly over decades, centuries, millenia–existing on a timeline that exceeds our understanding. For this stage/iteration of the project, I wanted to film 1) the bridge/trains/cars of Pittsburgh and 2) lichen and moss; our changes are intertwined. For the site, I chose to film at the Pump House, the site of the 1892 Battle of Homestead–one of the most pivotal and deadly labor struggles in American history.

Pump House
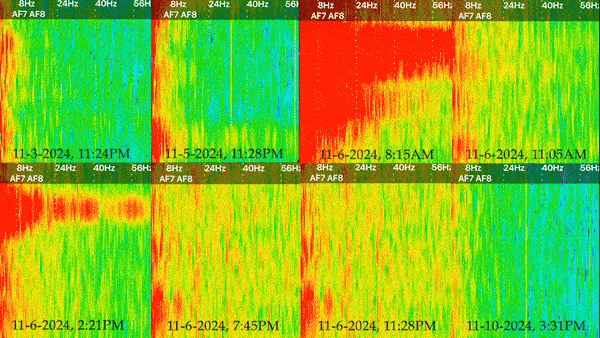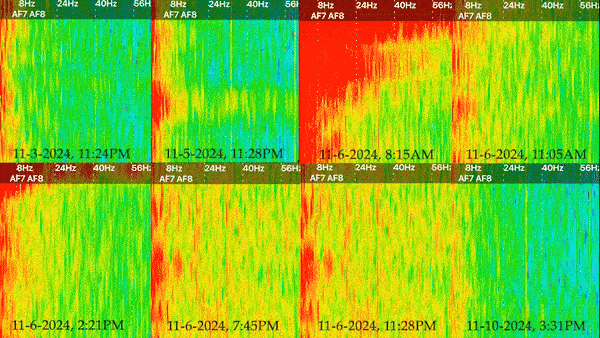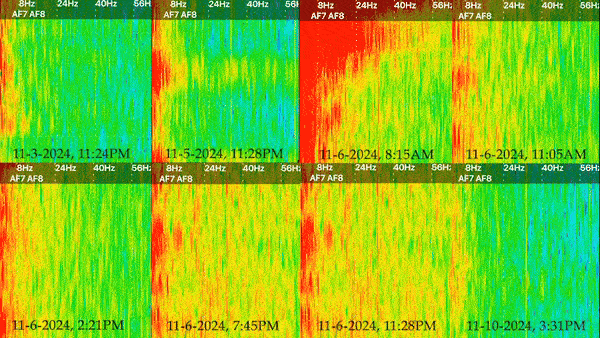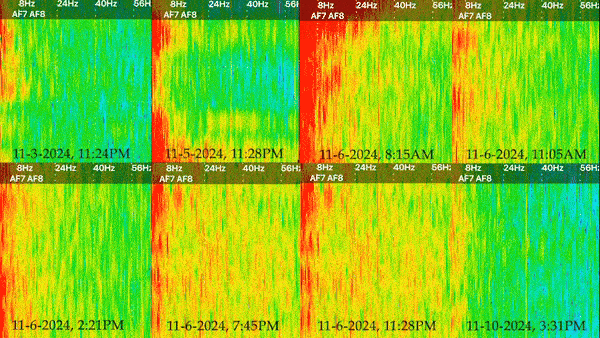
Pixels of Bridge Mapped to Pixels of Lichen:


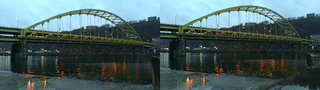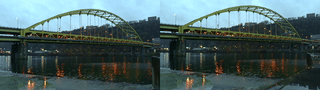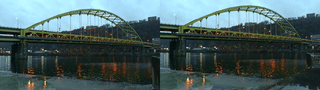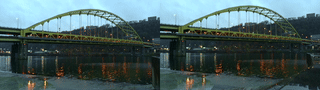
Collected video x Collected video:

Lichen on a rock next to the Pump House

Moss/lichen on the wall of the Pump House
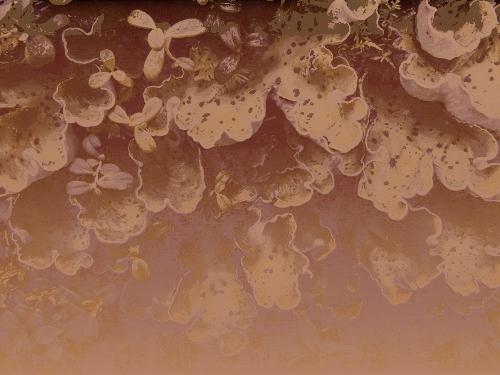
Collected video (I took this video) x Sample Image (I did not take these images):


stereoscopic!
I’m not too happy with the results on this one because the images just don’t… look too good? In future iterations I think I need to be more strategic with filming. I think part of it too was not being able to do stereo in macro out in the wild (but I’m trying to work on this! this seems like a good lead for future exploration).
- s1n0p1a x lichen/moss webshop: This idea ties back to the non-human labor of lichen and moss original idea. My original plan involved a webshop selling art (or experiences?) that highlighted non-human labor and attempted to collect fees to donate to environmental organizations. One pressing question was WHAT ART? Stereoscopy relates back to the spectacle, voyeurism, and the desire to own (e.g. curiosity cabinet) and clips/art for sale bring to mind pornographic/erotic content. An idea that came to mind was quite simply combining the two via pixel remapping. Does the Free Model Release Form apply here? Might be good on my end because I’m using nude photos of myself? Even though those pixels were shattered, why do I admittedly feel some reticence with using e.g. a photo of myself unclothed. Should the lichen consent to having their likeness represented in this way? I was intrigued by this kind of intimacy. Least progress was made on this idea, but are some sample image (1st and 3rd were images from online and second was an image I took myself, since I didn’t particularly like any of the macro/stereo lichen shots I took):


The story of my friend/housemate Jane and me: Often when I refer to Jane in conversation with others I call her my “housemate,” but I immediately feel the need to clarify that we’ve also been “friends since 6th grade.” As someone who identifies as aroace and constantly tries to rally against amatonormativity; I feel inept at capturing, in conversations with others, the meaningfulness of our longstanding friendship and the ways in which we live together–sharing meals and mutual support over the years. I wanted to honor a bit of that through this project. Over the years, we’ve changed in some ways, but in many ways we’ve stayed the same.




6th grade (Left: HSV, Right: Lab)

Lab w/ max_size 1024

8th grade Yosemite trip


Recent image together (L: lab on cropped image, R: HSV)
Algorithm:
Reconstruct one image (Image B) using the colors of another (Image A) via mapping pixels to their closest color match according to Lab, HSV, and RGB. (After some texts across images, I found I generally liked results from Lab the best.) Both images are downsized (largest dimension limited to max_size parameter) to reduce computational load. A KD-Tree is built for Image A’s pixels. Each pixel in Image B is then matched to the closest unused pixel in Image A based on color similarity; ideally, every pixel in Image A is used exactly once. It gets pretty computationally heavy at the moment and definitely forced me to think more about the construction, destruction, and general features of media.
Some analysis:
The runtime should be O(nlogn) for building the KDTree and O(m*n) for querying m pixels and iterating over n unused pixels for each query, leading to O(nlogn)+O(m*n).
I documented the results of a couple initial tests and found that for images from my phone setting max_size to
50 yields results in ~0.5s
100 yields results in ~6s
150 yields results in ~35s
200 yields results in about 1.25 minutes
50 was computationally somewhat feasible for generating a live output feed based on camera input. I found results start to look “good enough” at 150–though high resolution isn’t necessarily desirable because I wanted to preserve a “pixelated” look as a reminder of the constituent pixels. In the future, I’ll spend some time thinking about ways to speed this up to make higher resolution live video feed possible, though low res has its own charm 

Combinations I tried:
Image + Image
Image + Live Video
Image → Video (apply Image colors to Video)
Video frames → Image (map video frame colors to image in succession)
Video + Video
Future Work
Other than what has been detailed in each of the experiment subsections above, I want to generally think about boundaries/edge cases, use cases, inputs/outputs, and the design of the algorithm more to push the meaning generated by this process. For instance, I might consider ways to selectively prioritize certain parts of Image B during reconstruction