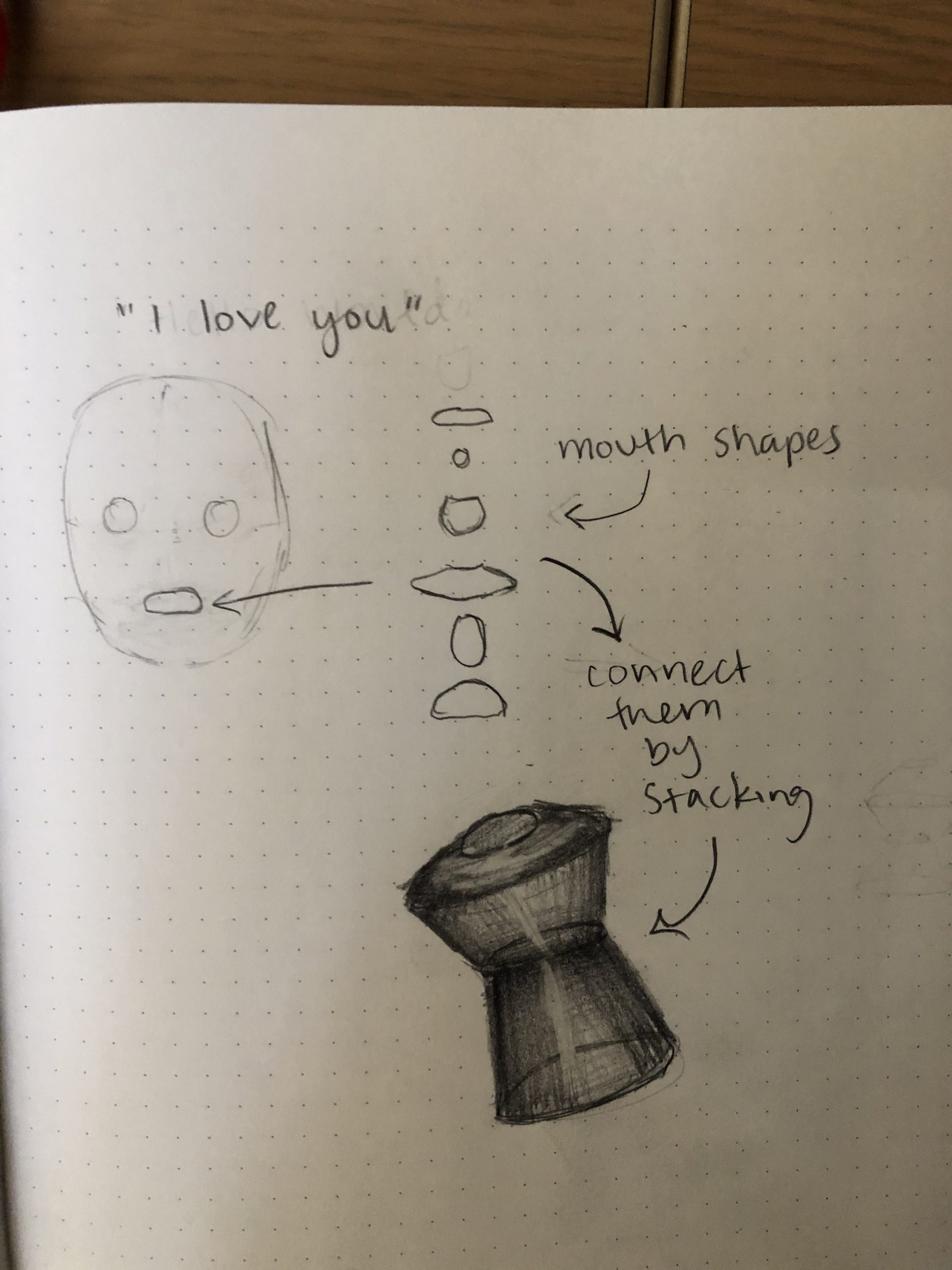
For my project, I want to record people’s mouths saying something to a person they love and make sculptures out of the change in shape of their lips. I will do this by tracing the lips of every frame of a video (or burst of photos), which will vary widely depending on what people say, the shape of the lips, and what language they speak, and then stacking those shapes on top of each other somehow to create a three-dimensional shape.
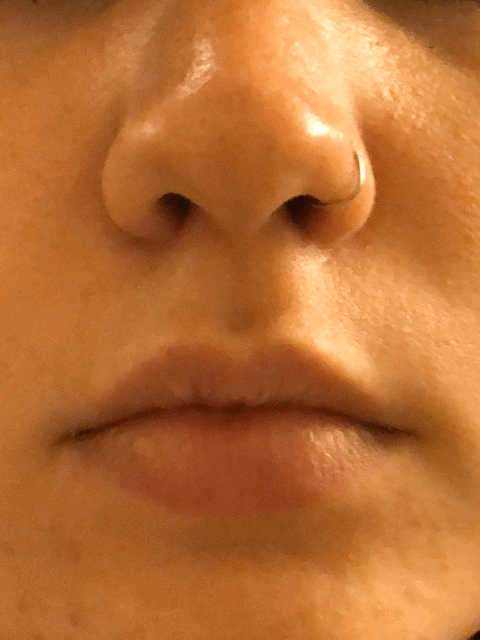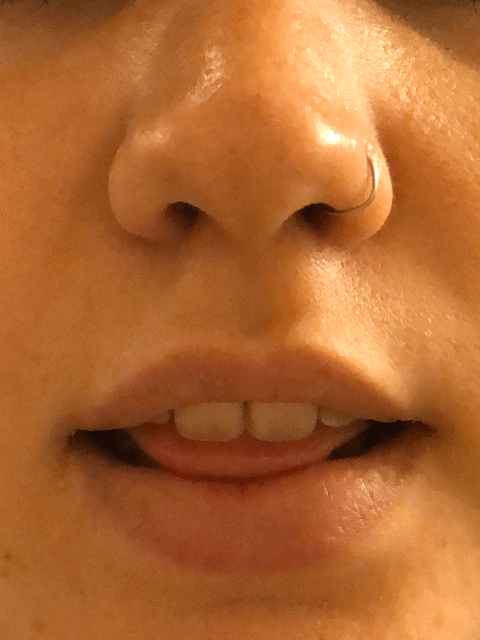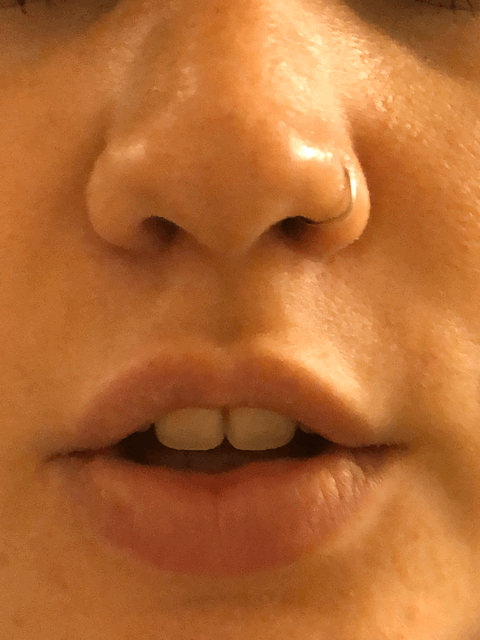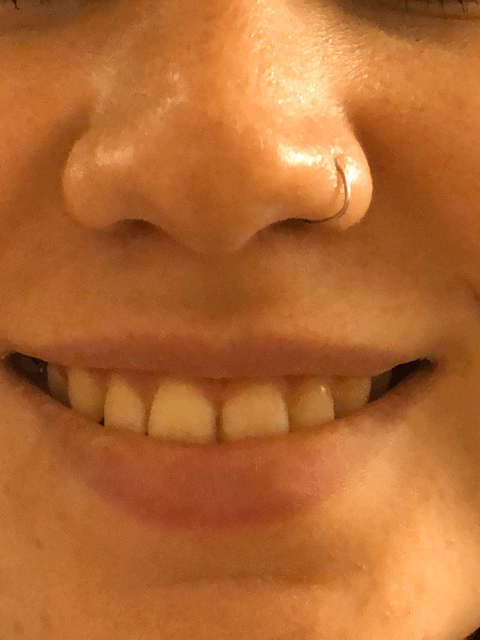

(I skipped some frames when sketching.)



(I would not use a material as thin as paper for the final sculpture.)
However, I am still unsure of the degree of automation that I want the machine to work at. I think the following two ideas are equally interesting but incredibly different and could create entirely different meanings behind the final typology.
Very Automatic. I record someone’s lips with the slow motion camera. I write a script in Processing that, when fed the recording, will break the video down into its frames, extract the shape of the lips in each frame with FaceOSC, and export the relative XY coordinates of each frame’s “lip shape” (landmarks) to a text file. I write a Blender script that, when fed the text file of 2D lip shapes, will sequentially layer the shapes along the Z axis, stitch the shapes together, and export an FBX file of the new 3D shape. At this point, I can either send the FBX to a 3D printer and end up with a small, smooth plastic sculpture; or, I continue to slice the model, cut the slices on the laser cutter, and end up with a sculpture like the photo below. Once I finish the scripts, I could easily make as many sculptures as I wanted (as time permits), at any size ranging from finger to forearm-size (relatively small).

Not Automatic. I stay as far away from technology as possible. I use a film camera void of a computer to take a burst of photos of lips speaking.

I develop the negatives in the darkroom and create large-ish prints on the enlarger (11 x 17 maybe?). I trace the shape of the lips in each photo with wire. I construct some sort of 3D body out of the layers of wire lips with more wire, metal, or some malleable but formidable “skeleton” material (chicken wire-esque). I cover it in paper mache.

(Not sure if this is Photoshopped or actual paper mache but this is essentially what I would do.)
Finally I paint it and glaze it. These could get really big, probably a couple feet tall, depending on how much the person says in the video. This technique is way more physically laborious than the first, so I don’t know if I could make more than three or four before the deadline.
I have a few other ideas of differing degrees of automation, but these are the two that I am super excited by. So much so that I really want to do both of them and need help deciding which (if either) works best for this project/this class.
Alternatively, while this would be a shit ton of work, my typology could instead be the differing degrees of automation on one set of lips (mine, saying my own sentence about someone I love). This typology would consist of similar 3D sculptures with the same set of lip shape data, but made with different sculpture materials; while the aforementioned typology would be sculptures of the same material, but of different lips, languages, and loves.
Please help me decide!