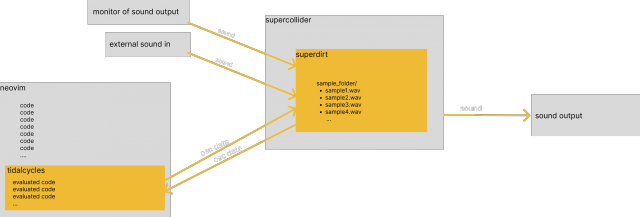
I really like the xy oscilloscope.
It’s a visualization of stereo audio where the left ear’s audio is plotted on the x-axis, and the right ear’s audio is plotted on the y-axis.
This is a modal window.
I enjoy this visualization quite a lot.
These are a couple experiments that exemplify why I like the visualization. The translation is raw enough to see how individual effects applied to the audio literally change its shape. An audio signal is just a series of values oscillating between 0 and 1, so if you have two audio signals, you have enough information to represent those signals with a 2D graph, and see the interesting shapes/forms those signals represent together. If you’re deliberate with your audio, you can even draw pictures:
But I couldn’t be bothered to be deliberate with my audio, so I figured I’d just run an edge detection algorithm on a video feed, turn the detected edges into a series of points, remap those points to a [-1,1] range, and output them as audio. This would let me take video, transform it to 2 channel audio, then graph that 2 channel audio to (somewhat) reconstruct the original video feed.
Initially, I used webcam input for the camera feed, but found that the edge detection required specific lighting to be consistent. Eventually I found a way to instead use video captured from my screen by having obs capture the top-right 600×600 pixels, where I have a window for a screen magnification tool called xzoom, so that I can zoom in on any region of the screen and have it sent as video data to be processed. Here was my final setup
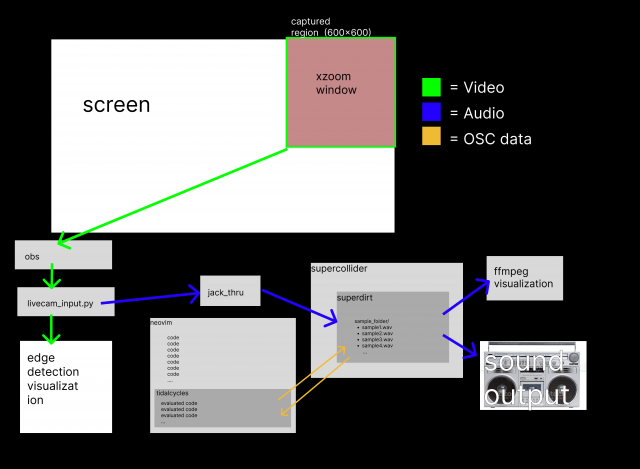
and here’s an xy plot of some audio I recorded with it:
(VOLUME WARNING, THE SOUND IS QUITE HARSH)
Here, I move the zoom around my desktop background and some text in my terminal. You can see a crudely drawn cherry and dollar sign at 1:00, some stars at 1:25, and “excap3” at around 2:15. I’m very happy with how the visuals turned out, and only partially content with the audio. My process for capturing and transforming the video feed was by no means optimal, but I found most of the visual artifacts to be more interesting than obstructive. Why I’m only so-so on the audio requires getting a little technical.
Actually transforming a series of points of detected edges into audio means deciding the order in which you put those points into the audio buffers. Suppose a single frame of edge-detected video gives you like 5000 contour points. Those points represent the video data at one point in time. But in a raw signal, you can’t have 5000 values simultaneously, you can only have one value per channel of audio. You can represent 5000 values in the span of 5000 audio samples, but you have to decide which values to represent first. That decision will define what type of sound you get.
Case in point: the left-channel audio contains much more information than the right-channel audio, because the points are put into the buffer in order of their y-values. This is a consequence of using ‘numpy.nonzero’ to get points from the edge-detected frame of video. The function returns what indices in the frame have non-zero values, ordered top-left to bottom-right by row. The more points detected, the longer it will take to shove all those points through the audio buffer, and the longer it will take to get to the points at the bottom of the image, hence the longer it will take for the values in the right-channel to change. It’s a fairly interesting problem that, if addressed in some future iteration of the project, I think would make the audio much more interesting. However, my issue is mostly with how poorly the sound is distributed. The like the left channel’s sound enough that I’m still fairly happy with my results.
Here’s a short video I did exploring the tool where you can see my entire screen. I’m running the video-generated signal through my Tidalcycles/SuperDirt setup so I can apply effects (no sound warning, the audio is much quieter here).
The code is in an ungodly state, but here are the scripts I ended up using (godspeed if you try to get it working). I hope to optimize/generalize this system somehow in the future, because I’ve found this video->audio pipeline fairly interesting to explore. What do video processing effects sound like? What do audio processing effects look like? Can you turn a pure shape into a pure tone? It ties image and sound together so tightly that it creates its own little subject of study, which is the type of system I love = ]