Decision Tree Classifier - Raspberry Pi Pico¶
This sketch demonstrates an example of accelerometer data processing using a classification tree. The classifier code was generated using the Python script classifier_gen.py using recorded and labeled training data. The underlying classification tree was automatically generated using the Python scikit-learn library.
The purpose of the classifier is to categorize a multi-dimensional data point into an integer representing membership within a discrete set of classifications. In the sample model, the data is two-dimensional for clarity of plotting the result. The data points could be extended to higher dimensions by including multiple samples over time or other sensor channels.
There are a couple of steps to using this approach in your own system.
Decide how to create different physical conditions which produce meaningful categories of data.
Decide what combination of sensor inputs and processed signals might disambiguate the categories. This will constitute the definition of each data point.
Set up a program with the data sampling and filtering portion of your system as a means to recording real-world data.
If your system can support a few extra user inputs, the data collection process will be easier if the data can be labeled while it is being collected. E.g., adding a ‘Record’ button and some category buttons could support emitting labeled data directly from the Pico. (This was not done in the sample code below).
Record data from the real system under the different conditions.
Trim the data as needed to remove spurious startup transients or other confounding inputs.
Run classifier_gen.py to process the training data file into code.
For 2-D data, inspect the plot output as a sanity check. You may wish to tune the modeling parameters or adjust your data set and regenerate the model.
Incorporate the final classifier code in your sketch.
Decide whether the classifier output needs additional processing, e.g. debouncing to remove spurious transients.
Sample Model¶
The sample model was built by recording accelerometer data generated by this sketch under five different physical conditions. The individual files were concatenated into a single training.csv file.
This particular example is somewhat contrived, since a reasonable two-dimensional classifier could be built by hand after inspecting the data. But this can be significantly harder in higher dimensions, e.g., if each data point were extended to include a few samples of history.
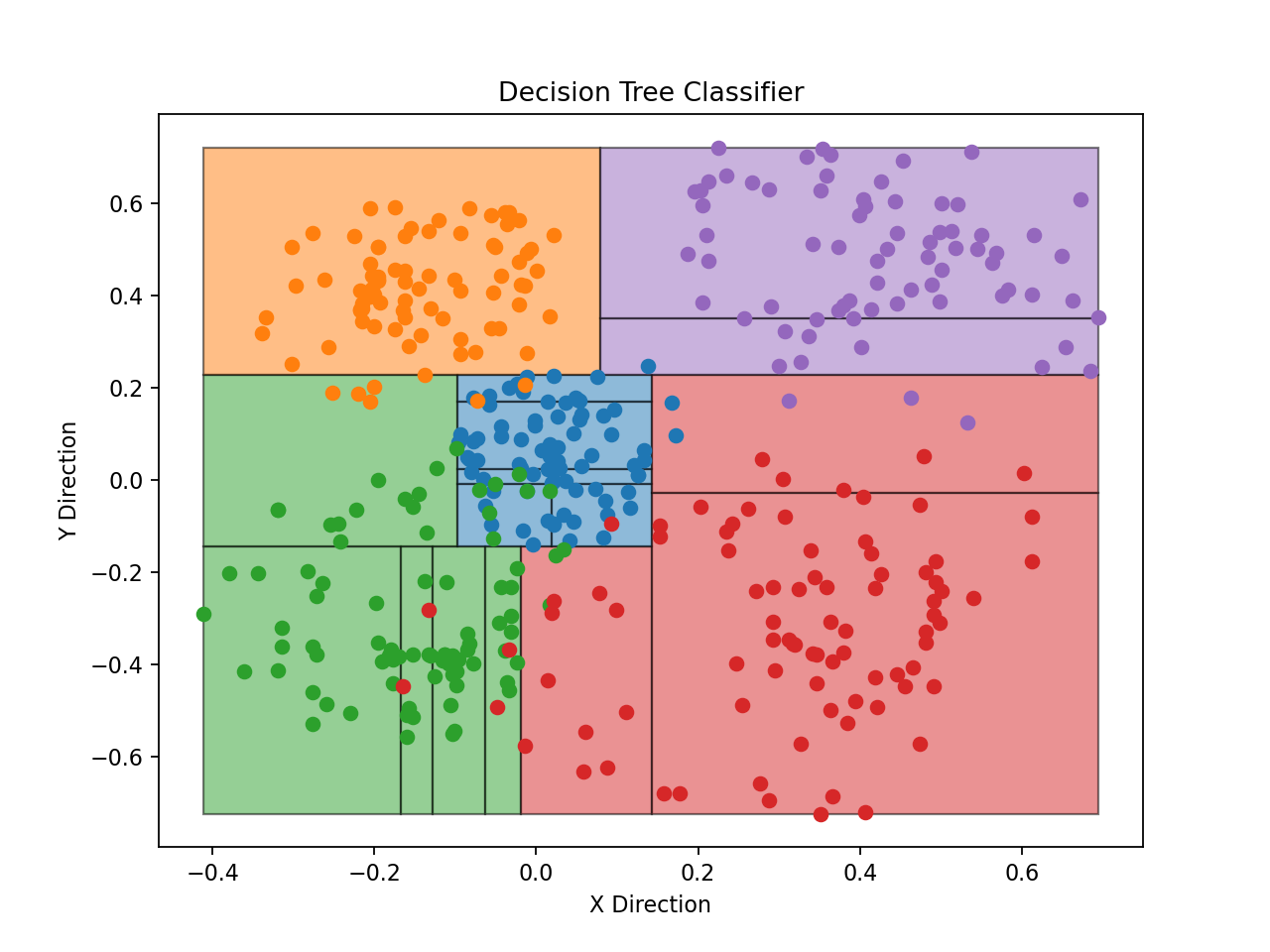
The binary classifier tree drawn over the training data. Each point represents one sample of X and Y accelerometer tilt values. Each color represents a labeled class: blue for ‘center’, and the other colors for diagonal directions. The black lines represent the binary splitting lines subdividing sample regions; each splitting line corresponds to a if/else block in the classifier code or a node in the tree data.¶
Related files:
demo.py¶
Direct downloads:
demo.py (to be copied into
code.pyon CIRCUITPY)linear.py (to be copied to CIRCUITPY without changing name)
classifier.py (to be copied to CIRCUITPY without changing name)
1# demo.py :
2
3# Raspberry Pi Pico - Decision tree classifier demo.
4
5# No copyright, 2020-2021, Garth Zeglin. This file is explicitly placed in the public domain.
6
7# The decision tree function is kept in a separate .py file which
8# was generated from data using classifier_gen.py.
9
10# Import CircuitPython modules.
11import board
12import time
13import analogio
14
15# Import filters. These files should be copied to the top-level
16# directory of the CIRCUITPY filesystem on the Pico.
17import linear
18
19# Import the generated classifier, which should copied into CIRCUITPY.
20import classifier
21
22#---------------------------------------------------------------
23# Set up the hardware.
24
25# Set up an analogs input on ADC0 (GP26), which is physically pin 31.
26# E.g., this may be attached to two axes of an accelerometer.
27x_in = analogio.AnalogIn(board.A0)
28y_in = analogio.AnalogIn(board.A1)
29
30#---------------------------------------------------------------
31# Run the main event loop.
32
33# Use the high-precision clock to regulate a precise *average* sampling rate.
34sampling_interval = 100000000 # 0.1 sec period of 10 Hz in nanoseconds
35next_sample_time = time.monotonic_ns()
36
37while True:
38 # read the current nanosecond clock
39 now = time.monotonic_ns()
40 if now >= next_sample_time:
41 # Advance the next event time; by spacing out the timestamps at precise
42 # intervals, the individual sample times may have 'jitter', but the
43 # average rate will be exact.
44 next_sample_time += sampling_interval
45
46 # Read the ADC values as synchronously as possible
47 raw_x = x_in.value
48 raw_y = y_in.value
49
50 # apply linear calibration to find the unit gravity vector direction
51 calib_x = linear.map(raw_x, 26240, 39120, -1.0, 1.0)
52 calib_y = linear.map(raw_y, 26288, 39360, -1.0, 1.0)
53
54 # Use the classifier to label the current state.
55 label = classifier.classify([calib_x, calib_y])
56
57 # Print the data and label for plotting.
58 print((calib_x, calib_y, label))
59
60 # Print a .CSV record while recording training data.
61 # print(f"4,{calib_x},{calib_y}")
classifier.py¶
1# Decision tree classifier generated using classifier_gen.py
2# Input vector has 2 elements.
3def classify(input):
4 if input[1] <= 0.22766199707984924:
5 if input[0] <= 0.14285700023174286:
6 if input[1] <= -0.1444310024380684:
7 if input[0] <= -0.01863360032439232:
8 if input[0] <= -0.06335414946079254:
9 if input[0] <= -0.16770199686288834:
10 return 2
11 else:
12 if input[0] <= -0.1279505044221878:
13 return 2
14 else:
15 return 2
16 else:
17 return 2
18 else:
19 return 3
20 else:
21 if input[0] <= -0.09689449891448021:
22 return 2
23 else:
24 if input[1] <= -0.0073440102860331535:
25 if input[0] <= 0.018633349798619747:
26 return 0
27 else:
28 return 0
29 else:
30 if input[1] <= 0.17135900259017944:
31 if input[1] <= 0.024479600600898266:
32 return 0
33 else:
34 return 0
35 else:
36 return 0
37 else:
38 if input[1] <= -0.028151899576187134:
39 return 3
40 else:
41 return 3
42 else:
43 if input[0] <= 0.07950284983962774:
44 return 1
45 else:
46 if input[1] <= 0.35006099939346313:
47 return 4
48 else:
49 return 4
50
51
52# tree data
53children_left = [ 1, 2, 3, 4, 5, 6,-1, 8,-1,-1,-1,-1,13,-1,15,16,-1,-1,19,20,-1,-1,-1,24,
54 -1,-1,27,-1,29,-1,-1]
55children_right = [26,23,12,11,10, 7,-1, 9,-1,-1,-1,-1,14,-1,18,17,-1,-1,22,21,-1,-1,-1,25,
56 -1,-1,28,-1,30,-1,-1]
57feature = [ 1, 0, 1, 0, 0, 0,-2, 0,-2,-2,-2,-2, 0,-2, 1, 0,-2,-2, 1, 1,-2,-2,-2, 1,
58 -2,-2, 0,-2, 1,-2,-2]
59threshold = [ 0.227662 , 0.142857 ,-0.144431 ,-0.0186336 ,-0.06335415,-0.167702 ,
60 -2. ,-0.1279505 ,-2. ,-2. ,-2. ,-2. ,
61 -0.0968945 ,-2. ,-0.00734401, 0.01863335,-2. ,-2. ,
62 0.171359 , 0.0244796 ,-2. ,-2. ,-2. ,-0.0281519 ,
63 -2. ,-2. , 0.07950285,-2. , 0.350061 ,-2. ,
64 -2. ]
Development Tools¶
The development of this sketch involves several other tools which are not documented:
A Python script for generating a classifier using scikit-learn: classifier_gen.py
A set of recorded training data files: data/
The Python scripts use several third-party libraries:
SciPy: comprehensive numerical analysis library
scikit-learn: machine learning library built on top of SciPy
Matplotlib: plotting library for visualizing data