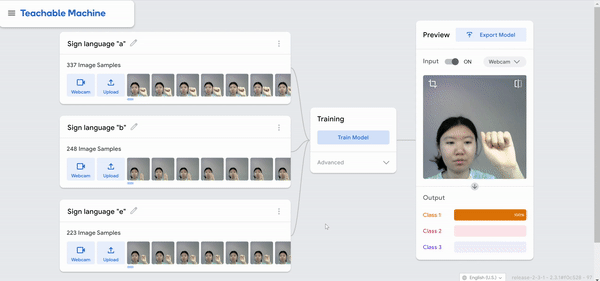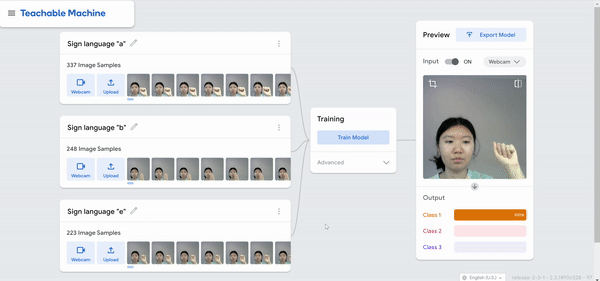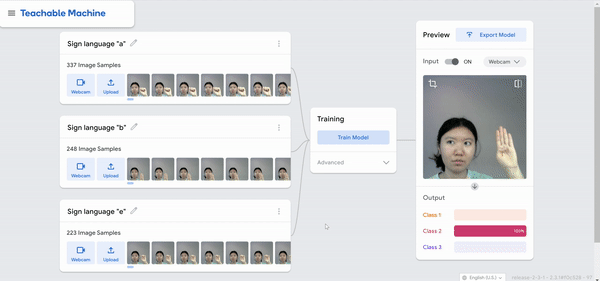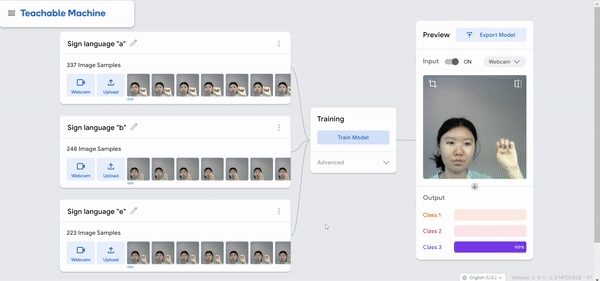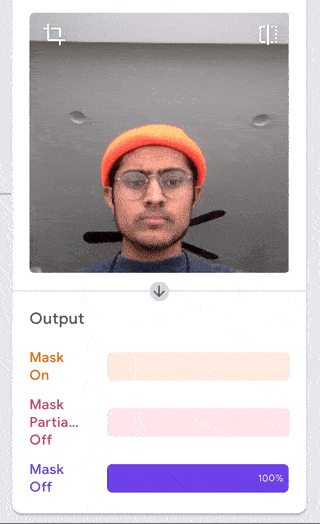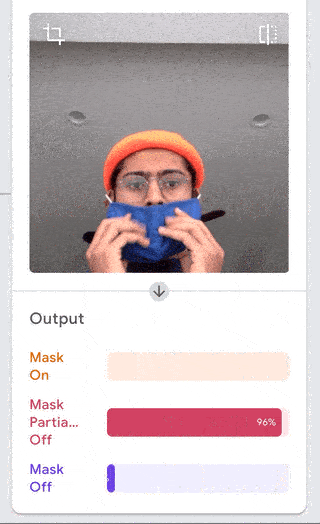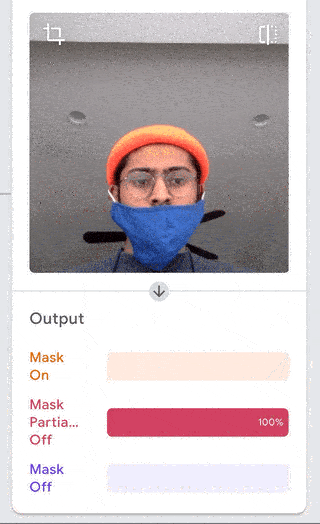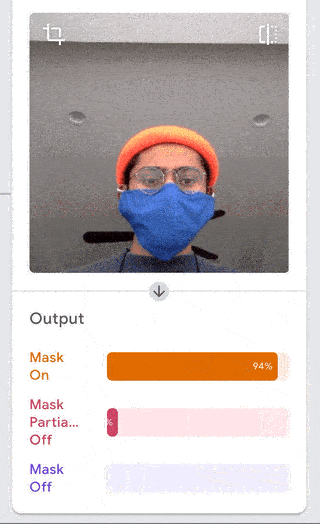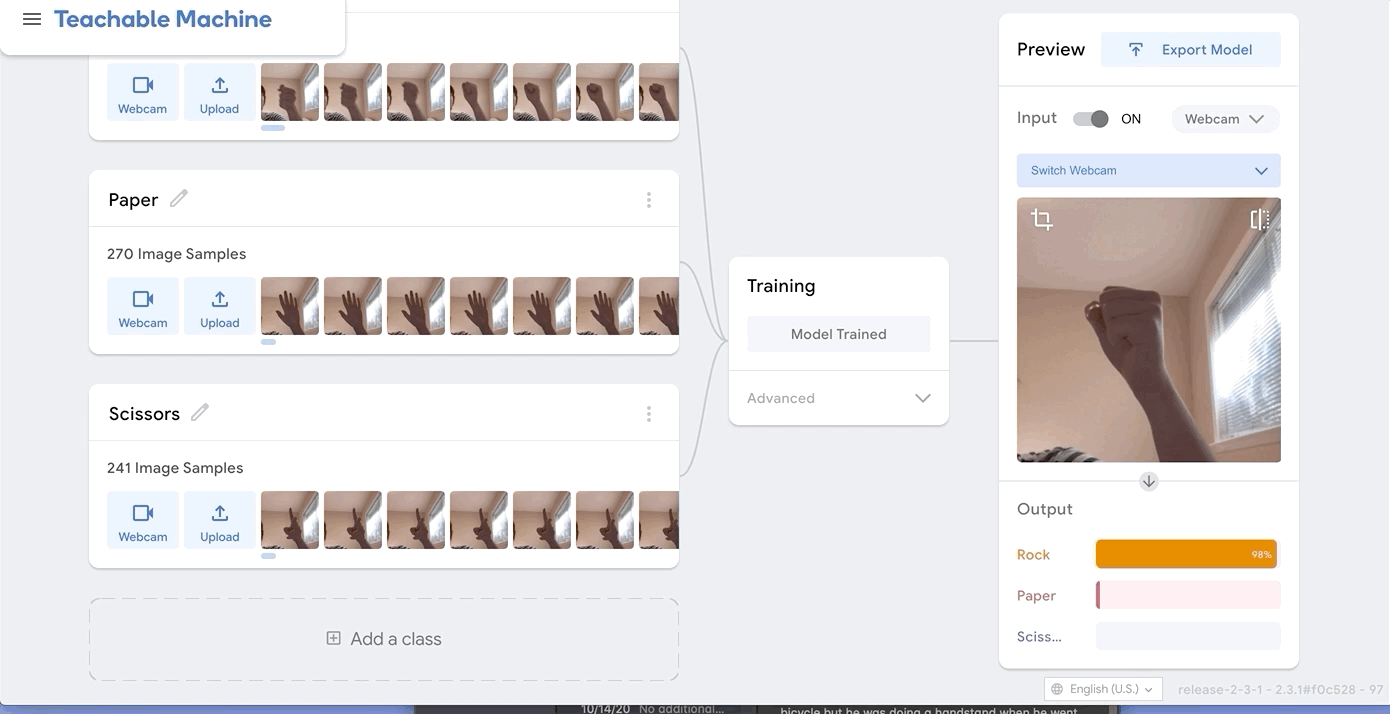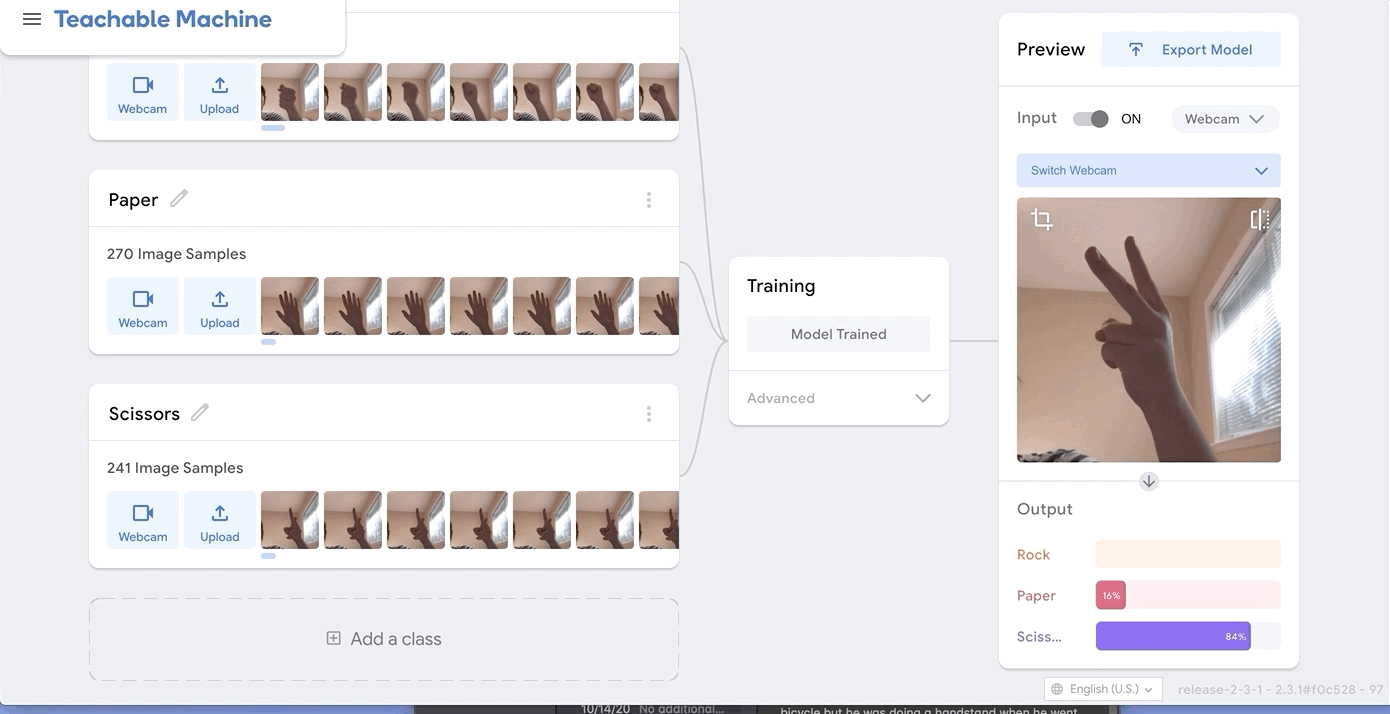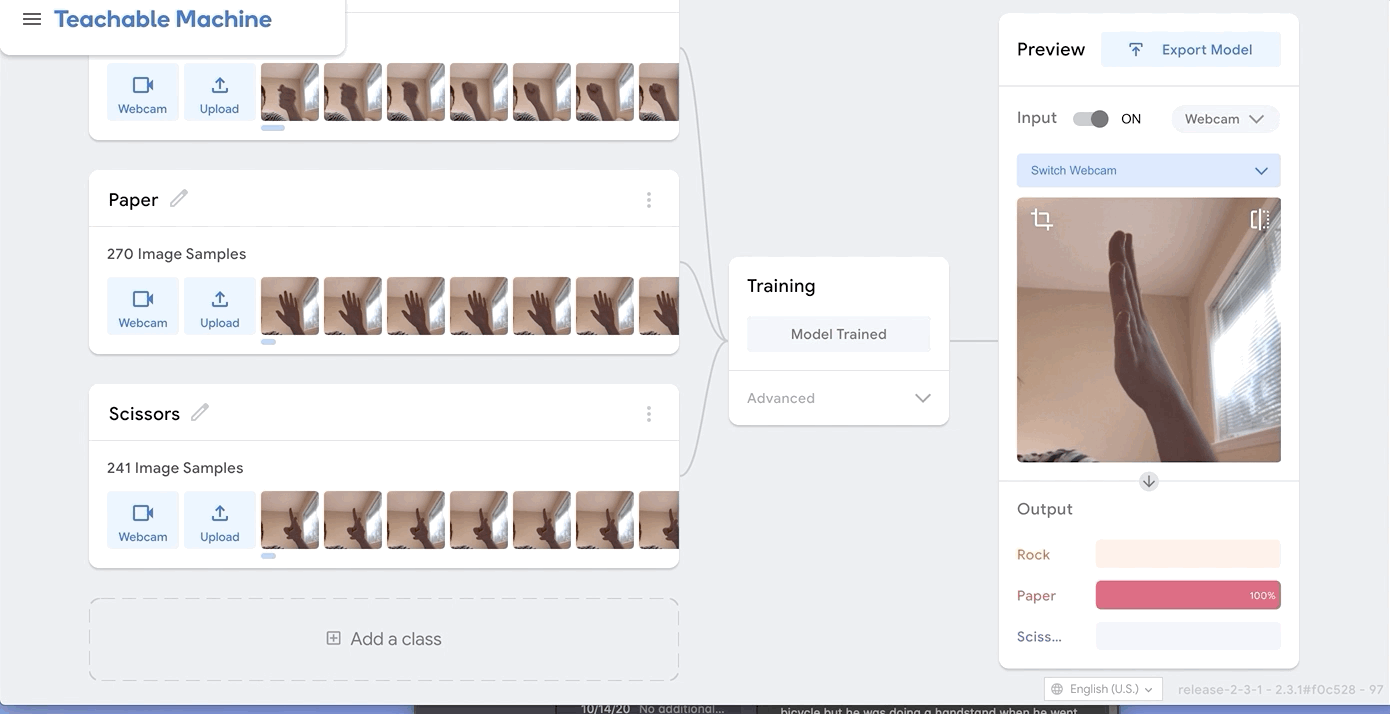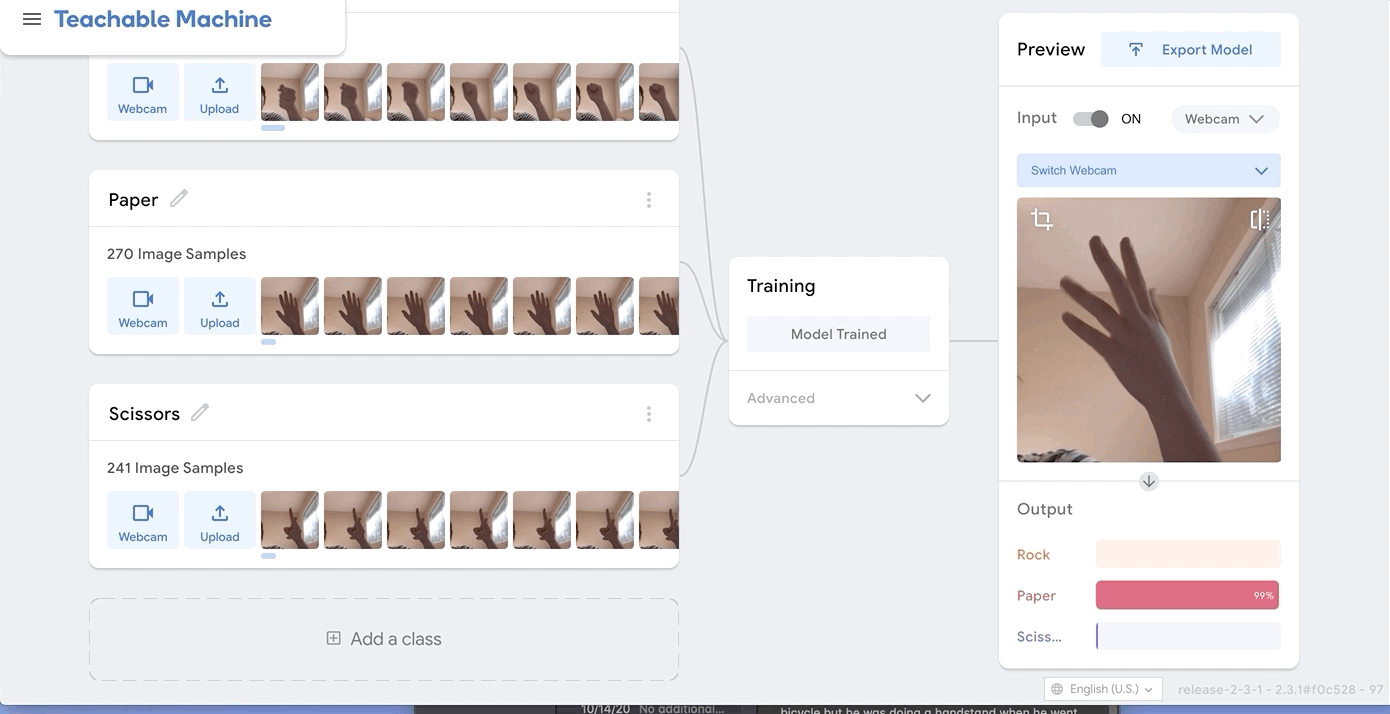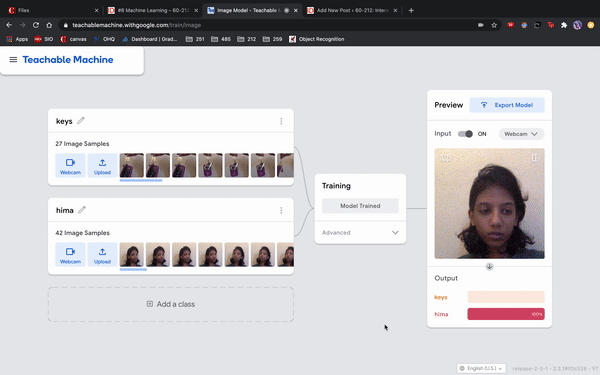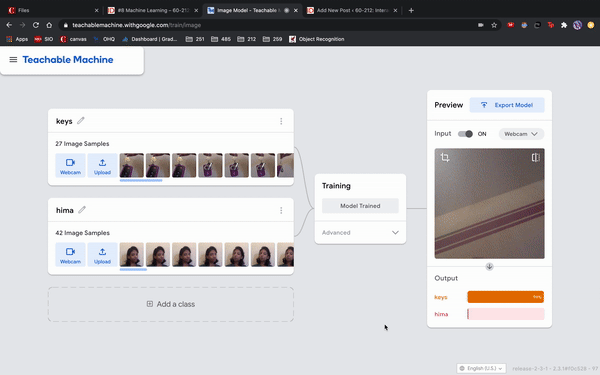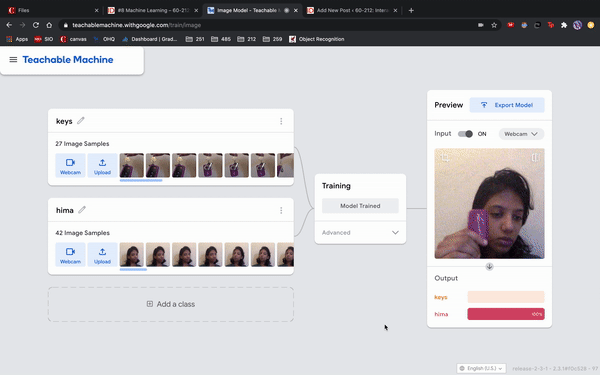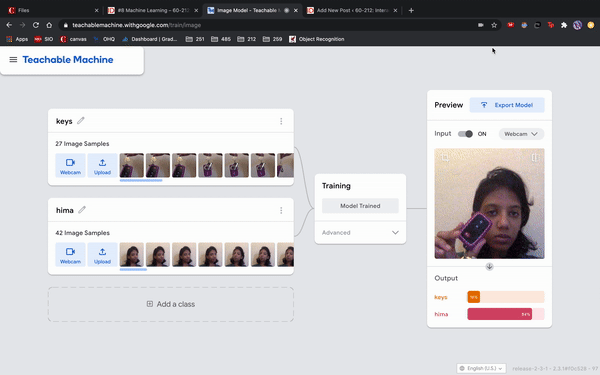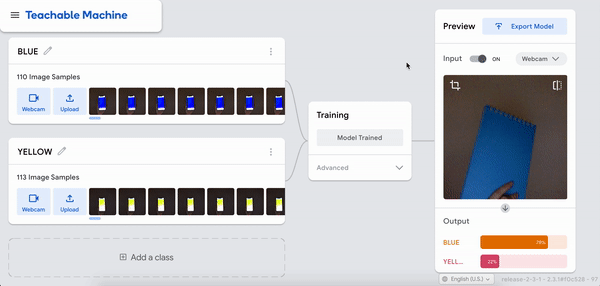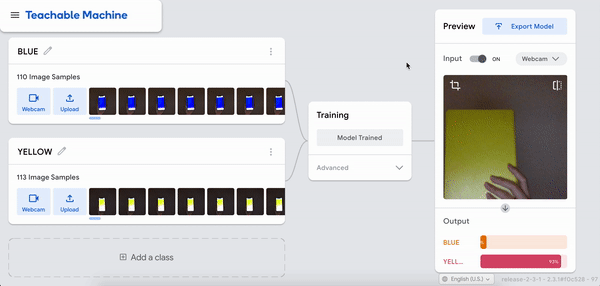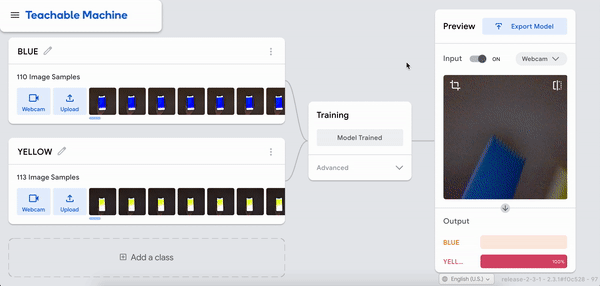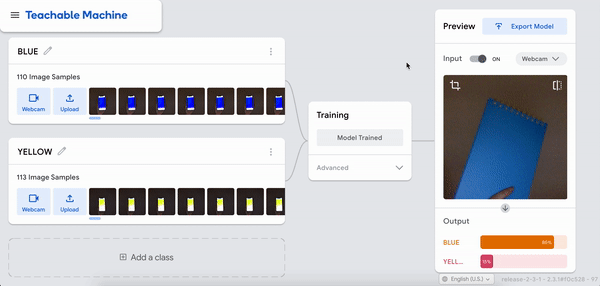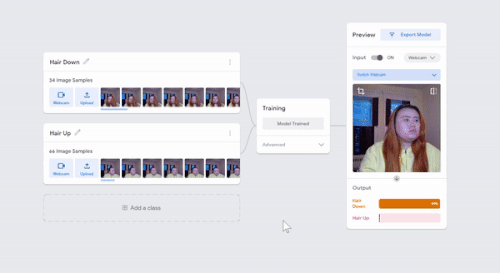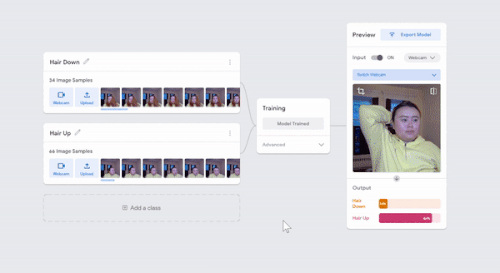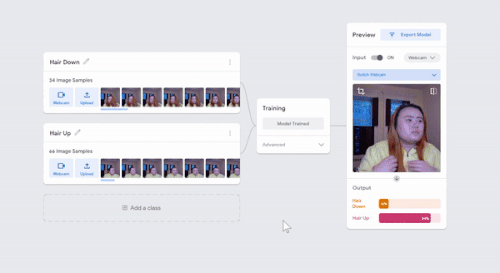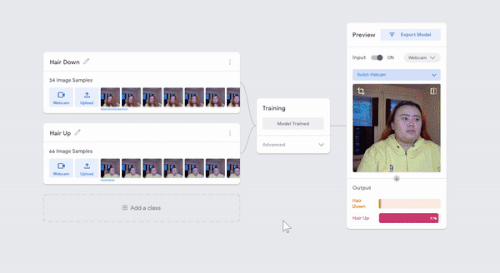
I was just playing around with Teachable Machine, and I found it hard to come up with something cool that I could do with just one hand or no hands (because one hand has to be holding down the webcam button). My first idea was to do hand puppets but I found out most hand puppets require two hands to make the animal, so I decided to do something very simple.
I have 2 classes: one with my hair down, and one with my hair tied back with a ponytail. I kept it simple to train so I could see what it would categorize any gray areas. For example, in the video I tested out one with all my hair down, then my hair moved back without tying it up, using my hand to gather my hair into a ponytail, and then I also tested out how much hair I need to keep in the front to register as class 1. This was a fun and simple experience to do for like 10 minutes!