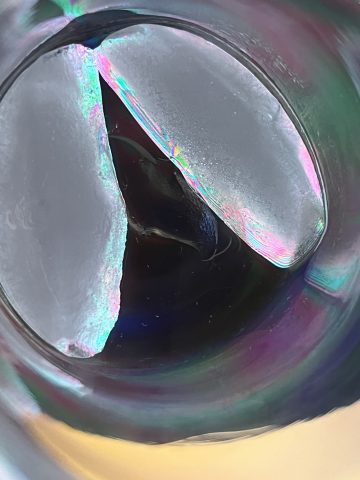What: I want to 3D scan a mass-produced whole Chicken from the market and animate it using motion capture data from a real live chicken.
Why: I wanted to explore the relationship between us and our food in the context of consumerism and industrialized animal production. Many of us are born into a highly industrialized meat industry where we don’t see the meat and other animal products we consume as parts of a living animal but as a product no different from a roll of toilet paper. Many of us would happily enjoy a steak but could not bear to see the slaughtering of the animal. This phenomenon goes beyond the animal industry and many parallels could be drawn between this and the way we use products that were produced in an inhumane or irresponsible manner.
How: well, this is the hard part. 3D scanning a Chicken shouldn’t be that difficult. I swear I saw somewhere that CFA has 2 3D scanners for lending but I couldn’t find it anymore. Photogrammetry is the plan for now. The original plan for mocaping a chicken is to rent a chicken for a week or so from rentthechicken.com and use a combination of chicken helmets and chicken harnesses or chicken jackets and some hair ties/adhesive to affix tracking dots onto the chicken. But it seems like there are greater concerns:
PLAN A1:
Map human mocap data to a 3D-scanned chicken. Would convey a very different message (along the lines of imposing our will on the animals we raise for food and romanticizing animal farming) but a lot more manageable technically.
Plan B: Photos for the Golden Record
What: I want to set up a questionnaire asking people if they were to explain the concept of war, disease, religion, oppression, etc. to an alien without using language in one or a few images, what image would they choose and/or create. I would then try to find those images or create their vision using a generative tool (like midjourney.)
Why: I was inspired by the 120 or so images that NASA chose to include on the Golden Record aboard Voyager 2 that are supposed to give a summarization of humanity. You can watch this video if you are interested.
It was a deliberate choice of the committee to leave out any images about war, disease, religion, etc. I’m interested in seeing what people would include if we do want to describe these concepts to extraterrestrial civilizations. The idea behind using a generative tool is to leverage this collection of human visual storytelling instead of relying on my personal creation which is more prone to biases and more importantly, the absolute lack of skill.
How: I want to make a website (or Google forms if I wanna make it low effort) that briefly introduces the premises and ask people to give a short description of the images that they would include for a randomly chosen concept (or should I let them choose, or let them come up with their own topic without giving any prompts?) I would then compile the responses, do some filtering, feed them into midjourney, and pick an output that best renders the original description.
Plan B1:
Make a fake Golden record where for each of the 120 images on the Golden record, I produce an image, through photography, drawing, or AI generation, that represents the incorrect message. Commenting on the inherent fallacy of representation and the act of summarization.
PLAN B2:
Make a Golden record by crowdsourcing images that people think are not important to humanity. Would be a flip of the original record in another way.
I’ve been playing around with a few things unrelated to the deliverables and at Golan’s request, will put the results here.
Slitscanning(ish) (slow motion)Video
Algorithm: for the i-th column of the video, take every i-th frame of the original video. (e.g. the right-most column is playing at c * 1024 FPS and the left-most column is playing at c FPS for some constant c.) Hold the last frame if a given column runs out of frames.
Shot on the edgertronic.
Digital NIR false color
The goal is to recreate the look of Aerochrome using a NIR digital camera.
Algorithm: take two photos of the same scene, one with IR high pass filter and a low pass filter. The first one with the low pass is a regular RGB photo and the high pass will give 1 NIR channel (effectively). Then use NIR channel for R, R for B, B for G in constructing a new image.
What are you seeing: a timelapse overlaid onto a slo-mo shot at the same location.
This is not the final version I had envisioned because I made a mistake when I was shooting the scene I had in mind for the final version yesterday and didn’t have time to reshoot. The following are frames of the footage I shot for the final version. I would have myself walking across the frame in slow motion while other people pass by me (along the same path) in a timelapse. It’s the exact same capture machinery as the test footage but the subjects align more with what I want to convey with my work.
Ideation
From an experimental capture perspective, I want to experiment with compositing different speeds of time and temporally distinct occurrences of events in the same video. I was inspired by the visuals of timelapse and hyper-lapse that contain a still subject in contrast with the sped-up subjects (see sample image below. I want to further this idea by developing a method of slowing down the subject beyond real-time and a tool that would) allow me to pick the subject and overlap it with the sped-up subjects as I wish.
From a conceptual perspective, I want to explore our perception of the speed of time’s passage and our linear understanding of the sequence of events. By contracting the past and the future into a microscopic examination of the present (i.e. by condensing the people before me and people after me into the magnified present moment of me walking along the path,) I attempt to question our place and significance when put in perspective with the grand scheme of time and examine the relationship between the past, the present, and the future.
Process
The basic idea behind this is to find a composition where the subjects I want to speed up are in front of the subjects I want to slow down (the reverse would work too but is less ideal due to the current state of AI.) Ideally, there should be no penetration of slow and fast subjects in the 3D space — 2D space is obviously fine as that is the whole point of developing this method (this is something that happened in the test footage where people penetrated the car that I attempted to fix in the second footage.) Then I would have two temporally distinct sequences, with the same composition, one of the slow subjects and one of the fast subjects. I would then rotoscope out the subjects of interest from the footage I want to speed up. Here, I used a semantic segmentation model (DeepLab’s Resnet 101 trained on a subset of COCO that matches PASCAL) to mask out anything that is not human. All that is left to do from here is to alpha-blend the extracted human overlay onto the slow-motion video.
luminance_trail_demo
Video Player is loading.
Current Time 0:00
/
Duration -:-
Loaded: 0%
0:00
Stream Type LIVE
Remaining Time --:-
1x
Chapters
descriptions off, selected
captions settings, opens captions settings dialog
captions off, selected
This is a modal window.
The media could not be loaded, either because the server or network failed or because the format is not supported.
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
Embed: Start at:
^ your device may or may not support the format of this video above, use your imagination if it doesn’t
segmentation_demo
Video Player is loading.
Current Time 0:00
/
Duration -:-
Loaded: 0%
0:00
Stream Type LIVE
Remaining Time --:-
1x
Chapters
descriptions off, selected
captions settings, opens captions settings dialog
captions off, selected
This is a modal window.
The media could not be loaded, either because the server or network failed or because the format is not supported.
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
Embed: Start at:
^ your device may or may not support the format of this video above, use your imagination if it doesn’t
There are, however, some details one has to deal with when implementing this algorithm. For one, the segmentation result is not perfect (actually, pretty awful.) One way that happens to mitigate this issue is faking a long exposure from multiple frames (i.e. hyperlapse.) I didn’t spend too much time on this but got some decent results by simply applying a Gaussian filter and a convolution with a horizontal-line filter before blending ~100 frames together by pixel-wise maximum (similar to “lighten” in photoshop.) One could also use background subtraction on the masked region, cluster the pixels and filter out small ones, run Canny edge detection to get a sharper edge, etc. I didn’t really have time to debug those so I chose to use the segmentation results as is. There were also some other issues, such as dealing with the computational cost of Resnet inference on large frames (takes ~16G of vram to process a 3K video in FP16) and figuring out the right equation for the right blending mode but they are not worth discussing in detail.
I know what I want to try and experiment with in this project but I don’t have a very concrete concept or a particular idea yet. I do have a few thoughts.
What I want to try: cinematic slow motion video capture of people. I want to explore the possibility of making cinematic shots of people using ultra slo-mo cameras (going beyond what’s usually seen in movies.)
Thoughts/potential ideas:
Capturing people’s expressions and actions when they are hanging out with friends. When people place themselves in a social environment, a lot is going on very fast with their micro expressions and minute actions, which are usually overlooked by other participants of the same social interaction. By recording the interaction with a high-speed camera (~700fps,) I want to capture these moments and present them in a short film that encapsulates an encounter in a different way (as opposed to capturing the content of their conversation, which is the usual view.) Also entertaining the possibility of using the robot arm to introduce fast (but normal speed when viewed in slow motion) camera movements, but the distraction of a gigantic robot arm swinging at 2m/s just a few feet away needs to be considered carefully.
Heartbeat city: capturing the AC flickering of city lights reduced to heart rate as people passes by. This should be around 1300fps (24fps * 60hz * 60 / 70bpm) although I could do slower. At this fps, people are barely moving. So the usually static city will have more actions then the usually dynamic human, flipping the common perception of the mobile vs the static.
This project is a technical experiment where I attempted to use a polarization camera to separate the reflection on a glass window pane from the light coming from the inside so I can present a 2-channel video of the inside and the outside space side by side.
0
Video Player is loading.
Current Time 0:00
/
Duration -:-
Loaded: 0%
0:00
Stream Type LIVE
Remaining Time --:-
1x
Chapters
descriptions off, selected
captions settings, opens captions settings dialog
captions off, selected
This is a modal window.
The media could not be loaded, either because the server or network failed or because the format is not supported.
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
Embed: Start at:
This is a tool-driven project. I was given a very cool camera and thought it would be fun to make something with it (also a good challenge.) It is a polarization camera, which captures the 4 polarizations of light simultaneously with a special sensor that has polarization filters of 0, 45, 90, and 135 degrees on its Bayer filter rather than red pass, green pass, and blues pass filters designed to make a colored image.
I was initially inspired by how polarizers are used to eliminate reflections and glares with water and glass in photography. I thought it would be interesting to capture the duality of windows — that it lets light through while reflecting it at the same time, that it lets us see ourselves and others at the same time, and that it separates (by physically dividing) and unifies (by combining two images on to one surface) two spaces at the same time. By capturing one video clip of one surface and separating it into two channels to be presented side by side, the contrast between these two different yet intermingling images investigates the simultaneity and unity of different moments and spaces.
My workflow:
Find an interesting window.
Set up the camera in front of it in a way that my own reflection cannot be seen.
Record a ~10s clip.
In post-processing, choose 2 channels that capture the outside and the inside with the best separation (usually 0 and 90 degs.)
Enhance the difference between the two frames and adjust them so that they look as similar as possible visually while having the largest achievable separation between the outside and the inside.
Present them as a 2-channel video.
Further work:
This project focused more on the experimentation of tools and processes rather than the soundness of concepts. It is quite weak as far as typology and content go. I have a few ideas in mind that could make the content more interesting. When I’m in a big city like NYC, I’m always fascinated by the stark contrast between the inside and the outside — the pristine inside of corporate lobbies and the sticky street where the homeless take shelter separated only by a sheet of glass.
A stock photograph to illustrate what I mean: https://www.alamy.com/stock-photo/homeless-man-sleeping-in-shop-window.html
As for the capturing process, I think 2 regular cameras with polarizing filters might work better than the FLIR Blackfly. The black fly does not allow for precise adjustments of the filter angle on the field so it’s hard to gauge the success until I get into cv2. Having two regular cameras would also allow me to capture color.
The main challenge I encountered was the balance of light. If either the inside or the reflection was too bright at any spots, it overpowers the other and wipes out any information from the other side. Essentially, unless the light is very balanced across the frame, at any given pixel, I can only capture one of the sides. One idea I had to combat that was to match the FPS with the grid’s AC frequency. LED lights usually flicker at 120HZ with a 60HZ grid and dip to less than 10% peak luminosity at their dimmest points. So if I can record at 240fps or higher when the ambient light is low (blue hour or later), I can easily pick out all the darkest frames (which would have most of the reflection) and the brightest frames (which would have the most of the inside.) This can also be used in combination with polarization.
I looked through IEEE explore and ACM library but found very little literature on this topic, which was very surprising since glare reduction via polarization filters seems to be a very useful thing to do in the industry. I’m sure there are better algorithms to utilize the data I have than the stuff I came up with. If anyone knows anything about this please let me know:)
Additional information:
The Degree of polarization map (L) and Angle of polarization map (R) I calculated from the 4 channels using this repo: https://github.com/elerac/polanalyser Didn’t find any good uses for this information.
The idea I have right now might be a little cheesy (not the best way to start a proposal, I know. But I do want some help in gauging this.)
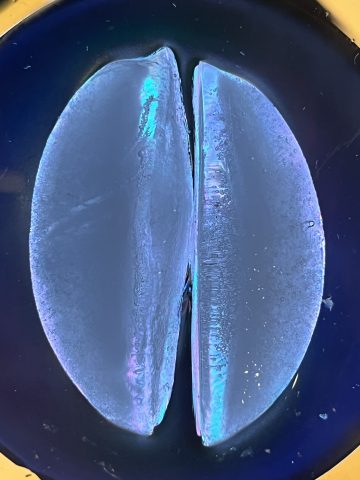
The idea was inspired by how we can use polarization to reveal the internal stress of transparent materials. I want to ask a handful of people to collect their tear (small amounts: <0.5ml, in a plastic vial.) I’ll then transfer them on to microscope slides, freeze them into an ice droplet, and image them between two polarization filters on the light table under a microscope (or a powerful macro lens (at least 2:1.) I’m debating between photograph and video. Video might be cool since the pattern only exist in ice, so it will slowly disappear as the ice melts into water.
Test 1: stress of glass under polarized light. You can see the white pattern show up as I apply pressure on the stem.
IMG_0703
Video Player is loading.
Current Time 0:00
/
Duration -:-
Loaded: 0%
0:00
Stream Type LIVE
Remaining Time --:-
1x
Chapters
descriptions off, selected
captions settings, opens captions settings dialog
captions off, selected
This is a modal window.
The media could not be loaded, either because the server or network failed or because the format is not supported.
Beginning of dialog window. Escape will cancel and close the window.
End of dialog window.
Embed: Start at:
Test 2: Ice cubes under polarized light.
Presentation ideas:
The idea is to metaphorically reveal the stress and emotion behind the tears and observe their slow dissolution as the ice forms into a tear drop. (To my knowledge, the polarization setup does not actually reveal the stress in ice, it should just be some optical effects that results from the surface of ice.) That’s where I feel a little unsure about this idea. The other issue is that the audience have to know the fact that a polarization set up is used to visualize stress in glass and plastic in order to follow the logic behind this piece.
I’ve also been playing with the polarization camera but haven’t found much use within the scope of this idea. But I’m still playing around with it to see if I can find anything else interesting to do with that camera.
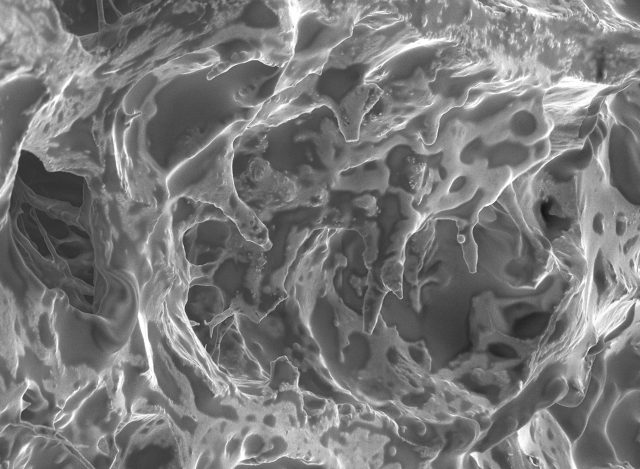
The two objects I chose are a light roast Ethiopian coffee bean and a piece of developed BW 400 film. The film is pretty boring — just a flat surface. According to Donna, the silver particles are apparently too small for the SEM. But the coffee was super interesting with a variety of textures and internal structures. The images below are focus stacked from 8~15 shots.
This article is quite eye-opening to me. Typically, photography for science is not covered as a part of the early history of photography. In fact, I just went back and flipped through the first few chapter of A World History of Photography and did not find any mentions of scientific photography — the age of daguerreotype is just a boring collection of portraits. I found it fascinating that they were able to take wet plate collodion on transatlantic expeditions as it is a painfully finicky process. I was in fact shocked that they were able to capture images of remote, dim celestial objects (even modern cameras require something like ISO 3200 and motorized star tracker gimbals, and wet plates’ ISO is usually below 10.) Seeing the power (and limitations) of early photographic technology and their applications, it really made me rethink the connection between art and science in the early ages of photography.
To me, the extreme scales at which modern imaging technology is capable of present many artistic opportunities. On the large side, satellites, drones, street views, etc. provides us with an unprecedented amount of data that can be utilized in art. Especially we the help of big-data processing tools (such as efficient object recognition,) it is possible to create a typological study without ever going to the place in person (e.g. using algorithms to sift through massive street view databases to find the object of interest.) On the small scale, high-definition optical microscopes and SEMs gave us many new opportunities to find interesting visuals at a completely different scale. Bio art, for example, is an interesting field that can potentially benefit from the ability to see tiny structures.