This project aims to visualize the human mind that is susceptible to distraction through the use of eye-tracking technology.
The GIF above illustrates the subject’s repeated attempts to follow the Walking to the Sky sculpture through gaze on CMU campus. The lines represent the trajectory of eye gaze in each attempt. The eye gaze was tracked by a Unity application on Meta Quest Pro. Despite the straight shape of the sculpture, the visualizations show the difficulty of following a straight line in presence of distracting objects in the surroundings.
People often say that the eyes are the window to the soul. When I saw the new release of the eye-tracking feature in one of the newest AR headsets Meta Quest Pro (shown in the picture below), I became interested in using this for the investigation of humans minds, using eye gaze as a proxy to the human mind. For this investigation, I developed a Unity application that tracks the right eye of the user and draws the trajectory of the eye gaze. The app also features record & replay, which generated the output above. The video shows exactly what the wearer sees in the headset. The project and workflow was largely inspired by A Sequence of Lines Traced by Five Hundred Individuals.
Evaluating the current state of the work, it would be better to showcase the idea through a better setup for the recording. My original plan was to build a 3D eye gaze heatmap like this work by Shopify. But only after spending a lot of time experimenting the eye-tracking and passthrough features, I realized this requires a separate 3D model of the space. In the future, I’d like to investigate more into 3D eye gaze tracking and also different implementations of experiments, for example, collaborative gaze work and more scientific investigation into how shared AR artifacts in a space impact people’s perception and experience in the space.
Although people visit and share the same physical space, every one of them gets a unique experience out of the space. For example, members of a household share the living room, dining room, and kitchen, but how they interact with the communal space varies. The same goes for offices, classrooms, or any other shared space.
For my final project, I plan to build an interactive visualization of people’s gaze patterns in a shared space through Mixed Reality. Using Meta Quest Pro, I will collect the eye gazes of people who use the space. Then, after data collection, I will create an overlay visualization of these gaze data mapped on to the 3D model of the space (which will resemble Shopify’s gaze heatmap). Instead of revealing all gaze data at once, however, individual gaze patterns will be revealed only when the viewer looks at the same part, sharing gazes in a similar way to Kyle McDonald’s Sharing Faces. In other words, if you look at something in a 3D scene, and if other people in the same space happened to have looked at the same thing in the past, the system would show what else those people have looked as well.
I’m not sure what the final form of the project would look like yet. It could be an interactive experience in the final exhibition.
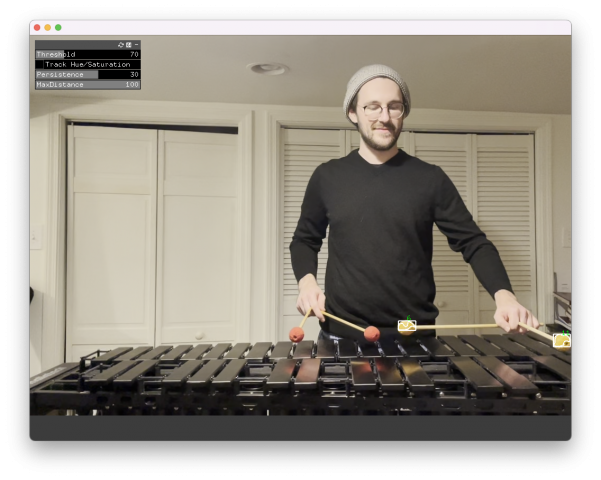
This project captures the quiddity of a vibraphonist embedded in improvised music by presenting the music from mallets’ perspectives.
Music improvisation allows musicians to freely express and communicate their feelings and stories at the moment. For a vibraphonist, two pairs of mallets held by their left and right hands are the main vehicle of their feelings and thoughts. Through deliberate controls of the two pairs of mallets, a vibraphonist forms harmony and composes music.
This project delves into the quiddity of a vibraphonist in the process of improvisation by shifting the perspective to these two pairs of mallets. The system tracks the movements of two mallets and fixes the focus on each pair of mallets. This project is inspired by Evan Roth’s White Glove Tracking.
Evan Roth’s White Glove Tracking project
To be more specific, the system works in the following steps. The steps are visualized in the video below.
The software built with OpenFrameworks tracks red and yellow blobs separately as shown in the picture below. In the picture, you can see white bounding boxes with green labels around the yellow mallet heads. The software uses ofxOpenCv, ofxCv, and ofxGui packages for tracking and parameter adjustment.
Based on the positions of two mallet heads, the software rotates, scales, and translates the video so that the pair of mallets is always centered with the same distance.
I used Adobe Premiere Pro to composite the two red mallet-centered and yellow mallet-centered videos.
For additional exploration, I tried out different visual effects in an attempt to simulate the improvisation process inside the vibraphonist’s head — for example, splitting the screen into left and right cuts, overlaying the two sides, and flipping the videos upside down as if we’re looking through the vibraphonist’s eyes.
This mallet-centered view of improvisational music reveals the quiddity of the vibraphonist more than still photos or normal videos.
The opening cut refers to “what was done” or the act of “trying out,” and the closing cut is the observation of “what happened.”
In my Typology Machine project (interactive disclosure of audio-visual discrepancy), users trying out the VR prototype (removing black bubbles one by one) would be the opening cut. Their response to the act, involving their feelings and perception, would be “what happened” as a result.
This project reveals the discrepancy between auditory and visual perceptions of humans by exploring a collection of contrasting experiences in perceiving the world with or without visual information.
Seeing is believing.
As the saying goes, vision dominates how we perceive the world for many of us. When the visual channel is not available, we rely on other sensory channels such as the auditory sensation, often attempting to visualize the scenes in mind based on these signals.
But how accurately can we reconstruct the world without vision? How reliable is the auditory channel as a medium to perceive the world? How dominant is vision really in how we experience the world?
Typology Machine
To answer these questions, I built a typology machine (Figure 3) to capture these contrasting experiences, which functions in three steps.
Real-world scene construction with auditory and visual out-of-place cues.
360° spatial capture.
Interactive Virtual Reality (VR) software.
1. Real-world scene construction with auditory and visual out-of-place cues
I set up a real-world scene where an out-of-place cue exists in both visual and auditory channels. For example, in a grass yard, there is an angry stuffed seal and the sound of flushing the toilet. I placed the visual out-of-place cue in the scene, and I played the auditory out-of-place sound from a smartphone placed at the same location as the visual cue. I constructed four scenes (see Figure 1 and 3). In all scenes, the visual out-of-place cue remained the same — the angry stuffed seal, but the audio cue varied.
A. Parking lot: There were ambient bugs and car sounds. As an auditory out-of-place cue, the sound of seagulls and waves was used.
B. Grass yard: There were ambient birds and people sounds. As an auditory out-of-place cue, the sound of toilet flushing was used.
C. Office with no windows: Quiet space with no ambient sounds and no natural lighting. As an auditory out-of-place auditory cue, the sound of birds singing was used.
D. Patio with pathways: There were ambient birds and people sounds. As an auditory out-of-place cue, the sound of angry dogs barking was used.
Figure 1. Spatial capture setup using dual-mounted 360° camera and ambisonic microphone. First row left: (A) parking lot, right: (B) grass yard. Second row left: (C) office with no windows, right: (D) patio with pathways.
2. 360° spatial capture
In the center of the scene is placed dual-mounted 360° camera (Mi Sphere Camera) and ambisonic microphone (Zoom H3-VR) to record 3D spatial scape of the world, as shown in Figure 1 and 2. (An ambisonic microphone captures the full 360° around the microphone, representing the surround soundscape at a point.)
Figure 2. Close-up of dual-mounted 360° camera and ambisonic microphone setup.
3. Interactive Virtual Reality (VR) software
I built a Virtual Reality (VR) software that reconstructs the scene captured in Step 2 and presents the contrasting experiences. I developed the software for use in Oculus Quest 2 headsets. In the virtual scene, the player first enters a black spherical space with only sound. By listening to the sound, the player imagines where they are. Then, by clicking parts of the surrounding black sphere, they can remove the blocking parts and unveil the visual world. The video in Figure 3 demonstrates the VR experiences in four scenes with out-of-place visual and audio cues.
Figure 3. Spatial capture setup using dual-mounted 360° camera and ambisonic microphone in four scenes.
Findings
The main finding from the collected demonstrations of contrasting experiences is that an auditory out-of-place cue (e.g., the sound of seagulls in a parking lot, toilet flushing in a grass yard, and birds singing in an office with no windows) can completely deceive the user where they are, without the presence of visual information. In the first scene of the video (Figure 3), the parking lot could be deceived as a beach with seagulls. In the second scene, an outdoor grass yard could be deceived as a bathroom with toilet flushing. In the third scene, an indoor office could be deceived as a forest with sunshine. In the fourth scene, the incongruence is less so, but a peaceful patio could be deceived as a place with a more imminent threat from angry dogs growling.
On the other hand, a visual out-of-place cue (e.g., the stuffed seal) does not change the perception of where the user is. It makes the user think that it’s odd that the stuffed seal is there, not the other way around.
This highlights the difference in the richness of ambient or peripheral information in visual and auditory channels. As shown in the video (Figure 3), ambient audio is preserved such as the sounds of bugs, birds, people, cars passing by, etc. However, one out-of-place cue with strong characteristics is dominant enough to overshadow other ambient cues. Only until the visual channel becomes available. In the visual channel, the full context of the scene appeals more to the perception of the location rather than a single out-of-place cue — the stuffed seal.
The finding was reinforced by people who experienced VR software. For example, in the reaction video below (Figure 4), the person first thinks he is on the beach given the sound of seagulls (00:13). Later, as he reveals the visual information, he not only realizes he is in a parking lot under a bridge but also now thinks the sound of waves was actually the sound of cars passing by (01:20). He modifies his previous understanding of the auditory cue(sound of waves) to fit the newly obtained visual information. This exemplifies the dominance of visual information in human perception of the world.
Figure 4. Example reaction of a person trying the VR software.
Furthermore, this wasn’t captured in the video, unfortunately, but later while unfolding after the VR experience, the person explained that he first thought it was a seal, but he hesitated to say it (03:40) because it sounded “too stupid to say there’s a seal” even though he did talk about my coat under the seal. This hints at possible differences in the mechanisms of human auditory and visual perceptions. While one strong cue can be dominant in auditory perception, the combination of ambient information might appeal stronger in visual perception.
In summary, this collection of interactive sensory experiences reveals the contrasts between auditory and visual perceptions of humans.
Reflections
Inspirations and Development of the Project
I started the project with a broad interest in capturing one’s experience fully through technology. Then, it triggered my curiosity about how much information spatial sound could carry about one’s experience and memory.
Before designing the specific details of the apparatus, I conducted some initial explorations. I first wanted to feel what it is like to make a digital copy of a real-life experience. I brought the Zoom H3-VR ambisonic microphone to different places such as a public park with people and wild animals, a harbor, an airport, a kitchen, etc. Tinkering with the ambisonic audio, I realized that, unlike my expectations, the ambient sound rarely contains auditory cues that give a clue about the space. Also because these cues are so rare, one distinctive cue could easily deceive a person. Inspired by this, I started designing a VR interactive media where the participants could (verbatim) unveil the discrepancy between our dominant visual channel and supportive auditory channel, which developed into the final design described above.
Self-Evaluation: Challenges, Opportunities, and Learnings
Throughout the process, I encountered several challenges due to my underestimation. Technically, I thought the implementation would take only a brief amount of time since I have some experience in building AR software. However, using new hardware (Oculus Quest 2), software platforms, and new types of data (ambisonic audio and video) was more struggling than I thought, which consumed a lot of my time in building the apparatus itself. Especially, development using a fast-growing platform like Oculus meant a lot of deprecated documents online and having to figure out issues with recent updates through a series of trial and error.
If the apparatus building took less time, I would have explored more diverse scene settings and visual out-of-place cues). More user studies and another collection of people’s reactions to facing the discrepancy would have been insightful as well. Through iterations, the design of the experience itself could be improved too to exhibit the contrasting perception in a more straightforward way.
I personally learned a lot through the execution of the project. I learned the differences in auditory and visual perceptions through the collection of immersive contrasting experiences. Technically, I learned how ambisonics work, how to use 360° visual and ambisonic captures in VR, and VR development in general.
Lastly, I learned that for successful 360° video filming, I always need to find somewhere to hide myself in advance. 🙂
The reading explains different processes of generation photographic emulsions, which were new to me. It is interesting to see how multiple factors impact the generated photo. In order to obtain objective representations of a physical event as photographic images, careful crafting of different parameters is required, in which one’s photography skills impact the “objective” outcome.
It seems these methodological/scientific/scientistic approaches to imaging involve and require more rigorous criteria on the condition of the subject. In digital photography (which we use every day), the purpose is to capture what human eyes can see, so it doesn’t require the subject to be in a certain condition (if we disregard social and ethical norms). However, in scientific imaging, the goal is broader — to make the invisible visible. It extends beyond the human level of vision; for that, the state of the specimen (e.g., dry or wet) determines how it would appear in the captured image.
The Portals series by Anthony James Studio presents sculptures made of stainless steel, glass, and LED lights shown in the video. The glass and LED lights are placed in a structured way that creates recurring geometric patterns to infinity through chains of light reflection.
The Portals immerses viewers into an infinite space of light and geometry. The space inside the frame remains still and fixed as the viewers move around the sculpture. It is interesting to note how this creates an optical illusion that this infinite, otherworldly universe is captured in a confined steel frame. It is a mesmerizing experience as if the viewers are observing another universe as an outsider.
The current Portals series uses an unfamiliar subject (bright LED lights forming geometric shapes) that does not exist naturally in our world. I wonder how this concept of confined infinity would immerse viewers differently when the recurring subject inside the frame is something more realistic or personalized experience, for example, a fraction of one’s experience captured through a camera.