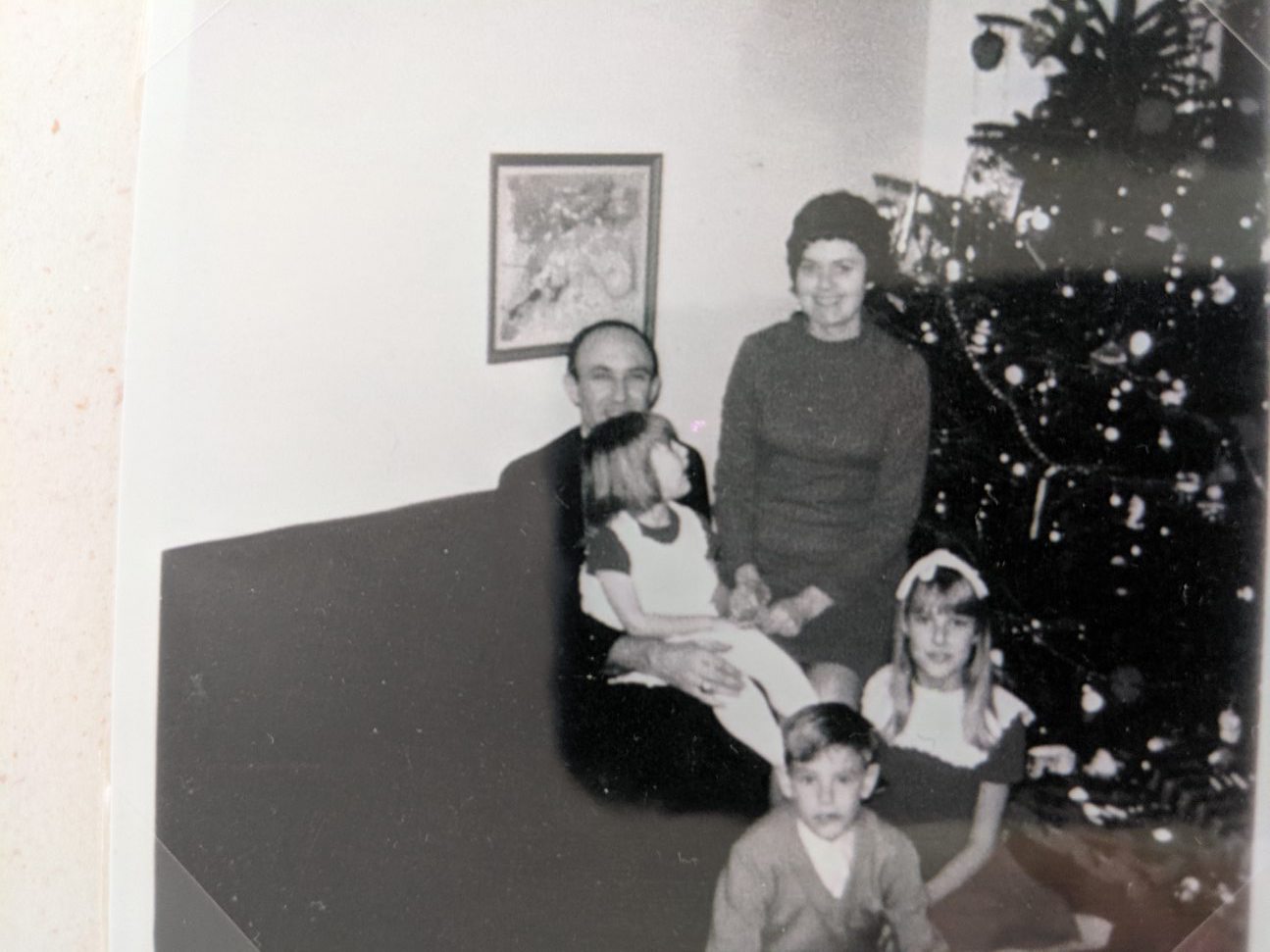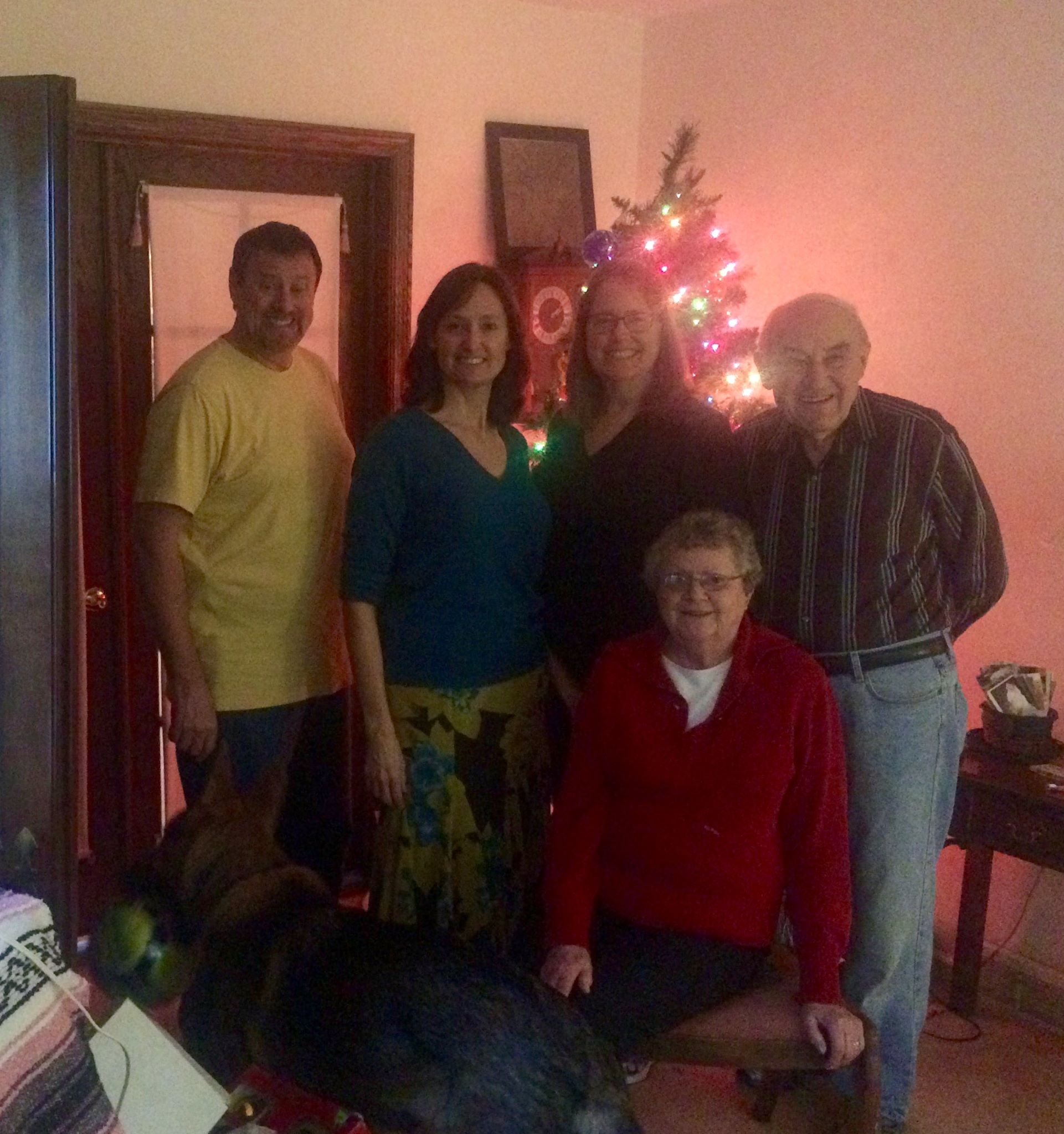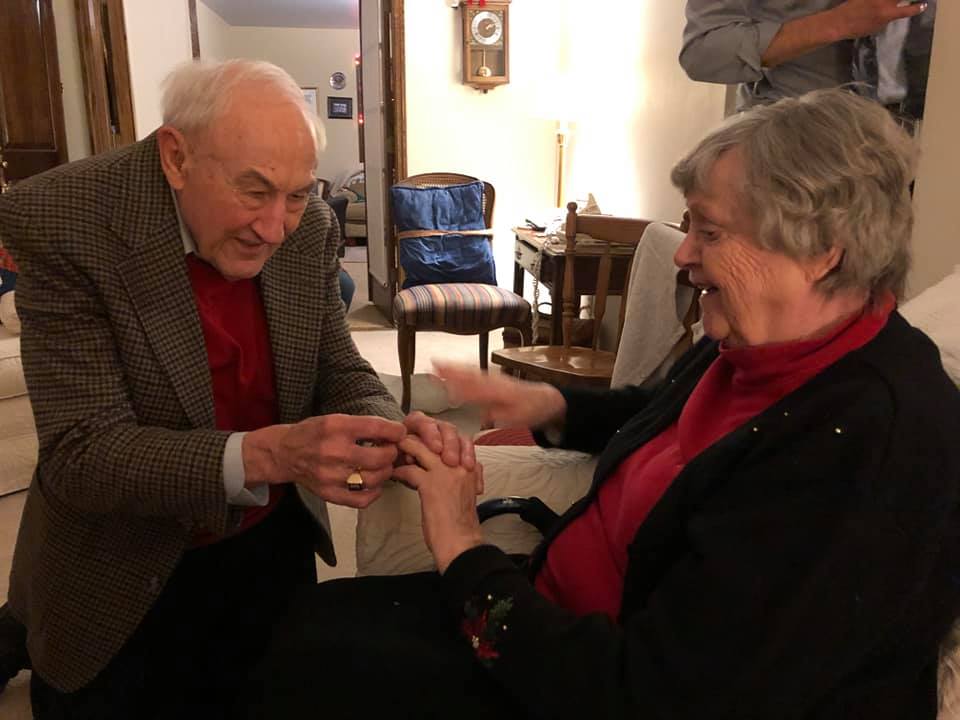Using corporate knowledge transfer methods to make a portrait of my grandfather
Background: (in all seriousness) I have one grandparent left, and we’ve been getting closer over the last few years. He expresses a sort of regret over not having been an active part of my childhood (thanks to living on opposite ends of the country). I want to help close this gap, find a way to capture his wisdom, and consider the knowledge-based “heirlooms” he might be passing down.
What do we do in the face of this problem? We turn to the experts. When you google “intergenerational knowledge transfer” or even “family knowledge transfer,” all you get is corporate knowledge transfer methods. What happens if I apply these methods to my family as if it were an organization? Going down this rabbit hole makes for a super weird and fun project.
Intro:
Method derived from: Ermine, Jean-Louis. (2010). Knowledge Crash and Knowledge Management. International journal of knowledge and systems science (IJKSS). 1. 10.4018/jkss.2010100105.
-
“Inter-generational knowledge transfer is a recent problem which is closely linked to the massive number of retirements expected in the next few years.”
-
“This phenomenon has never occurred before: this is the first time in the history of mankind that ageing is growing like this, and, according to the UN, the process seems to be irreversible.”
-
“According to the OECD’s studies, this will pose a great threat to the prosperity and the competitiveness of countries.”
- “[We can tackle this] inter-generational knowledge transfer problem with Knowledge Management (KM), a global approach for managing a knowledge capital, which will allow a risk management in a reasonable, coherent, and efficient way.”
- “We propose a global methodology, starting from the highest level in the organization” —> for me, this means the patriarch of the family.
The Method: 3 phases
- Strategic analysis of the Knowledge Capital.
- First, identify the Knowledge Capital. Last week, I called my grandpa and gathered a list of every single thing he had done that day.
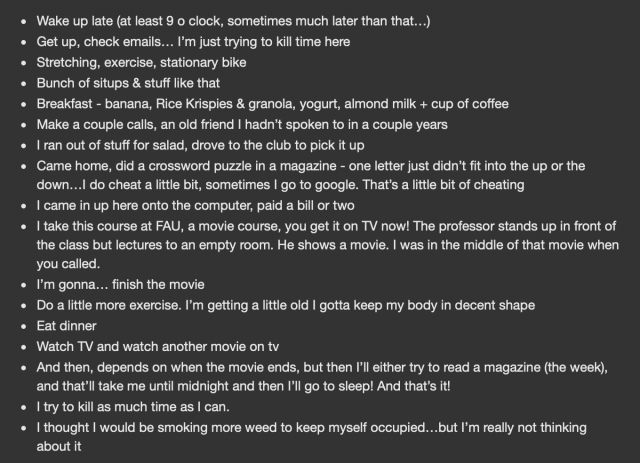
I also supplemented this list with some more characteristics, gathered through a call with my sister. - Next, perform an “audit” to identify the knowledge domains that are most critical, by using the following table:

every domain here will get a score; those with the highest score are the most important.
- First, identify the Knowledge Capital. Last week, I called my grandpa and gathered a list of every single thing he had done that day.
- Capitalization of the Knowledge Capital. Now that I know the most important task(s), convert the tacit knowledge of how to do it (them) into explicit knowledge. Or, in other words,
“collect this important knowledge in an explicit form to obtain a ‘knowledge corpus’ that is structured and tangible, which shall be the essential resource of any knowledge transfer device. This is called ‘capitalisation’, as it puts a part of the Knowledge Capital, which was up to now invisible, into a tangible form.”
As a fun aside, the last line there is essentially the corporate-speak definition of “experimental capture.” 🙂 To do this, I’ll be drawing on interview techniques from Rachel Strickland’s Portable Portraits, as well as some “Knowledge Modeling” techniques from the corporate article, such as the “phenomena model,” “concept model,” and “history model.”
-
Phenomena model: describe the events that need to be controlled/known/triggered/moderated to complete the task
- Concept model: mental maps – may ask him to draw a diagram of how he does a task
-
History model: learn more about the “evolution of knowledge.” Ask why – hear the story behind a particular artifact, etc.
- TL;DR – the capture technique is a mixture of video, drawing, and interview, depending on the task (and whether or not video creates too many technical difficulties for a 90 year old :))
-
- Transfer of the Knowledge Capital. This is all about how the Knowledge Corpus is disseminated. This usually goes in the form of a “Knowledge Book” (or a “Knowledge Portal” if it’s online). Furthermore, to ensure successful transfer it’s often good practice for the recipient to do something actionable with the Knowledge Corpus.
- Existential Question: since I am literally a body of genetic transfer… am I the recipient, or am I the actual Knowledge Corpus itself?
- Either way, I plan to take action by recreating (and recording) the task(s) myself, relying on my own memory as a source of tacit knowledge. If I am the “recipient” of the book/portal, this will be my way of proving successful transfer via action. If I am the corpus itself, this will be a final capture method to convert tacit knowledge into explicit knowledge and create the book/portal.
Ta-da! I have created a kind of fucked up heirloom.