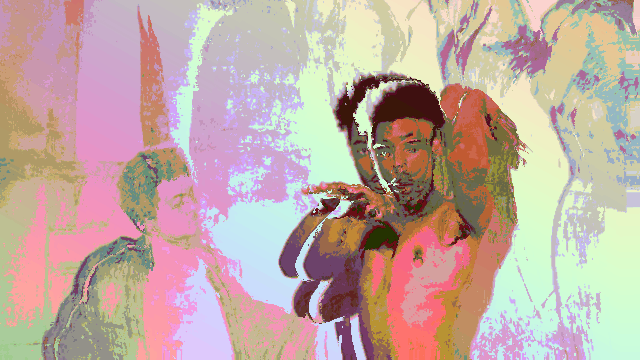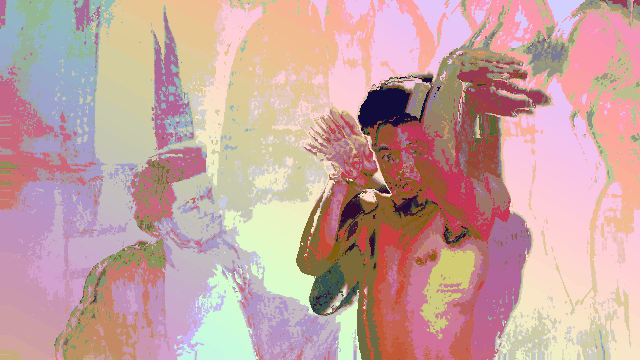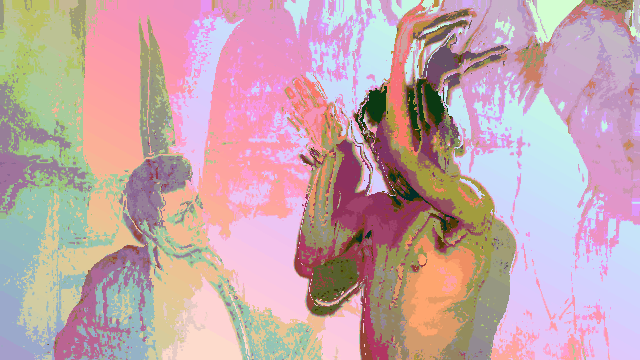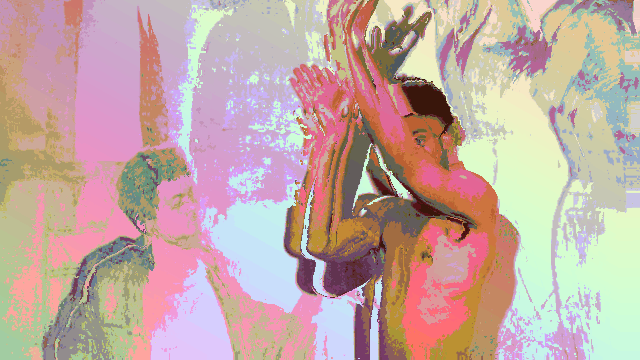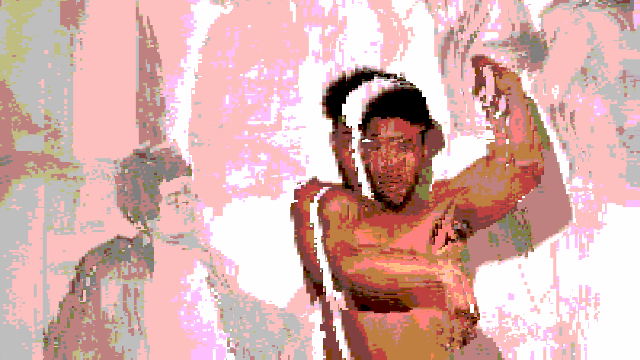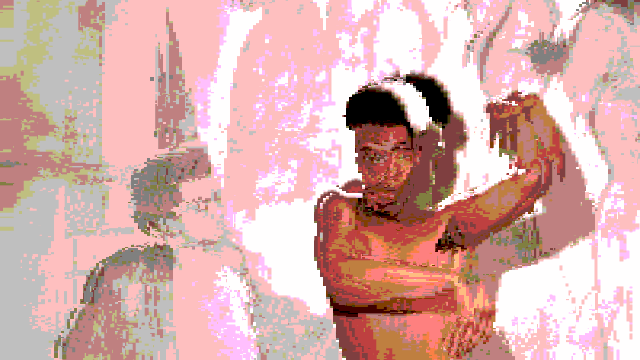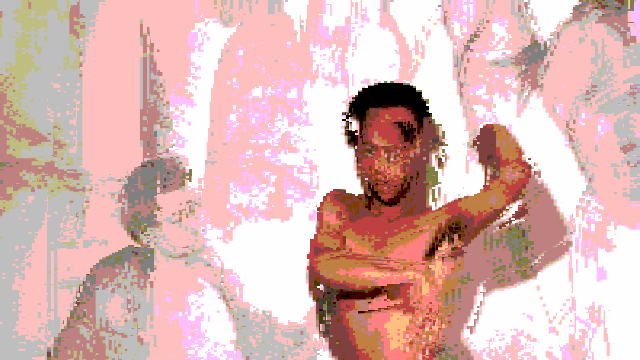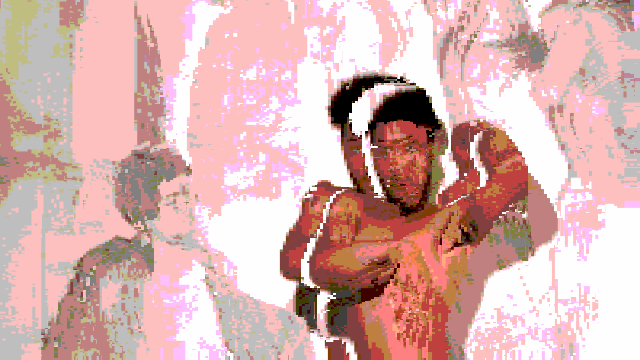Breaking up with a robot after an intimate relationship defined by a lack of dancing.
Rompecorazones (Heartbreaker)
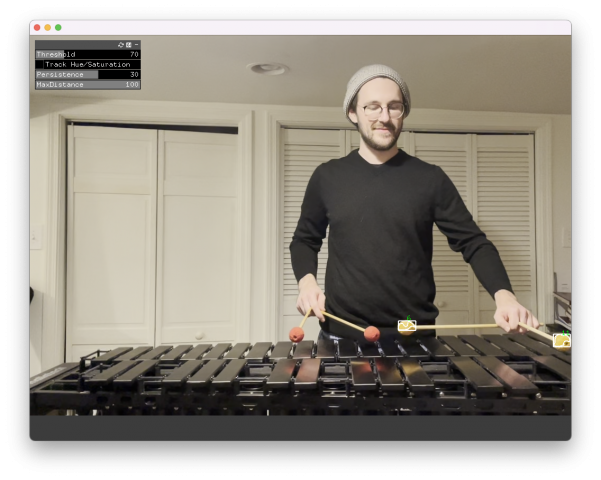
In this video (in case you didn’t watch it), I am wearing a traditional Colombian Cumbia dress as I dramatically break up with a robot.
This project, at it’s core, is a vent piece that contextualizes my failure in attempting to have a robot dance with me.
My Person in Time project, at is core, was creating a robotic interaction that would follow me as I moved or danced with it. But I wasn’t able to get quite there. I spent roughly 2 months continuously debugging a UR5 Cobot (Collaborative Robot), as I attempted to have it follow my face in real time. Using Handsfree.js, python and a couple of dozen cups of coffee, I was able to partially achieve this daunting task.
Without getting too much into the technical implementation of my robotic interactions, I had a lot of issues wrapping my head around different SDK’s and networking protocols for communicating with the robot with my computer. It’s not easy to make code for the robot to move, but it’s even harder to do so remotely from your computer. So I spent a lot of time trying to figure out how these pieces went together. I eventually hacked it, but I realized that to get to a step where the robot would be able to move smoothly with me, would take a lot more time and effort than I had. At this point I had grown bitter with the robot, verbally abusing it every time I could. Because I knew it would never be good enough to properly dance with me at this rate.
Needless to say, this piece as a whole is a testament to the technical failures that I experienced, technical failures that made me consider whether or not I wanted to drop this class at times. This piece was the process of coming to terms with my lack of technical expertise, but it is also a testament to my learning.
In terms of the video, I did consider using music/a background track (specifically of cumbia beats). But the jovial nature of cumbia sounds went against the tone of the video, and I found that my voice alone was appropriate enough for this project. Like any project, I find a billion ways in which my storytelling could be improved. I spent hours trying to figure out how to film myself interacting with the robot, and there are many distinct motions of the robots (as well as bugs) that I didn’t do justice in this documentation.
Special thanks to Oz Ramos, Madeline Gannon, and Golan Levin for helping me get started with the UR5! We developed a special relationship.
Special thanks to Neve (and Clayton), Mikey, Em, Ana, Will, Benford and Lauren for saving my butt with the narrative/filming/set up of the video! I am not a video person, so I genuinely couldn’t have made this without everyone who helped me figure these things out.




 Derek Burnett,
Derek Burnett,