Users use colorful objects to interact with an emulated theremin. Brightly colored objects can be tracked using a webcam and translated into varying frequencies of tone.
I’ve had a few different concepts in mind going into this final project, but I decided to implement a tool I’ve been wanting to make for while, that happens to use physical user motion in real space to generate tones so that the program can be played and sampled like any other digital instrument.
The program has a few basic functions. First the user selects a color by clicking on the area of the video feed where their brightly colored object is. Once the color is calibrated, a function decides the position which is the weighted average of all of the pixels in the image based on how close they are to that color. The user can now move the object around in front of the camera, and the tone output from the program will reflect its position using pitch and volume.
I wasn’t able to experiment with the final setup as much I would have liked, but I put together a short edit compiling some of the sounds I recorded.
I think this piece functions best when the user is only focused on the object they’re manipulating and not having to worry about what it looks like on the screen. I think it would help to create some physical frame or boundary that the user can operate within rather than have to consider the video feed itself. I also think that the layering of sounds is an important element of the interaction. In developing this further, I think I would add functionalities for live looping or more finely controlled sampling and compositing.
For my final project, I aimed to experiment in slit-scanning. At first I was planning to use it to make a portrait series of my friend Julie and her extravagant clothes, but since the virus stopped us from seeing each other, I decided to make a self portrait series instead. As I experimented with my rotation mechanism (see details below), I realized my images resemble the helical shape of DNA. Combining the two ideas, if I had the ability to design my DNA, these images depict what I would want the sequences of my most important traits to look like.
RESOURCEFULNESS, DRIVE
This is a roll of Scotch tape, and this image is the epitome of this project — it illustrates my ability to accomplish my goal for this project despite the awful situation we’re in. As I have explained below, I created an entirely automatic rotation machine out of Arduino materials I happened to have in my closet, cardboard from all the boxes of groceries we’ve ordered, a Lazy Susan from my spice cabinet, corks from wine bottles, Scotch tape and a lot else, in order to pursue my visions for this project. I’ve always been this way: whenever there’s a problem, I set out to fix it in any way.
CURIOSITY, SPIRITUALITY
This is a glass clock. I grew up interested in a myriad of subjects, and one of my all time favorite fascinations is theoretical physics and the concept of dimensions and spacetime. I was recently writing a final paper for another class about the fourth dimension, and when she was in the room I asked my mom if she though time was another dimension. It led to an incredibly passionate conversation about our philosophies of life, religion, and spirituality, which I have only recently begun to understand for myself, and I connected with her an an entirely different level. The mixing of time and space is an idea that fascinates my entire family, and is becoming one of the main explorations in my art practice.
EMPATHY
These are cooking utensils, which represent, more literally, my family’s love for food, but also my devotion to love in general, which I learned from food. Every evening growing up, my family would sit down to a home-cooked dinner together, dropping our electronics, homework, or whatever else we were working on, and come together to eat and discuss our days and anything exciting (or depressing) that was going on in the world. Even if I didn’t know it until recently, this has been one of the most defining aspects of my life. Dinner is where I learned how to be polite and listen, make eloquent conversation, and understand and appreciate love. I am so grateful that this is how my family brought me up, and I plan to do the same with my own children someday.
CONFIDENCE
This is my wide-tooth hair comb, designed specifically for curly hair. Over the last few years, I’ve come to love my curly hair — and I used to really hate it. At the same time, my love for other aspects of myself, my abilities, and my decisions has also increased. I find that since coming to college and being even more independent than I was before it, I’m becoming more and more fearless. I know what I want, and I’m not afraid to ask for it. I think my hair was the key to my internal freedom.
MELOMANIAC
This one is a combination of music materials, including headphones, a guitar pick, and a mini amp. This aspect of me isn’t very deep — I just love music. I listen to and play it all the time. Plus it especially connects me to my dad.
Rotation Mechanism
Unfortunately, one of the bigger goals of this project, creating 3D models with photogrammetry, I was not able to achieve. I wanted to take slit-scans of the objects like I did above, but from multiple angles, to see if I could stitch them together in three dimensions. I’m not sure if my computer isn’t strong enough to see any depth (my computer crashed every 4 out of 5 tries) or this is just completely impossible to do, but after many many attempts, it never worked properly. However, two good things came out of my attempts. First, some cool GIFs of what the 3D models could potentially look like:
Second, what I predicted would be tricky about doing photogrammetry with these rotating images is that the rotation speed, starting position, and ending position all have to be constant or else the photos won’t look like they’re from the same “object” and the photogrammetry software won’t find any similar landmarks. I had to find a way to automate the process.
When I first started, I was looking for something in my house that spun smoothly. I found a little Lazy Susan in my spice cabinet and attached a string to the side, which I pulled to make it rotate. This was effective for a minute, but I quickly realized it’s impossible for a human to pull the string with a constant force, so the coils in my images would never be perfect without a machine. I needed to motorize the Lazy Susan.
Luckily, I had a bunch of Arduino pieces and cardboard lying around, so I sought out to do just that. It look a while; there was a lot of trial and error. Here’s a bit of documentation from the process.
Details
somewhat of a pulley/gear mechanism
hot glue on the sides of the lazy susan to hold the string in place
more hot glue on the inside of the cardboard wheel
piece of cork attached to wheel slides onto the motor for a steadier rotation
motor embedded in cardboard to keep it steady
wire connections
And it was successful! All the five images in the DNA series were made with my machine instead of by hand, making my image-making process super easy. I could focus a lot more on the composition of my rotating sculptures instead of futzing with the Lazy Susan. And if my laptop ever works, it would definitely be an effective device to do slit-scanning photogrammetry.
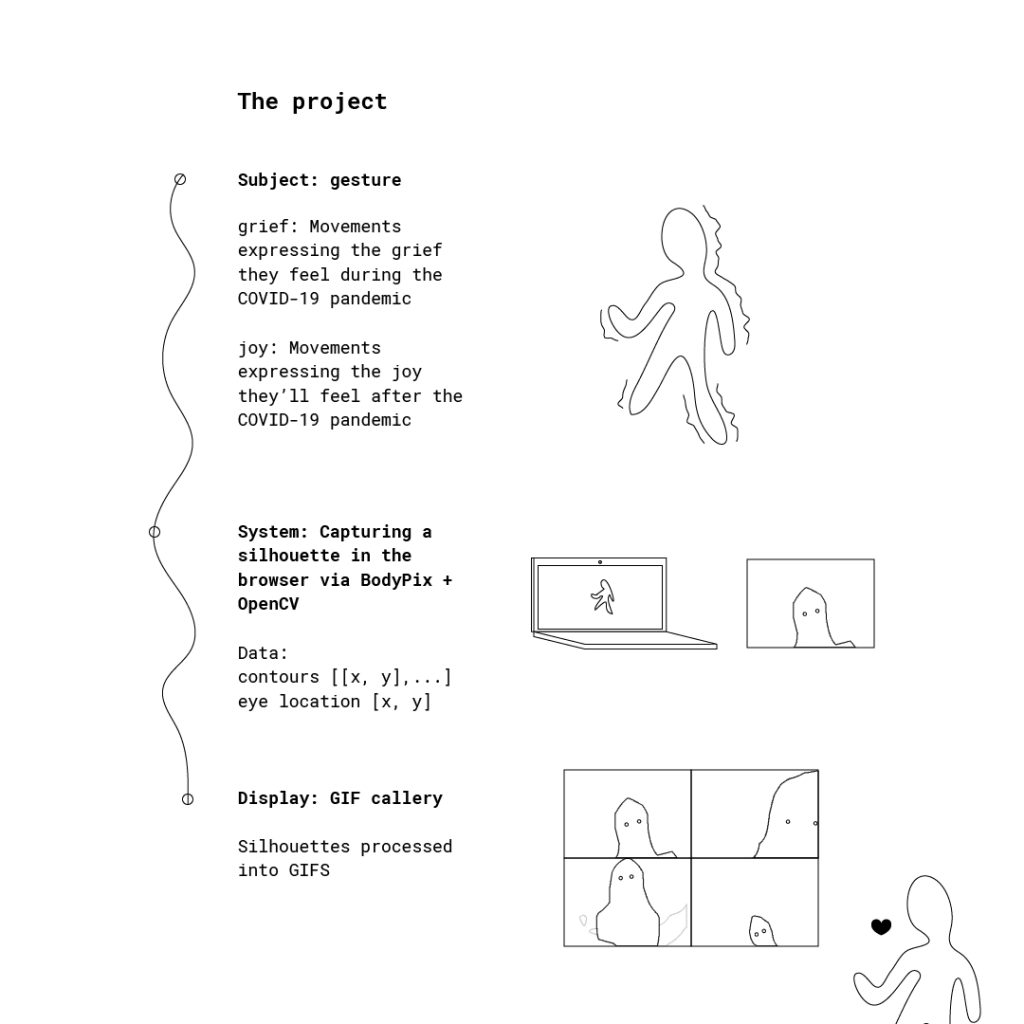
During the COVID-19 pandemic, we find ourselves experiencing a period of profound collective grief. Grief hurts. One way we can process, heal, and/or cope in this moment of grief is by listening to our own hurt, and listening to the hurt of others in solidarity. Through the invitation of anonymously performing our felt experience with gesture for a webcam, this piece aims to create a lens for observation of our felt experience during the pandemic, one that opens up space for participation and solidarity. It is built with browser tools (Ml5.js, BodyPix) to make this lens of observation as widely accessible as possible.
One hundred recorded attempts to draw the same flower in a drawing puzzle game.
Some doodling in Stroke of Genius
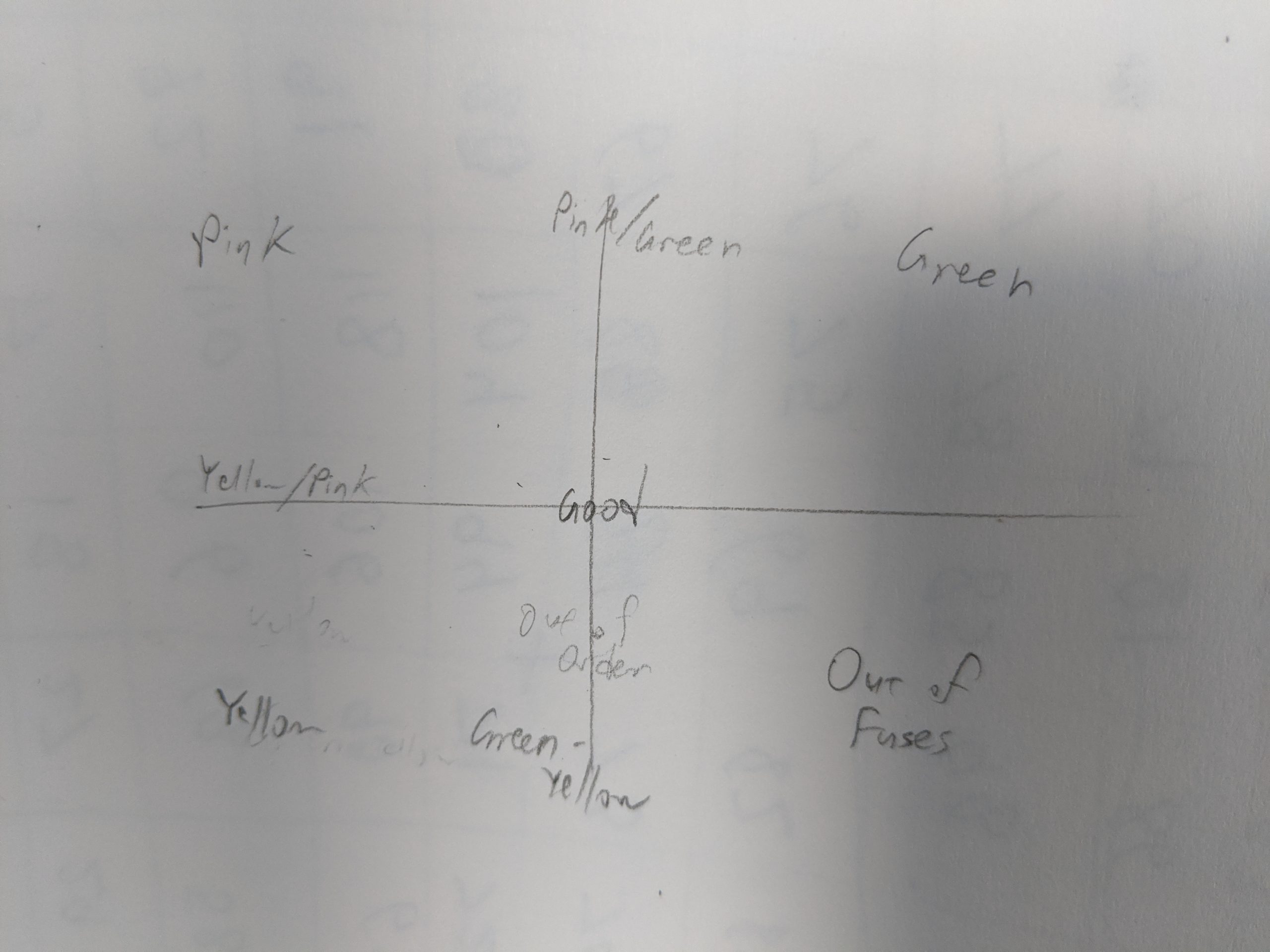
For CMU’s latest puzzle hunt, I wrote a drawing puzzle game called Stroke of Genius (pictured above,playable here) with my friend Tom Wildenhain. Players are presented with a simple drawing tool and asked to draw three images (tracing guidelines are provided). The catch is that every colored “paint” has a different unexpected behavior. For example, pink strokes follow your cursor when you finish drawing, green strokes self-destruct as you add other strokes to the canvas, and yellow strokes are duplicated rotated 180 degrees about their start point. This idea of an antagonistic drawing tool was inspired by Ben Fry’s fugpaint, but as far as I know such a tool has never before been turned into a game.
fugpaint
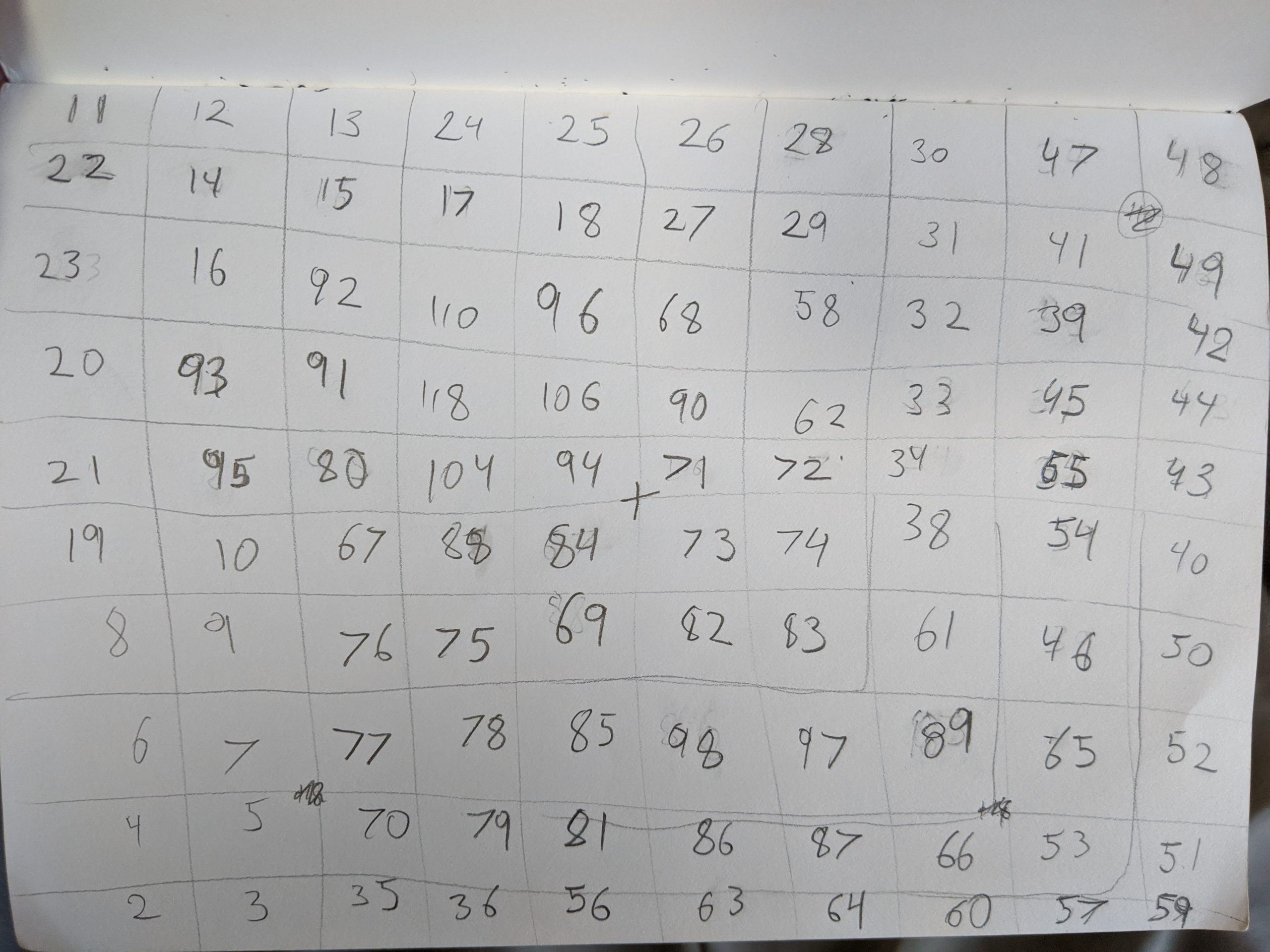
During the puzzle hunt over 500 participants played Stroke of Genius, and I recorded their keystrokes. I took 100 attempts at the first level (which gives users 3 strokes to draw a particular flower) and organized them in a grid based on what approach they took, with the more successful attempts closer to the center. This format of displaying many drawings in a grid was inspired in part by Aaron Koblin’s Sheep Market.
Sheep Market
It’s interesting to compare the different attempts at the puzzle, especially when you’ve solved it yourself, because in many cases the player’s thought process is clear through their strokes. You can see when people stop and realized they’ve made a fatal error, or become frustrated and angrily scribble over everything. The attempts are quite different, but they’re still definitely drawing the same flower. I find the final result pretty mesmerizing and easy to watch for a long time. However, there’s still a lot of interesting data that I haven’t used yet, and analyses I haven’t performed.
Though they aren’t part of the main project, you may also be interested in viewing 100 attempts to solve the other levels of Stroke of Genius. These are not sorted and only minimally filtered: fish level attempts and boat level attempts.
In case you’re interested, my reference correct solution to the flower puzzle is below. One can also complete the level by drawing green first (with a much longer tail at the beginning) and then drawing pink, making sure to stop in the center. Note that since the stroke layering matters, green must be drawn before yellow.
Stroke of Genius Flower Reference Solution
Making Of
I was originally working on a different project for this course, and treating Stroke of Genius purely as a personal project for the puzzle hunt. I spoke to Golan a few days before the hunt and expressed that I was unsatisfied with my current project. He advised me to turn Stroke of Genius into my final project, adding some code to the tool that would log participants’ strokes so I could play their drawings back later. I loved this idea, and quickly implemented it. Over 1,400 people participated in the hunt, so I ended up with over 18,000 attempts across all levels of the game.
I was originally going to do this project about the final level, the Boat, because it was the most difficult. But when I started looking through the data, I found that the boat recordings were not as informative as the flower recordings. The puzzle was so hard that most attempts were given up on early, and when an attempt failed, it was hard to tell what the participant was trying to do. The flower level, by contrast, is the simplest puzzle-wise. The antagonistic tool is just enough to be annoying. There are a few common mistakes that people make, and they are all pretty apparent to an outside observer. This gave the flower recordings the understandability I wanted, so I decided to use them for the project instead.
However, I couldn’t use all of the thousands of flower attempts I had recorded, so I filtered out several undesirable properties: drawing very little before giving up, drawing more than the allowed three strokes (because a solution could look correct but be invisibly incorrect), using the undo button (convenient for the game, but makes the recording less clear), using entirely the wrong paints (I didn’t want to introduce other colors, like blue or purple, to the grid), etc. From the remaining attempts, I randomly chose the 100 I would use in the grid. I chose a 10×10 grid because I wanted to have many densely-packed flowers, but would have to make them smaller than I wanted to fit into an 11×11.
Some attempts that were filtered out
Once I knew which attempts I was using, I needed to order them. I initially wanted to use tSNE to sort them, but had trouble getting that to work and also wasn’t sure it would use the criteria I had in mind. So I manually (and somewhat coarsely) organized them according to what I perceived to be their general approaches. For example, in the upper left, you have the people who started with pink and gave up quickly after. In the center right, you have people who drew green and then pink (a valid approach), but ended up having their leaf erased by their other strokes. The best submissions are in the center (or slightly left and top of center, since we had SO many green attempts).
My grid organization notesAn early draft of of my grid arrangement
I’m really pleased with the final result; from a distance the whole thing is aesthetically pleasing, but up close each flower has its own story to tell. I like the one in the second row and seventh column, because you can really see their “damnit” moment when their green stroke starts to self-destruct. Meanwhile in the eighth row and third column, their green starts to self-destruct and they just keep going. They get all the way done with pink before sadly wandering their cursor around the screen.
I have so much data from this project that so far went unused, and I hope to do something else interesting with it when I have a bit more time. Perhaps a heat map of people’s mouse locations? Or combine it with the game itself so once you complete a level, it shows you “People who solved it like you.” With enough filters and manual selection, I also might be able to get a presentable grid out of the fish or boat data.
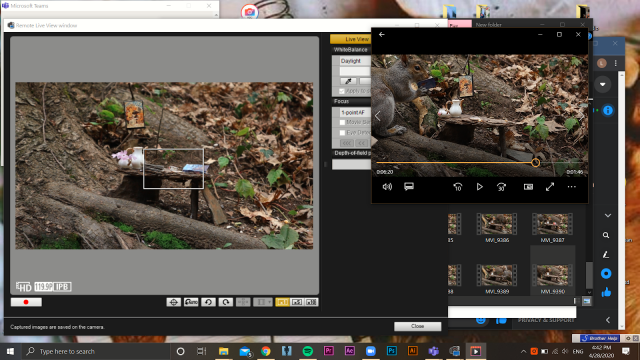
This project is inspired by children’s book illustrations of animals picnicking together in the forest, and is a continuation of the same project from earlier this semester. The squirrels perform uniquely ‘human’ activities such as reading and “baking”. They eat from tables with tea pots and snack on bagels in their kitchens. Their choices of activities, mirror how I, a human, spend my time.
What I’m particularly excited about, in this set of squirrel videos, is that I think they portray an intimacy of the single squirrel room space, which unintentionally mimicked how being stuck at home all the time feels.
Gifs:
Videos:
Process:
These videos were filmed at 120fps using a Canon M50, and enhanced to a higher quality using Topaz video enhance AI. While I experimented with DAIN (video interpolation program) for different frame rates, the pace of 120 fps worked the best.
Key materials: For the span of this project, to train and film the squirrels, I have exhausted the 8lb bag of squirrel food, two bags of walnuts, 4.5 apples, some carrots here and there (trying to offer healthier options, they are getting chunky), a full jar of Jif peanut butter and half a jar of fancy Costco peanut butter (which they like significantly less than the Jif). I have also accumulated a cast of 8 ‘repeating visitor’ squirrels and in the last week an additional 5 squirrels just out of the nest.
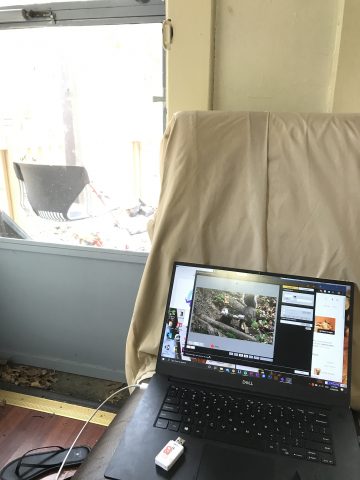
Long usb to control camera remotely while watching for squirrels out the window:
All audio is of actual squirrel sounds from the yard. (recording studio involved an iphone 7 in a zipock bag near a pile of snacks)
Zoom Morsels: a series of small interactions using facetracking to control your presence on Zoom.
I created a system that captures people’s faces from Zoom, tracks them over time, uses them to control a new environment, then sends video back to Zoom. I was most interested in finding a way to capture people’s face and gaze from their Zoom feeds without them having to make any sort of effort; just by being in the call they get to see a new view. The system runs on one computer, uses virtual cameras to extract sections of the screen for each video, then uses the facetracking library ofxFaceTracker2 and openCV in openFrameworks to re-render the video with new rules for how to interact. There’s lots of potential uses and fun games you could play with this system, once the pose data has been extracted from the video you can do nearly anything with in in openFrameworks.
The System
Creating this system was mainly a process of finding a way to grab zoom video and efficiently running the facetracking model on multiple instances. I created a virtual camera using the virtual camera plugin for OBS Studio for each person and masked out their video by hand. Then, in openFrameworks I grabbed each of the video streams and ran the facetracker on each of them on different threads. This method gets quite demanding quickly, but enables very accurate landmark detection in real time.
The process of grabbing the video feed from Zoom through OBS, creating a virtual camera, creating an openFrameworks program that grabs the camera feed and runs a facetracking library on the video, grabbing the program’s output with another OBS instance, and using that virtual camera back through Zoom as output.
Here’s what happens on the computer running the capture:
The section of the screen with the speaker’s video from zoom is clipped through OBS (this is done 3x when there are three people on the call)
OBS creates a virtual cam with this section of the screen.
openFrameworks uses the virtual camera stream from OBS as its input and runs a face tracking library to detect faces and draw over them.
A second OBS instance captures the openFrameworks window and creates a second virtual camera, which is used as the input for Zoom.
Landmark detection on a Zoom video feed.
The benefit of this method is that it enables very accurate facetracking, as each video stream gets its own facetracker instance. However, this gets quite demanding quickly and with more than three video streams requires much more processing power than I had available. Another limitation is that each video feed must be painstakingly cut out and turned into a virtual camera in OBS; it would be preferable if just one virtual camera instance could grab the entire grid view of participants. My update post explains more about this. I’m still working on a way to make the grid view facetracking possible.
The Interactions
Having developed the system, I wanted to create a few small interactions that explore some of the ways that you might be able to control Zoom, if Zoom were cooler. I took inspiration in the simplicity of some of the work done by Zach Lieberman with his face studies.
I was also interested in thinking about how you might interact with standard Zoom controls (like toggling video on and off) through just your face in a very basic way. For example, having the video fade away unless you move your head constantly:
And for people who like their cameras off, the opposite:
I created four different interaction modes and a couple of extra tidbits, including a tag game. The code that runs the facetracking and different interaction modes can be found here.
A 360° video performance of hectic and frisky actions and gestures overlapped in the domestic space.
The stay-at-home order has enabled the transfer of our outdoor activities and operations into the domestic space. What used to happen outside of our walls, now happens infinitely repeated in a continuous performance that contains each of our movements.
Return home indefinitely produces an unsettling sentiment of oddness. For some people, this return will affect identically to that man in by Chantal Akerman’s ‘Le déménagement,’ that stands bewildered to the asymmetry of his apartment. For me, it represents an infinite loop of actions that kept me in motion from one place to another. A perpetual suite of small happenings similar to the piano pieces that the composer Henri Cowell titled ‘Nine Ings’ in the early 20th century, all gerunds:
In ‘360 Ings’ those small gestures and their variations are recorded in the 360-degrees that a spherical camera can capture, isolated and cropped automatically with a machine learning algorithm, and edited all together to multiply the self of the enclosed living.
A 360 interactive version is available on Youtube.
Recording
I used the Xiaomi Mi Sphere 360 Camera which has a resolution of 3.5K video, and therefore the sizes of the video files were expected to be quite big. For that reason, I had to reduce the time of the performance under 5 min (approx. 4500 frames at 15fps). Time and space planning has been fundamental.
The footage provided is then remapped and stick into a panoramic image using the software provided by the company.
Background subtraction
After the recording process, I used a machine learning method to subtract the background of an image and produce an alpha matte channel with crisp but smooth edges to rotoscope myself in every frame. Trying many of these algorithms has been essential. This website provides a good collection of papers and contributions to this technique. Initially, I tried MaskRCNN and Detectron 2 to segment the image where a person was detected, but it did not return adequate results.
Mask RCNN segmentation results
Deep Labelling for Semantic Image Segmentation (DeepLabV3) produces good results, but the edge of the object was not clear enough to rotoscope me in every frame. A second algorithm was needed to succeed in this task, and this is exactly what a group of researchers at University of Washington are currently working on. ‘Background Matting’ uses a deep network with and adversarial loss to predict a high-quality matte by judging the quality of the composite with a new background (in my case, that background was my empty living room). This method runs using Pytorch and Tensorflow with CUDA 10.0. For more instructions on how to use the code, here is the Github site (they are very helpful and quick responding).
Rotoscoping process
Editing
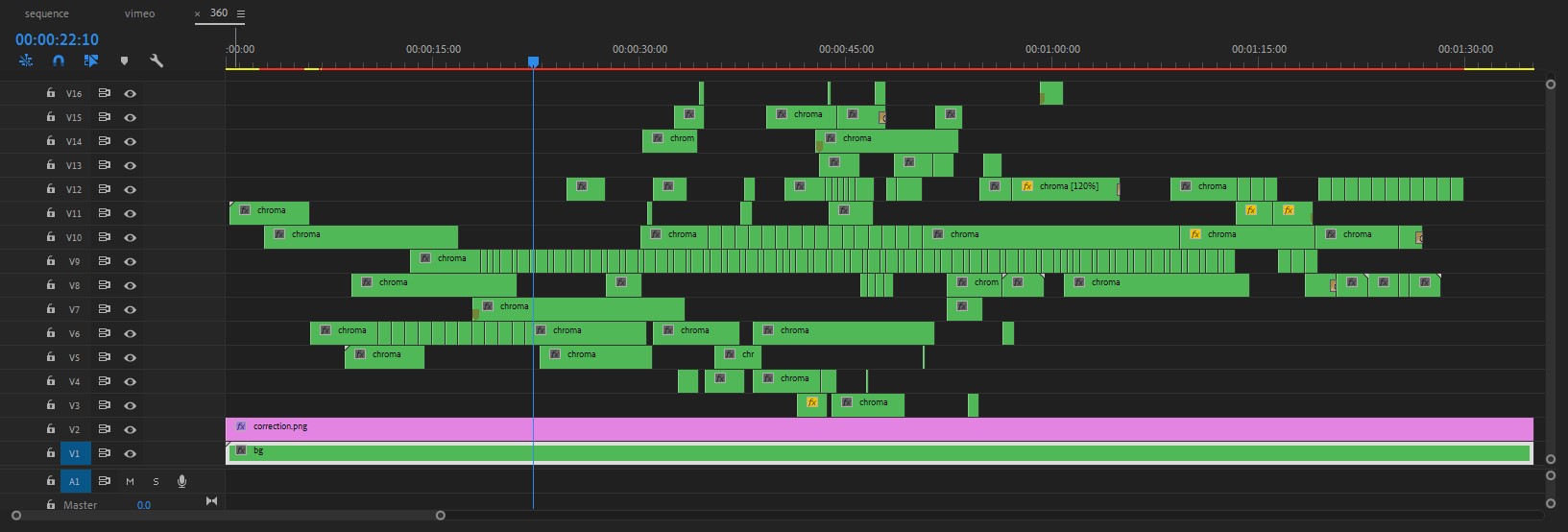
With the new composite, I edited every single action on time and space using Premiere. The paths of my movements often cross and I had to cut and reorganize single actions into multiple layers.
Premiere sequence
Finally, I produced a flat version of the video controlling the camera properties and transition effects between different points of view using Insta360 Studio (Vimeo version).
During this quarantine we’ve been asked to stay at home – we’re all being confined to some smaller space. The goal of this project was to create a map of people spaces of quarantine – the enclosed area where we’re spending a ton of time during this crisis. To achieve this goal I’ve used photogrammetry and high resolution 3D rendering to create a tiled image of multiple spaces together.
Thanks to the participants in this project: Lumi Barron, Stacy Kellner, Sarika Bajaj, Jack Thorman, Jackie Chou, Jason Perry, and Avery Robinson.
Project & Process:
Participants used a photogrammetry app to create a model of their space. After receiving a model I moved it to a 3D environment where I could render a high resolution image from a birds eye view. All of the renderings were compiled together in a giga-pixel image (25,000 x 25,000 px) to allow viewers to see the extreme details of each scene.
Photogrammetric scan of my space of quarantine:
High resolution rendering of my space from above:
This project provides a unique perspective on these spaces where people have been spending all of their time. Additionally, the capture method has the effect of removing the inhabitant from the extremely lived in space.
Project Precedent:
My initial interest in this project emerged from films and 2d games that use unique techniques to flatten scenes and spaces.
Reflections:
I settled on this exact version of this project within the last 7 days, which didn’t give me a lot of time to collect scans of spaces. I’d be interested to see how this project might change if I could collect more scans. Additionally I’d like to explore ways to augment the static image — possibly by adding in ambient noise sampled from peoples spaces.
In a more general reflection on the outcome of this project: I’m really interested in the capability of technologies like photogrammetry to allow us to image an entire space while inhabiting it.
We are experiencing a period of profound collective grief. In a recent interview with Harvard Business Review, David Kessler, expert on grief and co-author (with Elisabeth Kübler-Ross) of on Grief and Grieving: Finding the Meaning of Grief through the Five Stages of Loss, says that we are feeling a sense of grief during the COVID-19 pandemic:
“…we’re feeling a number of different griefs. We feel the world has changed, and it has. We know this is temporary, but it doesn’t feel that way, and we realize things will be different…This is hitting us and we’re grieving. Collectively. We are not used to this kind of collective grief in the air.”
Grief hurts. One way we can process, heal, and/or cope in this moment of grief is by listening to our own hurt, and listening to the hurt of others in solidarity.
healing happens when a place of trauma or pain is given full attention, really listened to.
— Adrienne Maree Brown
The most profound way to process grief with others is being physically present with them. This is because, according to scholars and musicians Stephen Neely (professor of Eurythmics at CMU) and Émile Jaques-Dalcroze, our bodies are considered the first instrument; we come to know our world through the immediate tangible interactions with our environment.
“before any experience is understood in the mind, it has to first resound through and be felt in the first experiencing instrument, the body.”
— Jaques-Dalcroze
But grieving with others becomes profoundly hard when we must be apart, when being close to loved ones means we might make them sick.
It’s hard to carve out a moment to take stock of how we’re feeling, and even more difficult to share feeling with others beyond text, video, and our own limited networks. In the words of artist Jenny Odell, art can serve as a kind of “attentional prosthesis.” For example, work such as Nina Katchadourian’s Sorted Books invite us to dig into our own libraries to create our own sculptural book phrases.
From Nina Katchadourian’s Sorted Books project
Taking a leaf from Nina Katchadourian’s book, I’m hoping to create a lens for observation of our felt experience during the pandemic, one that opens up space for participation and solidarity.
How might I create a capture system for expressing grief as a display of solidarity?
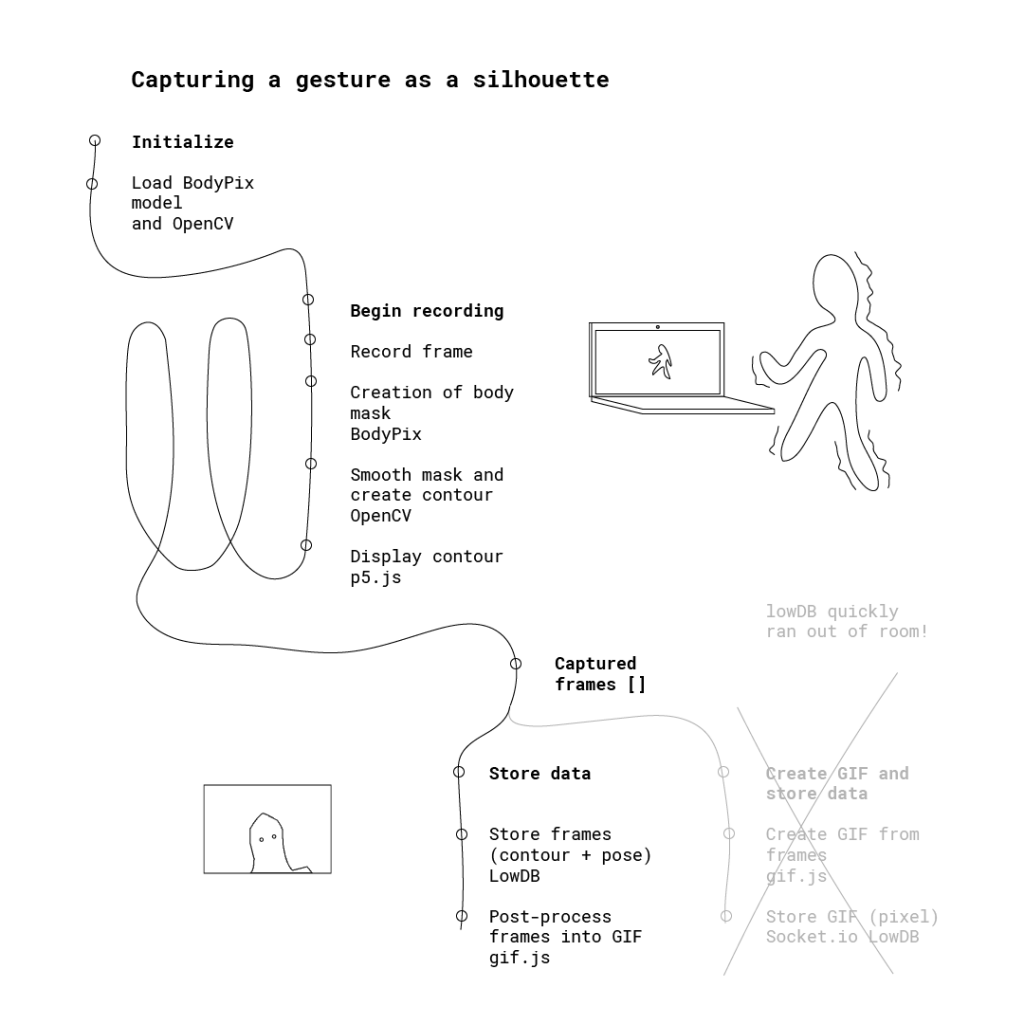
The general workflow
The subject: a body in motion
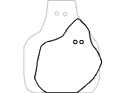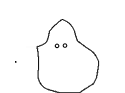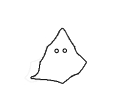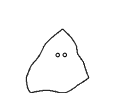
I chose to abstract the body in motion into an animated silhouette. It not only protects identity of participants, but amplifies our sense of solidarity with them. We can see ourselves in more abstract bodies. They also invite play.
From Scott McCloud’s Understanding Comics
The capture system
What tools like Ml5.js and others offer us is a way to make tools, or lenses of observation, more widely accessible to non-experts. Platforms like Glitch made deployment friction-less.
The workflow
At the end of the capture, you can download the capture you’ve created, and submission is optional.
The captures
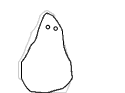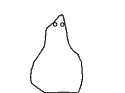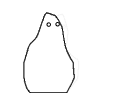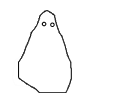
I opened up the tool on a trial run with my cohort, with several captures over 1-2 days. I processed their submissions into a collection of gifs:
We may find that we have lost a lot during this pandemic. 😢
Expressing sadness can be an act of release. How do you feel?
There will be a moment when the pandemic is over. Imagine it 😀 How will you dance?
What piqued my interest
A lens for reflection. I’ve created a tool for easily (and privately) expressing emotion through gesture, particularly in a time when body-centered reflection is needed. The project is less about the gallery of captures, more about the opportunity to explore with the body. Nevertheless, I am most excited about capturing (and remembering) the pandemic feels in a visceral way.
Bodypix. This is a relatively new port to Ml5.js. The browser-based tool makes capturing poetic movement in time more easy to use and accessible.
Glitches & opportunities
Tone setting / framing. I’m used to holding these kinds of reflective conversations in person. How I could set a reflective tone with no control over its context of us was largely a mystery to me. Early feedback seemed to emphasize the tool didn’t provoke them to reflect deeply.
Glitchiness in gifs. Inconsistency across machines produced wildly inconsistent (and glitchy) gifs. How quickly certain machines can run the bodyPix model and draw frames in seemed to P5.js vary wildly.
Seamless workflow for storage of gifs. My server (temporarily) broke. Lowdb didn’t readily store the created gifs in an image format, so . My server filled up after only ~20 submissions, after which I opted to only store silhouette frames (which I then post-processed into GIFs by manually downloading the frames from Glitch). Ideally, the pipeline from capture to gallery would be fully automated.


 CURIOSITY, SPIRITUALITY
CURIOSITY, SPIRITUALITY
















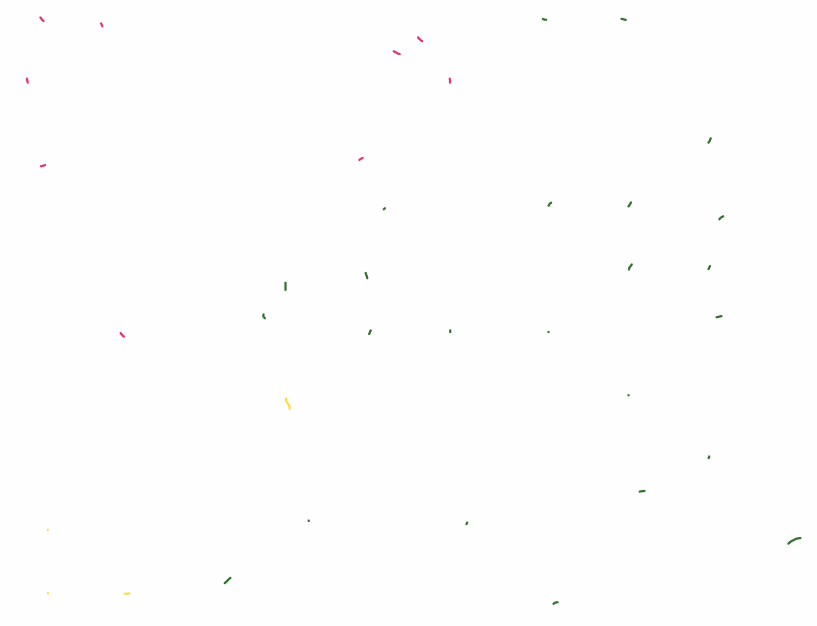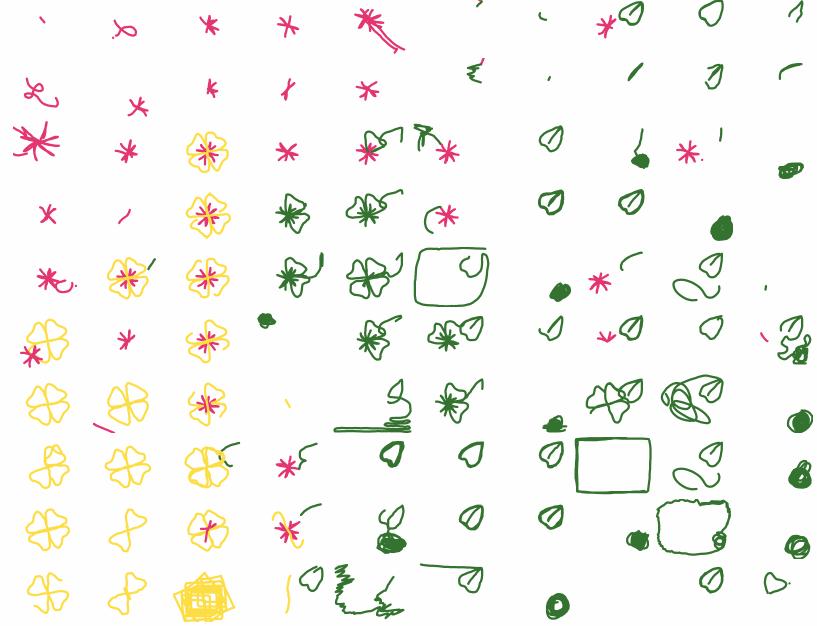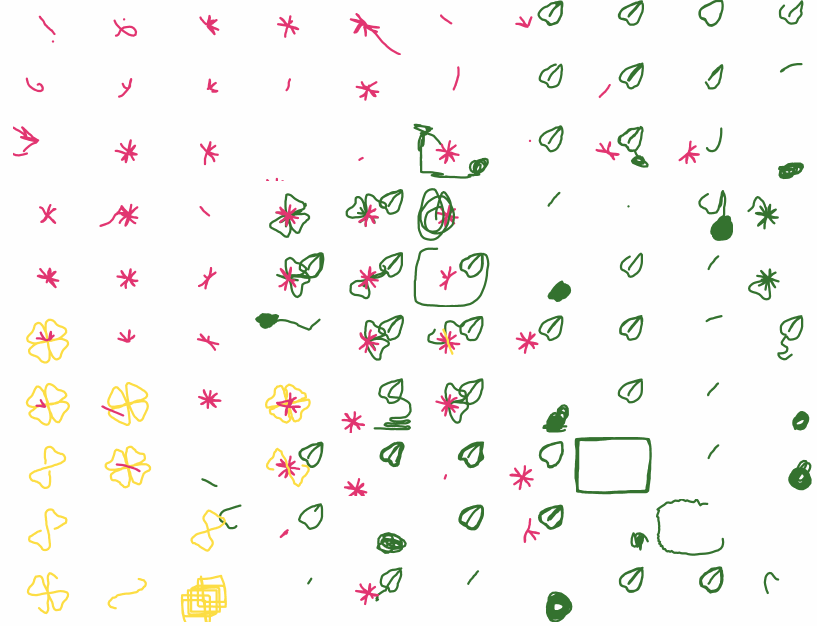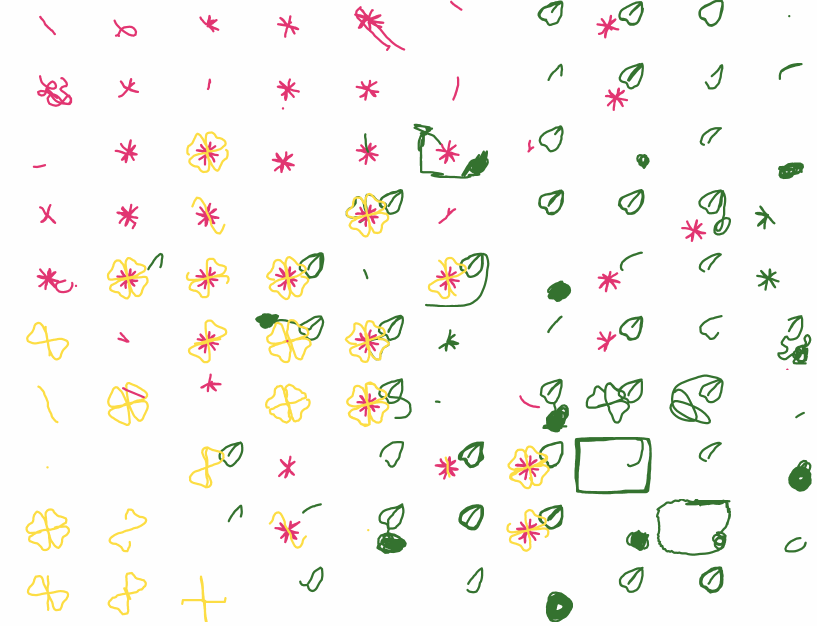


 This project is inspired by children’s book illustrations of animals picnicking together in the forest, and is a continuation of the same project from earlier this semester. The squirrels perform uniquely ‘human’ activities such as reading and “baking”. They eat from tables with tea pots and snack on bagels in their kitchens. Their choices of activities, mirror how I, a human, spend my time.
This project is inspired by children’s book illustrations of animals picnicking together in the forest, and is a continuation of the same project from earlier this semester. The squirrels perform uniquely ‘human’ activities such as reading and “baking”. They eat from tables with tea pots and snack on bagels in their kitchens. Their choices of activities, mirror how I, a human, spend my time.