Concept
Whiteboards and other hand drawn diagrams are an integral part of day to day life for designers, engineers, and business people of all types. They bridge the gap between the capabilities of formal language and human experience, and have existed as a part of human communication for thousands of years.
However powerful they may be, drawings are dependent on the observer’s power of sight. Why does this have to be? People without sight have been shown to be fully capable of spatial understanding, and have found their own ways of navigating space with their other senses. What if we could introduce a way for them to similarly absorb diagrams and drawings by translating them into touch.


The touch mouse aims to do just that. A webcam faces the whiteboard suspended by ball casters (which minimize smearing of the image). The image collected by the camera is processed to find the thresholds between light and dark areas, and triggers servo motors to lift and drop material under the user’s fingers to indicate dark spots above, below, or to either side of their current location. Using these indicators, the user can feel where the lines begin and end, and follow the traces of the diagram in space.
Inspiration
The video Jet showed in class showing special paper that a seeing person could draw on, to create a raised image for a blind person to feel and understand served as the primary inspiration for this project, but after beginning work on the prototype, I discovered a project at CMU using a robot to trace directions spatially to assist seeing impaired users in way-finding.

Similarly in the physical build I was heartened to see Engelbart’s original mouse prototype. This served double duty as inspiration for the form factor, and as an example of a rough prototype that could be refined into a sleek tool for everyday use.

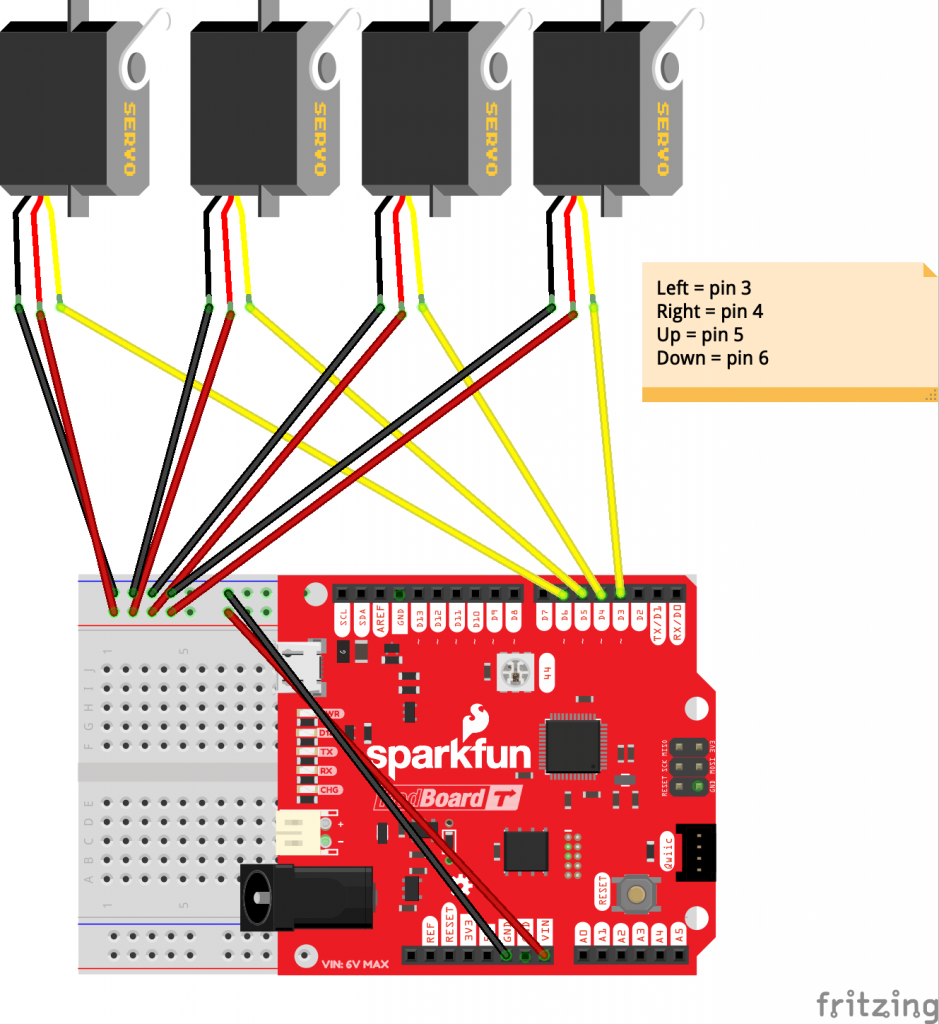
The Build and Code
The components themselves are pretty straightforward. Four servo motors lift and drop the physical pixels for the user to feel. A short burst of 1s and 0s indicates which pixels should be in which position.
The python code uses openCV to read in the video from the webcam, convert to grayscale, measure thresholds for black and white, and then average that down into the 4 pixel regions for left, right, up and down.
I hope to have the opportunity in the future to refine the processing pipeline, and the physical design, and perhaps even add handwriting recognition to allow for easier reading of labels, but until then this design can be tested for the general viability of the concept.
Python and Arduino code: