Zoom Morsels
A series of small interactions using facetracking to control your presence on Zoom.
60-461/761: Experimental Capture
CMU School of Art / IDeATe, Spring 2020 • Profs. Golan Levin & Nica Ross
Zoom Morsels
A series of small interactions using facetracking to control your presence on Zoom.
Zoom Morsels: a series of small interactions using facetracking to control your presence on Zoom.
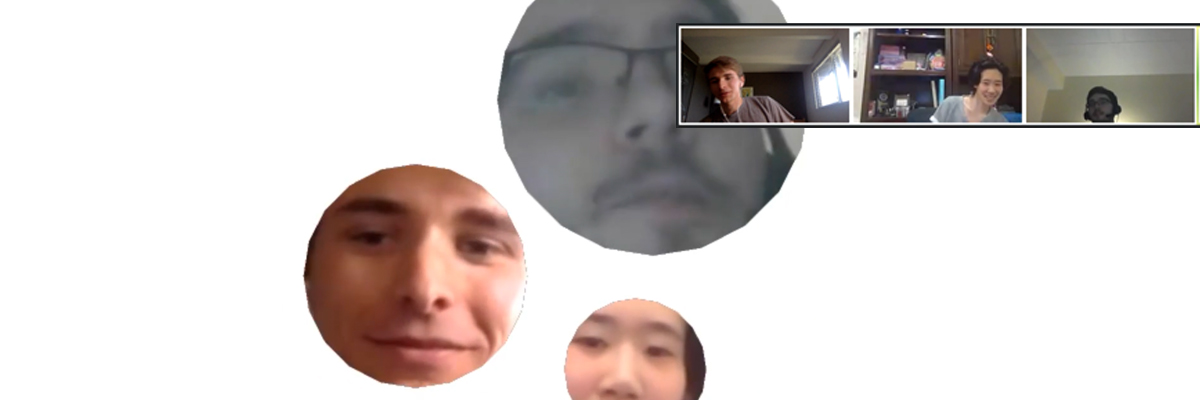
I created a system that captures people’s faces from Zoom, tracks them over time, uses them to control a new environment, then sends video back to Zoom. I was most interested in finding a way to capture people’s face and gaze from their Zoom feeds without them having to make any sort of effort; just by being in the call they get to see a new view. The system runs on one computer, uses virtual cameras to extract sections of the screen for each video, then uses the facetracking library ofxFaceTracker2 and openCV in openFrameworks to re-render the video with new rules for how to interact. There’s lots of potential uses and fun games you could play with this system, once the pose data has been extracted from the video you can do nearly anything with in in openFrameworks.
The System
Creating this system was mainly a process of finding a way to grab zoom video and efficiently running the facetracking model on multiple instances. I created a virtual camera using the virtual camera plugin for OBS Studio for each person and masked out their video by hand. Then, in openFrameworks I grabbed each of the video streams and ran the facetracker on each of them on different threads. This method gets quite demanding quickly, but enables very accurate landmark detection in real time.
Here’s what happens on the computer running the capture:

The benefit of this method is that it enables very accurate facetracking, as each video stream gets its own facetracker instance. However, this gets quite demanding quickly and with more than three video streams requires much more processing power than I had available. Another limitation is that each video feed must be painstakingly cut out and turned into a virtual camera in OBS; it would be preferable if just one virtual camera instance could grab the entire grid view of participants. My update post explains more about this. I’m still working on a way to make the grid view facetracking possible.
The Interactions
Having developed the system, I wanted to create a few small interactions that explore some of the ways that you might be able to control Zoom, if Zoom were cooler. I took inspiration in the simplicity of some of the work done by Zach Lieberman with his face studies.
I was also interested in thinking about how you might interact with standard Zoom controls (like toggling video on and off) through just your face in a very basic way. For example, having the video fade away unless you move your head constantly:
 And for people who like their cameras off, the opposite:
And for people who like their cameras off, the opposite:
 I created four different interaction modes and a couple of extra tidbits, including a tag game. The code that runs the facetracking and different interaction modes can be found here.
I created four different interaction modes and a couple of extra tidbits, including a tag game. The code that runs the facetracking and different interaction modes can be found here.
I got face tracking working with Zoom!
It requires at least two computers: one with a camera that streams video through Zoom to the second, which processes the video and runs the face tracking software, then send the video back to the first.
![]()
Here’s what happens on the computer running the capture:
This is what results for the person on the laptop:
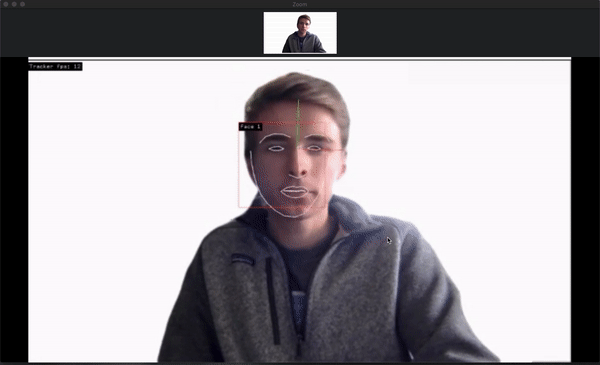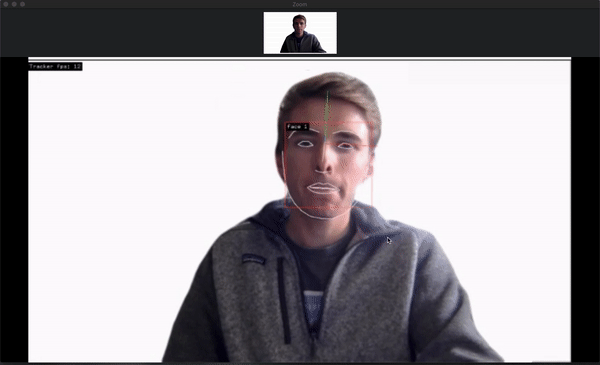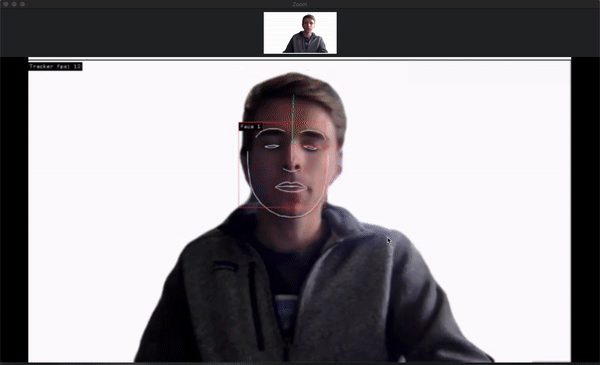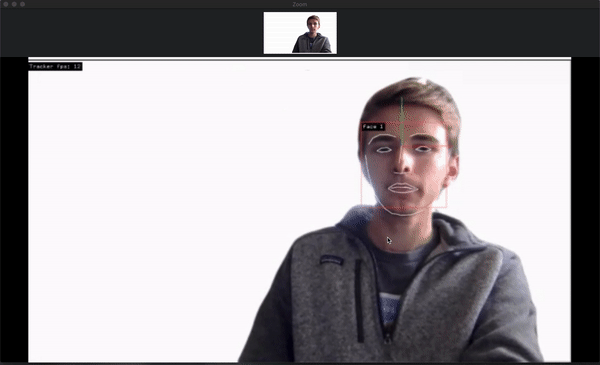
There’s definitely some latency in the system, but it appears as if most of it is through Zoom and unavoidable. The virtual cameras and openFrameworks program have nearly no lag.
For multiple inputs, it becomes a bit more tricky. I tried running the face detection program on Zoom’s grid view of participants but found it to struggle to find more than one face at a time. The issue didn’t appear to be related to the size of the videos, as enlarging the capture area didn’t have an effect. I think it has something to do with the multiple “windows” with black bars between; the classifier likely wasn’t trained on video input with this format.
The work around I found was to create multiple OBS instances and virtual cameras, so each is recording just the section of screen with the participant’s video. Then in openFrameworks I run the face tracker on each of these video streams individually, creating multiple outputs. The limitation of this method is the number of virtual cameras that can be created; the OBS plugin currently only supports four, which means the game will be four players max.
I will develop some kind of a game that uses people’s positions in their webcams through Zoom to control a collective environment. They move their body and they are able to control something about the environment. This will involve finding a way to capture the video feeds from Zoom and sending that data to openFrameworks, then running some sort of face/pose detection on many different videos at once. Then they can control some aspect of the game environment on my screen, which I share with them.
I went on a walk up a hill nearby and took a timelapse. It’s about 90 minutes reduced down to 3.5.
I recorded the timelapse with an iPhone in my shirt pocket, which contributed to the jitteriness. It definitely gets very hard to tell what’s going on during most of the uphill portions of the walk, where the horizon disappears and all that’s visible is the ground. The clearer portions of the video are the flatter sections of trail, which on this walk were rather limited.
As it got darker in the trees on the north side of the hill, the camera automatically reduced the shutter speed, resulting in a very streaky and somewhat incomprehensible image. I think it would be cool to exploit this effect more by trying one of these timelapses in an even darker environment, maybe at night.
As for the most interesting thing found on this walk, I think it would have to be this rubber chicken screwed onto a tree by some mountain bikers.

A typology of video narratives driven by people’s gaze across clouds in the sky.

How do people create narratives through where they look and what they choose to fixate on? As people look at an image, there are brief moments where they fixate on certain areas of it.

Putting these fixation points in the sequence that they’re created begins to reveal a kind of narrative that’s being created by the viewer. It can turn static images into a kind of story:
The story is different for each person:
I wanted to see how far I could push this quality. It’s easy to see a narrative when there’s a clear relationship between the parts in a scene, but what happens when there’s no clear elements with which to create a story?
I asked people to create a narrative from some clouds. I told them to imagine that they were a director creating a scene, where their eye position dictates where the camera moves. More time spent looking at an area would result in zooming the camera in, and less time results in a wider view. Here are five different interpretations of one of the scenes:
I used a Tobii Gaming eye tracker and wrote some programs to record the gaze and output images. The process works like this:
There were a couple of key limitations with this system. First, the eye tracker only works in conjunction with a monitor. There’s no way to have people look at something other than a monitor (or a flat object the same exact size as the monitor) and accurately track where they’re looking. Second, the viewer’s range of movement is low. They must sit relatively still to keep the calibration up. Finally, and perhaps most importantly, the lack of precision. The tracker I was working with was not meant for analytical use, and therefore produces very noisy data that can only give a general sense of where someone was looking. It’s common to see differences of up to 50 pixels between data points when staring at one point and not moving at all.
A couple of early experiments showed just how bad the precision is. Here, I asked people to find constellations in the sky:

Even after significant post processing on the data points, it’s hard to see what exactly is being traced. For this reason, the process that I developed uses the general area that someone fixates on to create a frame that’s significantly larger than the point reported by the eye tracker.
Though the process of developing the first program to record the gaze positions wasn’t particularly difficult, the main challenge came from accessing the stream of data from the Tobii eye tracker. The tracker is specifically designed to not give access to it’s raw X and Y values, instead to provide access to the gaze position in a C# SDK that’s meant for developing games in Unity, where the actual position is hidden. Luckily, someone’s written an addon for openFrameworks that allows for access to the raw gaze position stream. Version compatibility issues aside, it was easy to work with.
The idea about creating a narrative from a gaze around an image came up when exploring the eye tracker. In some sense the presentation is not at all specific to the subject of the image; I wanted to create a process that was generalizable to any image. That said, I think the weakest part of this project is the content itself, the images. I wanted to push away from “easy” narratives produced from representational images with clear compositions and elements. I think I may have gone a bit far here, as the narrative starts to get lost in the emptiness of the images. It’s sometimes hard to tell what people were thinking when looking around; the story they wanted to tell is a bit unclear. I think the most successful part of this project—the system—has the potential to be used with more compelling content. There are also plenty more possible ways of representing the gaze and the camera-narrative style might be augmented in the future to better reflect the content of the image.
I’d like to use the eye tracker to reveal the sequence that people look at images. When looking at something, your eyes move around and quickly fixate on certain areas, allowing you to form the impression of the overall image in your head. The image that you “see” is really made up of the small areas that you’ve focused on, the remainder is filled in by your brain. I’m interested in the order in which people move their eyes over areas of an image, as well as the direction that their gaze flows as they look.
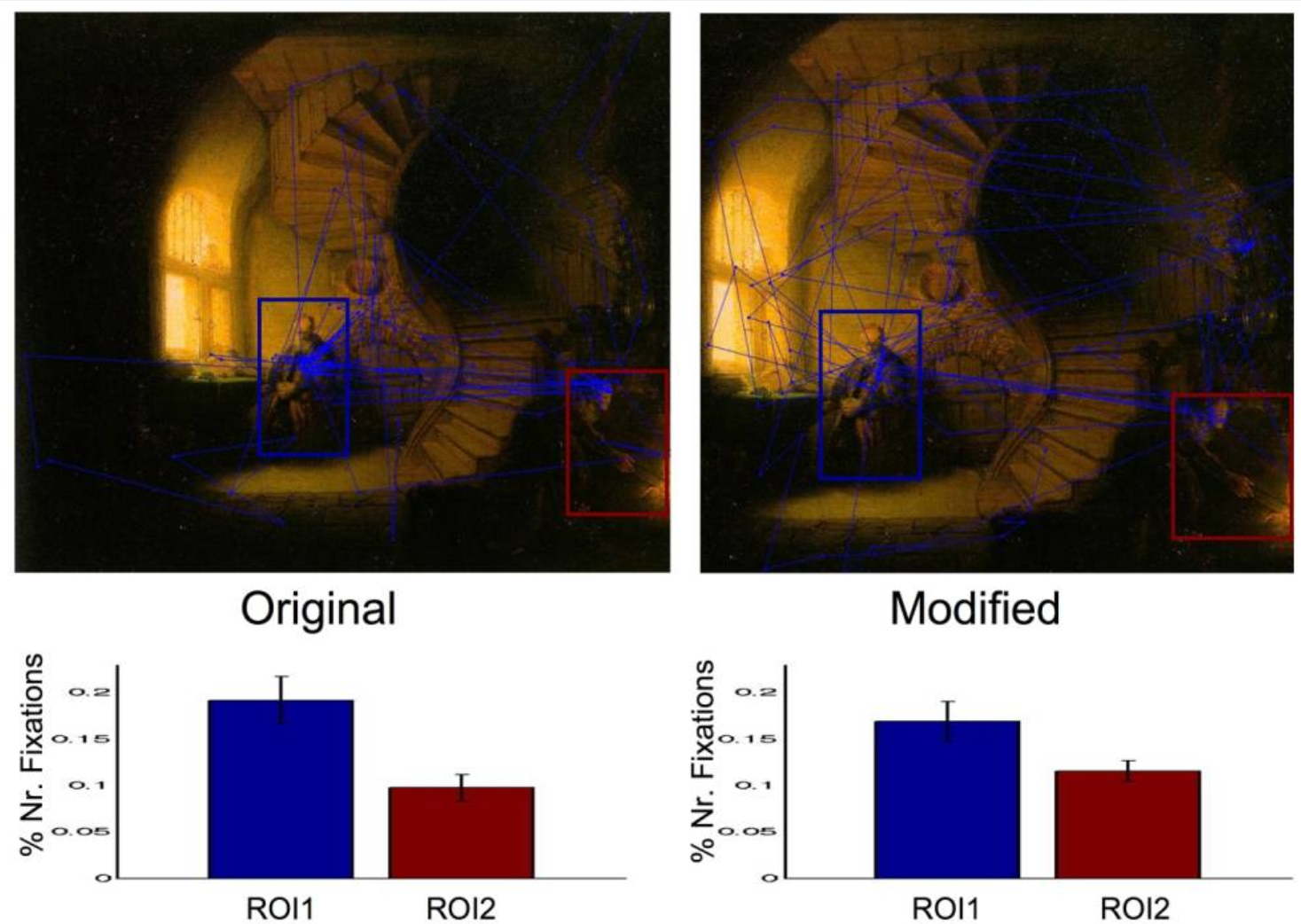
Eye tracking has been used primarily to determine the areas that people focus on in images, and studies have been conducted to better understand how aspects of images contribute towards where people look. In this example, cropping the composition changed how people’s eyes moved around the image.
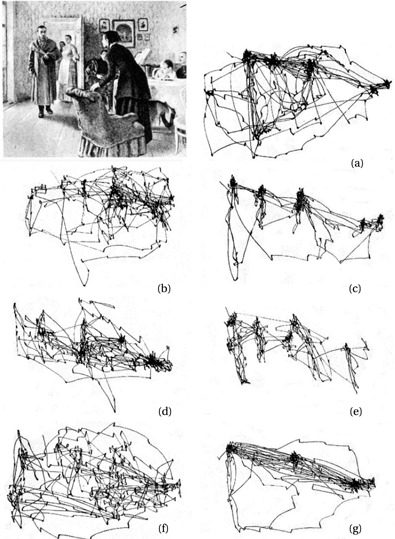
There is also a famous study by Yarbus that showed that there’s a top-down effect on vision; people will look different places when they have different goals in mind.
I haven’t been able to find any studies that examine the sequence in which people look around an image. I’d like to see if there are differences between individuals, and perhaps how the image itself plays a role.
I’m going to show people a series of images (maybe 5) and ask them to look at each of them for some relatively short amount of time (maybe 30 sec). I’ll record the positions of their eyes over the course of the time in openFrameworks. After doing this, I’ll have eye position data for each of the images for however many people.
Next, it’s a question of presenting the fixation paths. I’m still not totally sure about this. I think I might reveal the area of the image that they fixated on and manipulate the “unseen” area to make it less prominent. There’s lots of interesting possibilities for how this might be done. I read a paper about a model of the representation of peripheral vision that creates distorted waves of information.
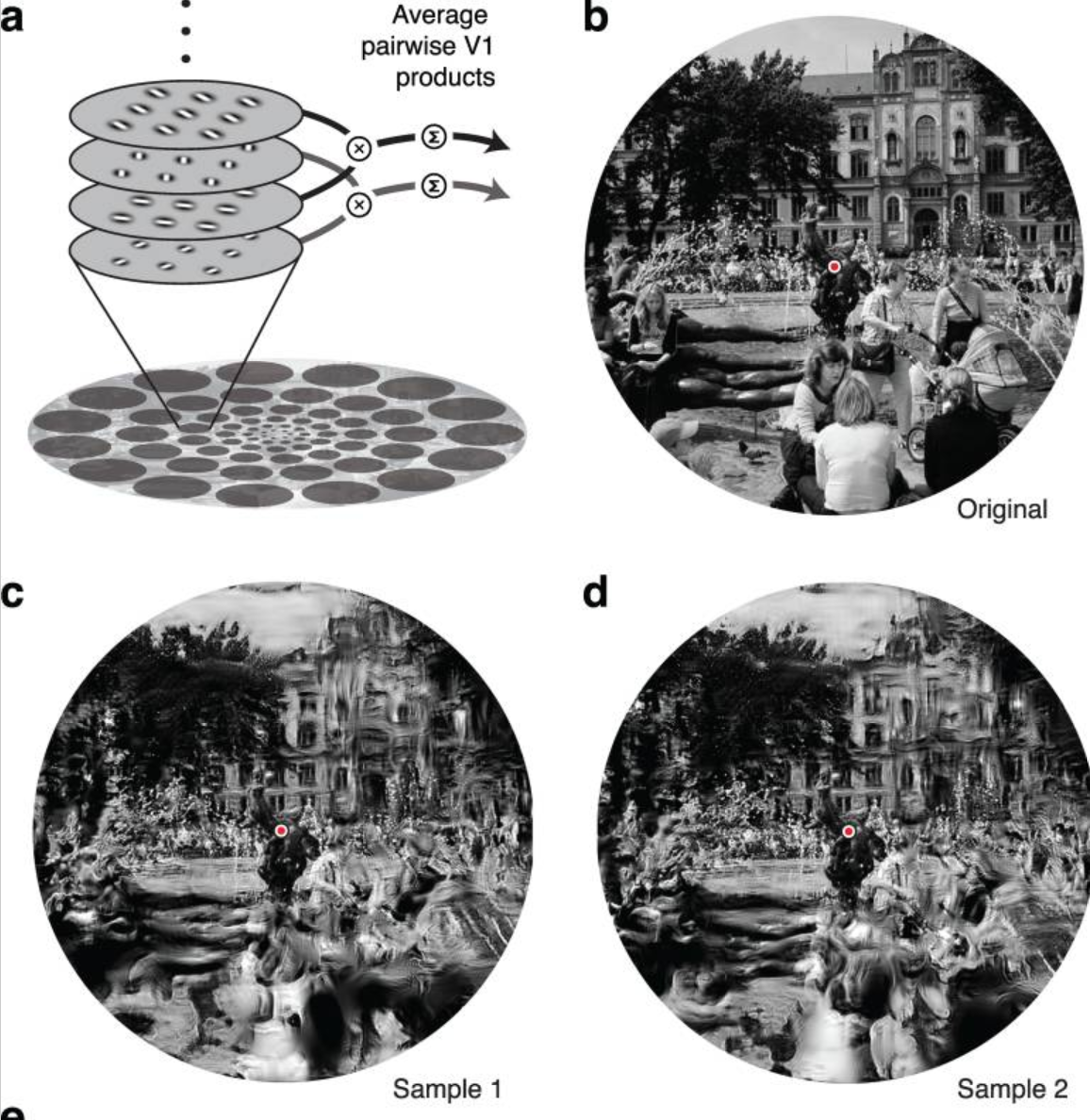
It could be nice to apply this kind of transformation to the areas of the image that aren’t focused on. The final product might be a video that follows the fixation points around the image in the same timescale as they’re generated, with the fixation in focus and area around distorted. A bit like creating a long exposure of someone’s eye movements around an image.

While not necessarily an example of non-human photography as described in the chapter exactly, I think these satellite photos of planes are particularly interesting. They reveal the way that the image is created from red, green, and blue bands that are layered together. Each image is taken by the satellite sequentially, so there’s a slight delay between each. For things on the ground that are relatively still, this is fine, but for fast moving objects like planes each of the frames doesn’t exactly line up. This creates a kind of rainbow shadow. It reveals something about the process that can’t be found in other forms of visible light photography. It’s only possible because of the computational process behind how the images are captured, and is in a sense a kind of a glitch, but a very nice one. Clearly, the author’s observation is correct in that the algorithmic approach intensifies the “nonhuman entanglement,” in addition to revealing something new.

I brought the top of an acorn.

It was comprised of these little squiggly spaghetti-like things.
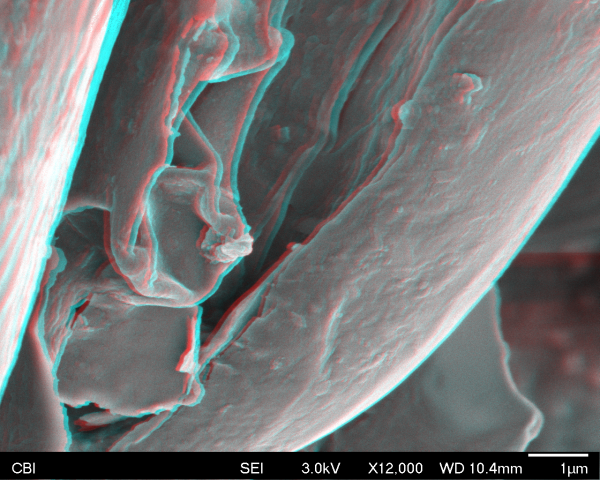

It was a bit tough capturing the stereo pair because the acorn kept moving around. Donna said this was because it was a bit large and the electrons were hitting it and causing it to shift a bit. In the end the stereo really just captured the movement of the acorn around on the surface, but I think it creates an interesting effect. It was pretty unexpected to see the acorn top made up of this kind of structure and was cool to be able to zoom way into it.

On the inside cross-section of the acorn there were these dead cells.