360 Ings (April 2020)
A 360° video performance of hectic and frisky actions and gestures overlapped in the domestic space.

The stay-at-home order has enabled the transfer of our outdoor activities and operations into the domestic space. What used to happen outside of our walls, now happens infinitely repeated in a continuous performance that contains each of our movements.
Return home indefinitely produces an unsettling sentiment of oddness. For some people, this return will affect identically to that man in by Chantal Akerman’s ‘Le déménagement,’ that stands bewildered to the asymmetry of his apartment. For me, it represents an infinite loop of actions that kept me in motion from one place to another. A perpetual suite of small happenings similar to the piano pieces that the composer Henri Cowell titled ‘Nine Ings’ in the early 20th century, all gerunds:
Floating
Frisking
Fleeting
Scooting
Wafting
Seething
Whisking
Sneaking
Swaying

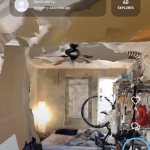
In ‘360 Ings’ those small gestures and their variations are recorded in the 360-degrees that a spherical camera can capture, isolated and cropped automatically with a machine learning algorithm, and edited all together to multiply the self of the enclosed living.
A 360 interactive version is available on Youtube.
Recording
I used the Xiaomi Mi Sphere 360 Camera which has a resolution of 3.5K video, and therefore the sizes of the video files were expected to be quite big. For that reason, I had to reduce the time of the performance under 5 min (approx. 4500 frames at 15fps). Time and space planning has been fundamental.
The footage provided is then remapped and stick into a panoramic image using the software provided by the company.
Background subtraction
After the recording process, I used a machine learning method to subtract the background of an image and produce an alpha matte channel with crisp but smooth edges to rotoscope myself in every frame. Trying many of these algorithms has been essential. This website provides a good collection of papers and contributions to this technique. Initially, I tried MaskRCNN and Detectron 2 to segment the image where a person was detected, but it did not return adequate results.

Deep Labelling for Semantic Image Segmentation (DeepLabV3) produces good results, but the edge of the object was not clear enough to rotoscope me in every frame. A second algorithm was needed to succeed in this task, and this is exactly what a group of researchers at University of Washington are currently working on. ‘Background Matting’ uses a deep network with and adversarial loss to predict a high-quality matte by judging the quality of the composite with a new background (in my case, that background was my empty living room). This method runs using Pytorch and Tensorflow with CUDA 10.0. For more instructions on how to use the code, here is the Github site (they are very helpful and quick responding).

Editing
With the new composite, I edited every single action on time and space using Premiere. The paths of my movements often cross and I had to cut and reorganize single actions into multiple layers.
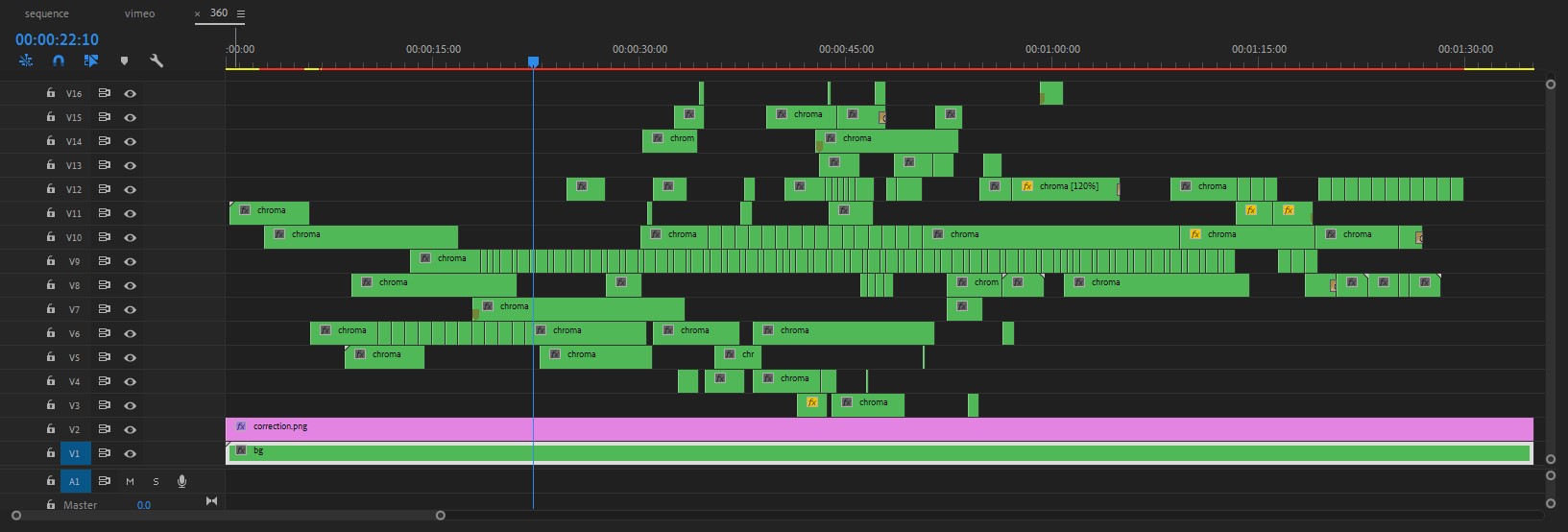
Finally, I produced a flat version of the video controlling the camera properties and transition effects between different points of view using Insta360 Studio (Vimeo version).
References
- L’Homme À La Valise by Chantal Akerman
- 1-year performance video (aka samHsiehUpdate) by MTAA
- Life Sharing by Eva and Franco Mattes
- Time Space Body Transformations by Klaus Rinke
- Inside by Dimitris Papaioannou
- LAUREN by Lauren Lee McCarthy
- Iván Haidar’s performance works