Project Description
My final project for this class was a set of 12 generative love-letter postcards, with the images on the front created by composing elements from the Google Quick, Draw! dataset into a “living room”, and the text on the back created by Markov Chains trained off of ~ 33,000 messages I’ve sent to my partner over the past year.
Inspirations & Ideation
At the onset of this project, I knew I wanted to create some kind of data-driven small multiples work that inspired by the care I have for my partner.
I was really touched by Lukas’ work for our mid-semester critique (2021), where he plotted a massive amount of zigzagging lines reflecting texts between him and his girlfriend. I had also enjoyed Caroline Hermans’ project exploring attention dynamics with linked scarves (2019), and “Dear Data” by Giorgia Lupi and Stefanie Posavec (2014–2015). All three projects exhibited the power of data to tell a story.

These projects helped convince me that data visualization is uniquely suited to tell the story of a longer-term, committed relationship—not in the manner of poets, with their manic, myopic focus on the singular rapturous moments, but in a fashion that underscores how a healthy relationship is built up of small, consistent gestures, day in and day out. (I hope my saying this doesn’t constitute an “interpretation” of my work; I only state it to illuminate why I decided on the tools I used to make the project.)
Since my project was composed of essentially two sections (the front and back of the postcards), I first explored how and why to generate text from a corpus of text messages. To aid me on my discovery of the why, Golan recommended Allison Parrish’s Eyeo 2015 talk, which I thoroughly enjoyed. I liked the analogy she drew between unmanned travel and exploration of strange language spaces. She posited that, in the same way a weather balloon can go higher and explore longer without the weight of a human, generative language can go into novel spaces without the weight of our intrinsic biases towards familiar meanings and concepts. I then learned the how from one of Parrish’s Jupyter Notebooks, where I gained the technical skills to train Markov Chains based on accumulated corpus of text.

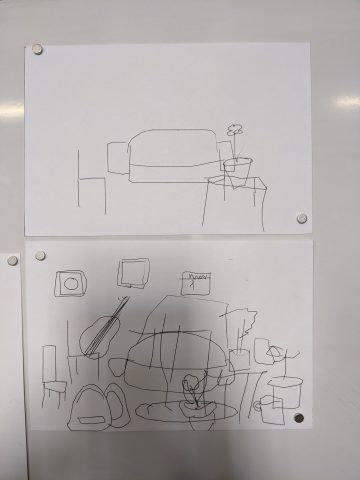
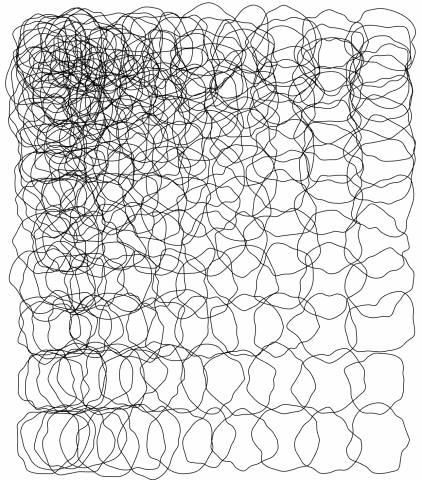
In my journey to brainstorm fronts for the postcards, Golan introduced me to the Google Quick, Draw! dataset, where users doodle different categories of objects (i.e., couches, house plants, etc.) in order to help researchers train ML classification models. I found the dataset oddly charming in its visual imperfections, and I loved how it provided a survey of how users think of different objects (how round a couch is to them, what kind of house plant they choose to draw). Additionally, I’ve always been intrigued by the concept of building a home and understanding the components (people, objects, light) that define a home. I thought generation from such a widely sourced database might be an interesting way to explore home construction without being weighed down by past personal connotations of home, or even traumas surrounding home. And so I decided on creating little living rooms as the front of the postcards.
Process
For the text of the postcards, I requested my message history data from Discord (yeah, yeah), which provided me with large .csvs of every message I’d ever sent through the platform. I picked out the .csv corresponding to my partner’s and my DMs, and manipulated it using Pandas, a process which included cleaning out non-ascii characters and sensitive information, and depositing lines of text into twelve different .txt files, the first of which held only messages from November 2020, the second of which held messages from November–December 2020, and so on until the twelfth held all messages from November 2020–October 2021. I processed the data in this manner in order to create twelve different paragraphs, each generated from a model trained on progressively more data, and composed of sentences that held words such as “love”, “sweet”, “want”, and so on, to give them the “love-letter” characteristic.
The progression of the twelve cards isn’t as clear as I hoped it’d be, but the first few postcards are still distinct in some ways from the last few, influenced by how much information each postcard had access to:


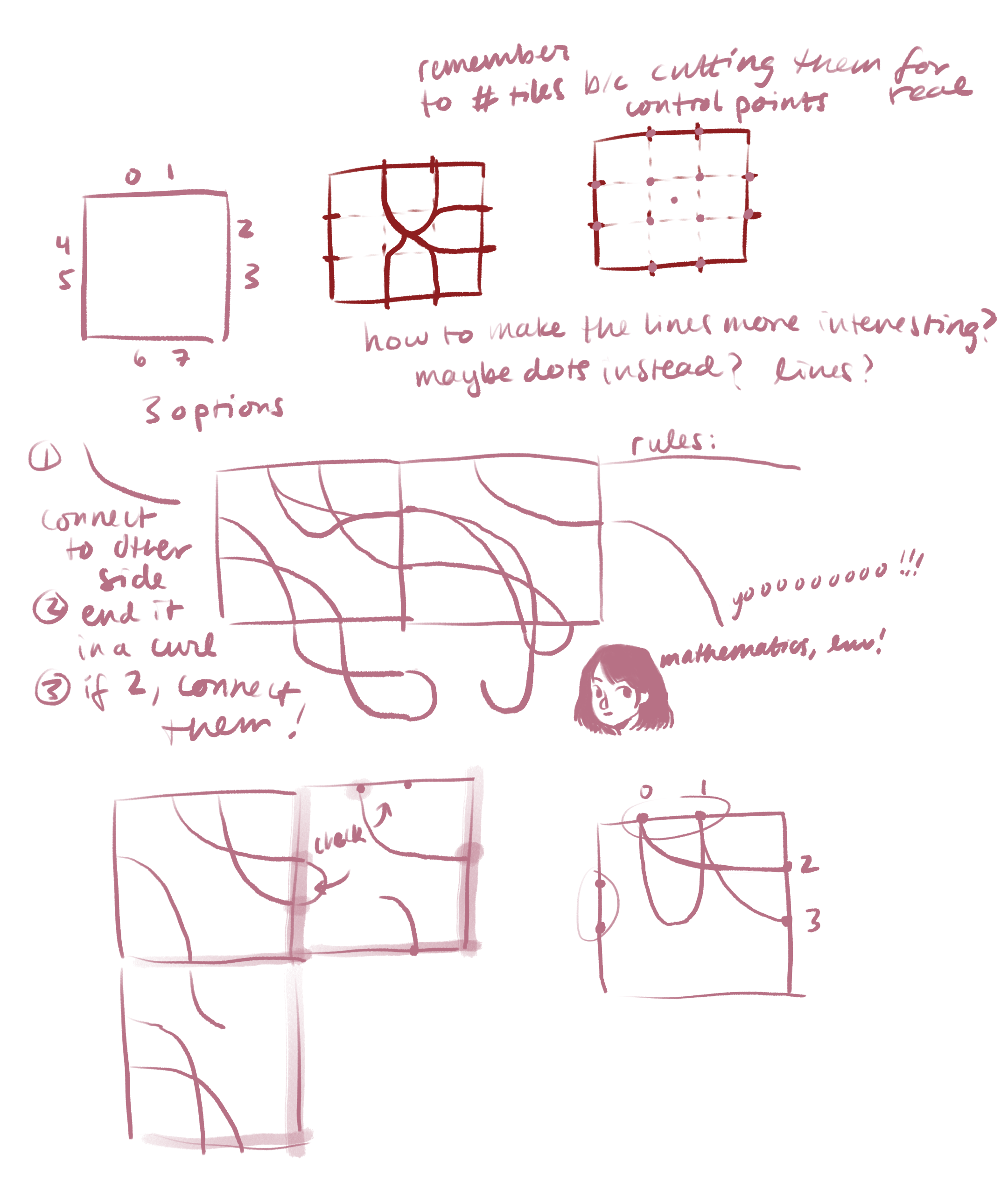
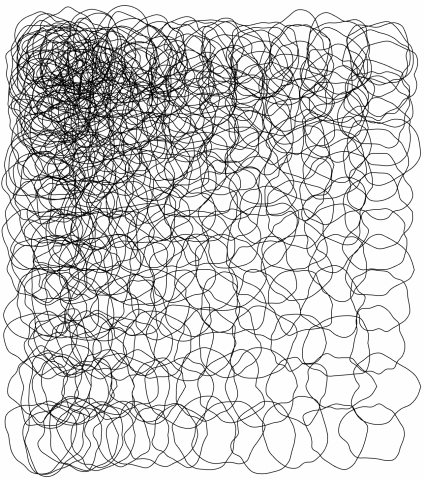
For the generative living rooms, I downloaded large .ndjson files of objects from the Quick, Draw! dataset I thought would go nicely into a living room, and randomly picked instances to place in random locations with random sizes (the latter two parameters limited by certain ranges). This was done in Python with the vsketch and vpype modules:


I then spent a few hours plotting double sided postcards, as shown below:
Further Documentation
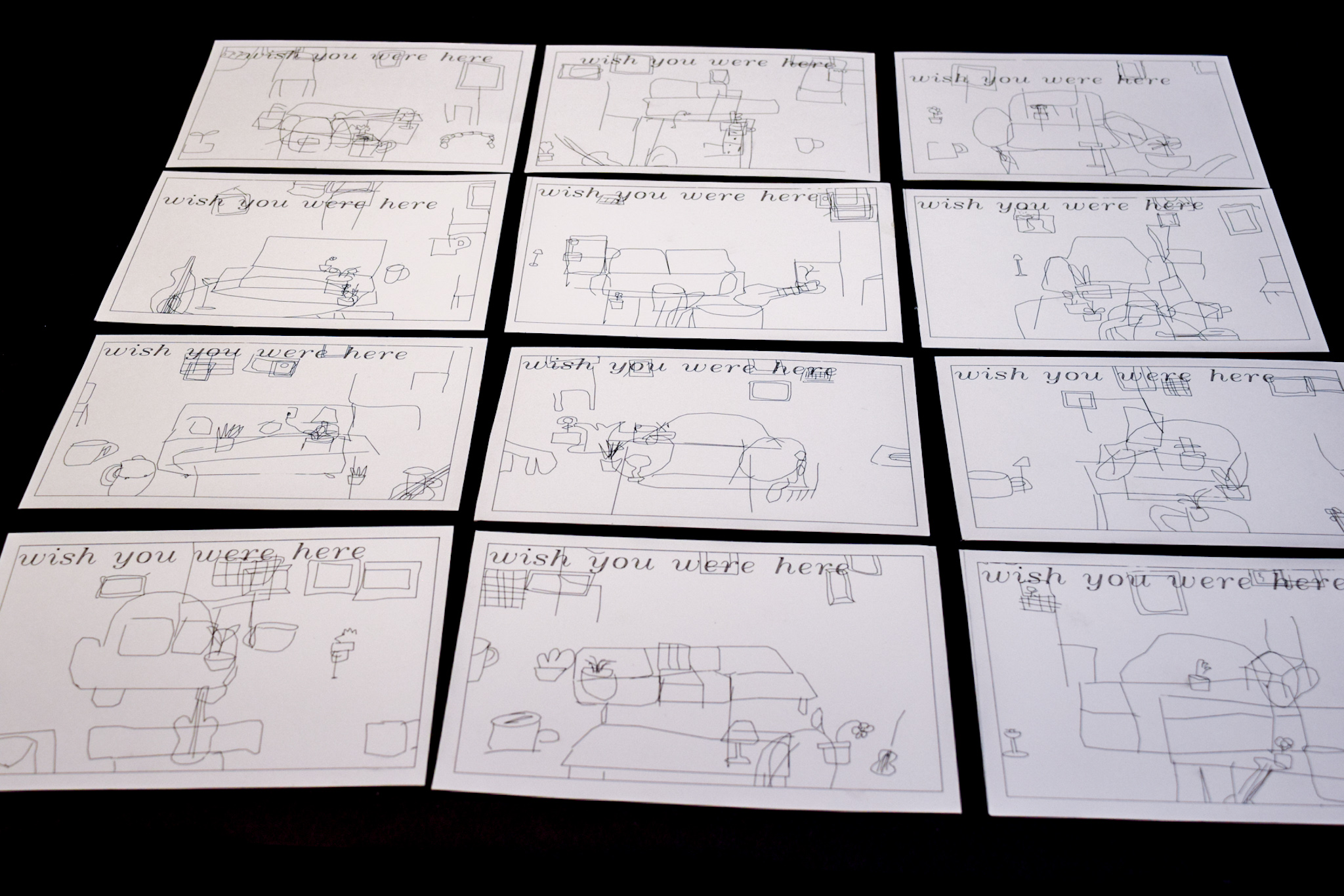


(.svgs of all the text sides of the postcards are posted under the cut)
Takeaways
Though I ultimately like what I created, I am unsatisfied by some elements of the final product. I found it difficult to create living rooms with what I felt was an appropriate balance of charm and order—the ones I ended up with feel overly chaotic and uneven in composition. Furthermore, I am disappointed that the progression of the paragraphs isn’t as clear as I hoped it’d be. I think to make it clearer I’d have to understand a little more about different models for text generation.
Overall, this project taught me how to use numerous tools/workflows (manipulation of .csvs, .ndjson/.jsons, data management and cleaning, generative image toolkits like vksetch, learning about naïve ML models, etc.). However, I am most thankful for the ideation process and how the project made me think about technology as a tool to express concepts/emotions that might be otherwise difficult to convey. I want to continue using the creative and technical skills I gained from this project to go forth and make new pieces like it!