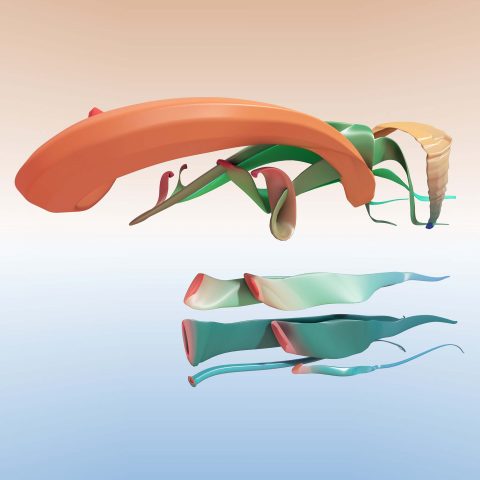
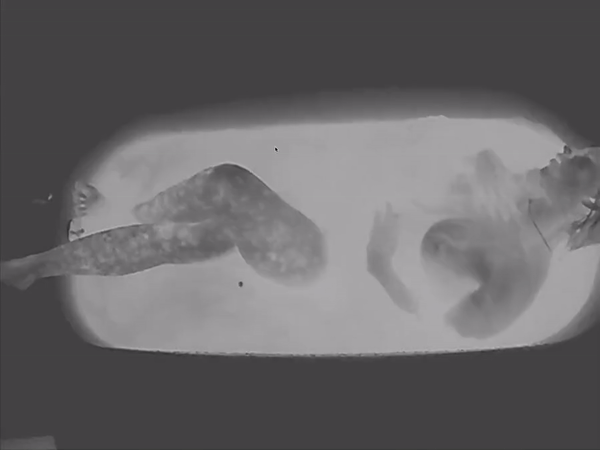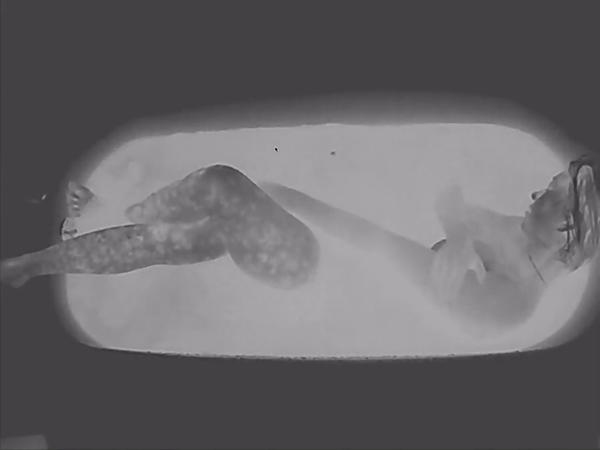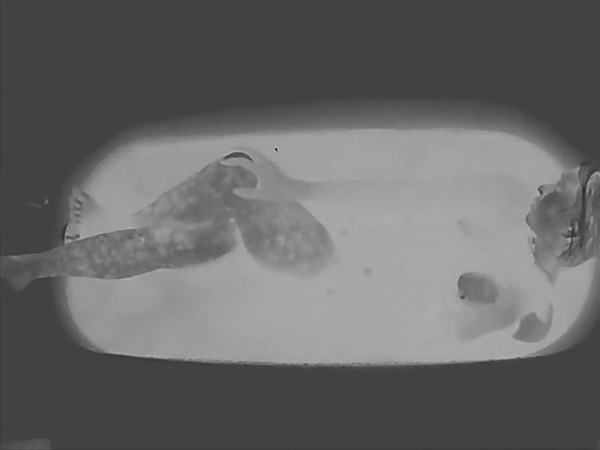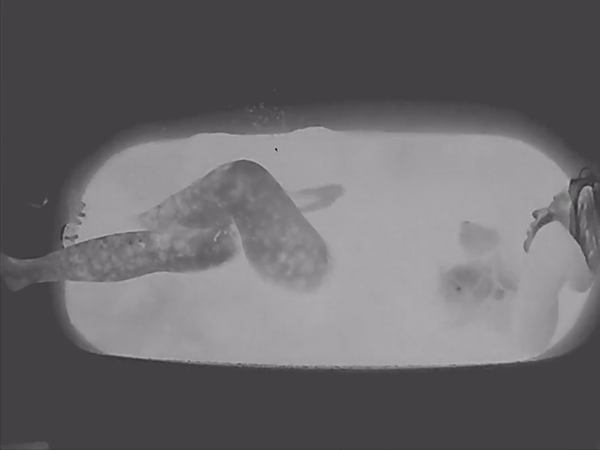
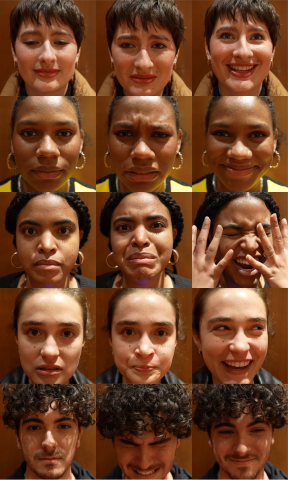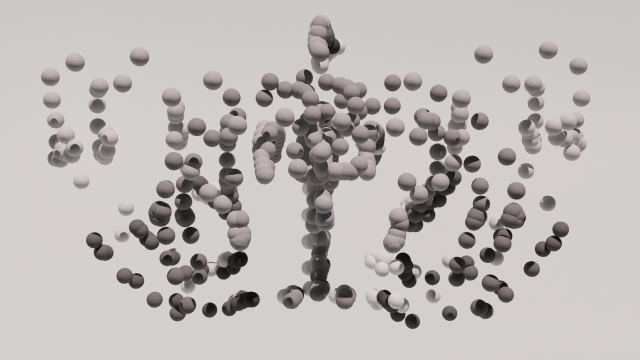For this project, I captured and isolated the movement of veins within the body. I was initially inspired by the Visible Human Project along with infrared photography due to the shared ability to capture what is hidden beneath our skin. And as someone who has a very turbulent relationship with their skin (I used to have a tendency to compulsively pick at it out of habit), I was also pretty keen on figuring out if there was a way I could somehow magically make this whole, giant organ suddenly disappear.
Near infrared vein finder
For person in time, I want to strip away a part of myself that I am constantly aware of and very accustomed to seeing, feeling, smelling everyday. When it is absent, will I still be able to recognize myself in the presented image?
Ideally, this portrait would have been a capture of only one person’s veins, but due to the difficulty of working with infrared technology, the end result consisted of veins from 2-3 people. Some people had prominent veins in certain areas/appendages and lacked them in others, so creating a collage of everyone’s most visible sections worked best.
I first captured veins under the skin using a camera with an infrared filter along with an infrared light. Once that was all done, I had to focus on extracting these veins from the footage. I initially played around with different methods of doing so (in After Effects and by using Ridge Filters and Adaptive Thresholding with python) and settled on a pipeline that implemented them both. I put individual stills from the footage (shout-out to miniverse for helping me figure out how to isolate and convert individual frames of my video footage) through a script which used ridge filters to detect and isolate any vessel-like structures. (source: https://www.youtube.com/watch?v=Fdhn5_gT1wY). I took the sato filtered image sequences and compiled them again into an After Effects composition. That is where I collaged together the animated body.
Infrared still from video of chestresult after ridge filters are applied
From a traditional standpoint, collaging body parts and making it look like one cohesive body is a hard thing to do, and especially when you want the body to be moving. Different attributes visually present itself on skin (like textures and colors of skin, mannerisms in particular movements, amount of hair, etc) that can allow the viewer to easily distinguish what parts belong to who. I now really want to see if viewers can still tell which part of the body belongs to different people when provided this portrait lacking the appendages we are used to seeing.
I set out to capture actors, who claimed to be able to cry on cue, to cry for me on camera. I’m really fascinated by crying, and I wanted to see how they would go about it, from the moment I called action to the moment I called cut. The video of the woman from Andy Warhol’s Screen Tests, who was crying from not blinking, inspired me.
Setup
I used a Sony A7 III camera and a wireless lapel microphone to capture each actor. I tried to get them in front of a blank wall in the Purnell lobby, but there weren’t many blank walls, so I sat them in front of a “Push to Open Door” button hoping their bodies would cover it, which worked most of the time, but not all the time (which you’ll see). That one tiny detail really bugs me, actually. If I had more time, I would edit the videos in After Effects to remove the button, but I did at least edit the photos.
Experience
This experiment really sparked a sense of competition and challenge within the actors. I would go up to a group of them and ask, “Can you cry on cue?” and the conversations almost always went one of three ways: “It depends on the day, and today I had a good and happy day, so I don’t think I can” or“I can’t, but you should ask ____! They can” or (when I went up to the person they told me to go to) “Wait, who said I can? That’s so weird they said that. I can’t, but you should ask ___! They can.” It was an endless loop.
To the few people who did say yes, I would say, “Great! Can I record you doing it then?” They’d always respond, “Wait, right now?” And I’d say, “You said you could cry on cue. This is your cue.”
At one point, I had actors lining up to try then chickening out then coming back then chickening out again. One person who ended up trying but couldn’t do it even asked me to not use their video because they were embarrassed. They got really competitive (with themselves, not each other) about it.
End Product
I attempted to format the videos like so: 1) I would call action, 2) they would begin, 3) I would let them do it for about 2 minutes and 30 seconds, then 4) I would call cut but keep rolling to see how they got themselves out of that place. I got a variety of videos, from people who got themselves to a sad place but without tears, to people who got tears, to people who gave up because they knew they weren’t going to get tears.
Along with the videos of each person, I have a 3-photo series from when I called action, their saddest moment, and their reaction after the cut.
Person 1 – P made it to the end but did not get tears
Person 2 – A made it to the end and got tears
Person 3 – S cut themselves off because they couldn’t keep going
Person 4 – O cut themselves off after getting tears
Person 5 – W cut themselves off because they couldn’t keep going
Closing Thoughts
I’m not very good with a camera (as I’m sure is evident), and I don’t enjoy working with them either, so this project ended up feeling kind of like a chore for me. The videos didn’t excite me that much after the fact, so after playing around with some ideas and landing on the 3-photo series, I ended up being a lot happier with the project.
For this project, I am using stop motion and paint to retrace my steps in the past two weeks.
This project was inspired by me and my friends joking about how we’re coming out of the fall break replenished, but will be walking dead in about a week. It was also inspired by my friends joking about how difficult it is to find time to do the things we want to do.
By using the form of a stop-motion animation on a white canvas, I can visualize the monotony of school week in straightforward, convinsing way. I attempt to capture how being trapped in the circle of school “muddies up” a person. The colors, even though bright and clean at first, becomes tainted and lose their shine after repetition and repetition of this circle.
The final step in the video is of a depressing color, but it breaks out of the circle and walks toward a new direction represented by the white spot. (Hopefully that will be me tomorrow :< )
Process:
I recorded the locations that I’ve been to every day since the end of fall break on my phone:
Then, I used red paint to represent Mellon Institute, yellow paint to represent campus/ETC, and blue to represent my home on the canvas. I then used my two fingers to “retrace” my steps among these locations.
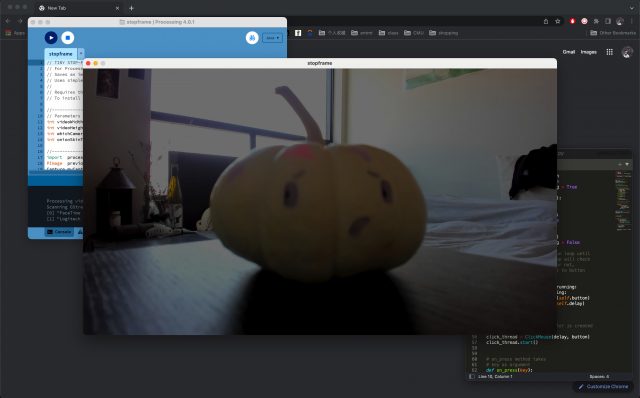
To create the stop-motion video, I reused the processing code for the stop-motion capture from the lecture. I also implemented a quick auto-clicker using Python, where the program can click the left mouse every five seconds. This frees up my hand from touching the computer repeatedly when I’m manipulating paint.
Software testing using my lil pumpkin 🙂 :
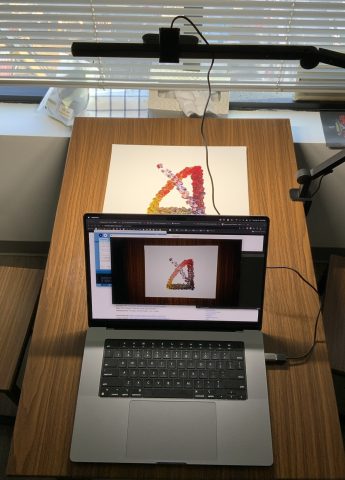
Setup for recording the stop motion:
Inspiration:
A project that greatly inspired me is a performance art by Zhilin (直林) for Alienware laptop promotion. In this performance art, he captures the monotony of stay-ar-home working routine trapped in a house, which is a norm nowadays because of the pandemic.
I’ve been wanting to integrate my background in dance into my art practice for a while now and Person in Time was the perfect project to start with. Originally I was interested in exploring basic/fundamental movement because, to me, the “quiddity” of those movements felt super apparent in my own body while dancing. However, after actually doing the motion capture, what I could see was that the most visually interesting aspect of my recorded motion was not the minute movement details (they were certainly there, but not really readable). What was cool to see was the circles that I was creating. Circular movements are a key component to many Chinese dance moves including the ones I performed. Funnily, I’d actually forgotten that was part of the movement theory that I’d been taught many years ago.
Balls: “点翻身 (Diǎn fānshēn)” turns in place
Balls: “串翻身 (Chuàn fānshēn)” traveling turns
Balls: “涮腰 (Shuàn yāo)” bending at waist
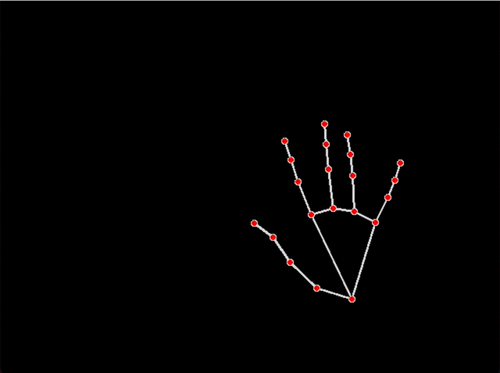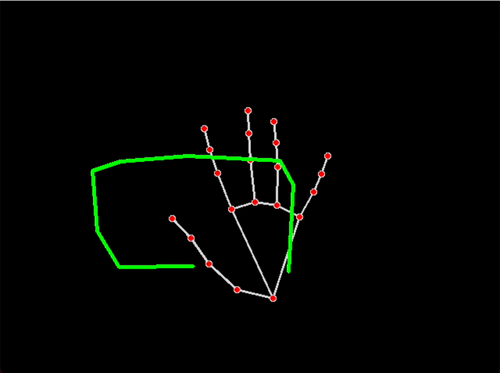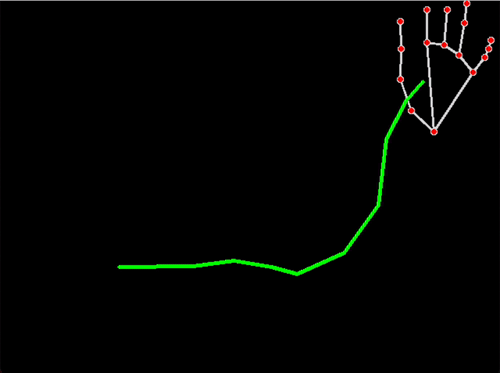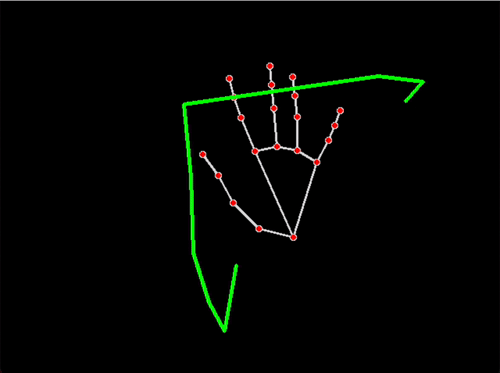
Activity/Situation Captured: circular movements in Chinese Dance moves
Inspiration:This motion capture visualization video that includes some Chinese traditional dance samples, a bunch of SCAD Renderman animations that use mocap data (notably, these do not create meshes or objects), and Lucio Arese’s Motion Studies:
Process:
This project had a two-fold process: performing and interpreting. For the performing part I needed to research, decide, and rehearse my movements before arranging a motion capture session. I started with some residual knowledge from when I used to do Chinese classical dance but watching recordings helped me re-familiarise myself with the movements. I decided on four small sections of choreography: “turning (with arms) in place,” a traveling version of turning (with arms), a large leaning movement, and some subtler arm movements.
I was able to arrange a time with Justin Macey to get into the Wean 1 motion capture studio and record all of my dance movements. Justin sent me all of the motion capture data we’d captured in .fbx format and I was able to import all of if directly into Blender. Inside blender, I wrote and then ran a Python script to extract the location data of each of the bones inside of the the animated armatures into text files (many thanks to Ashley Kim for helping me here c: ).
Mocap Data in .fbx in blender: 点翻身 (Diǎn fānshēn) “turn over”; 串翻身 (Chuàn fānshēn) “string turn over”; 涮腰 (Shuàn yāo) “waist”; 绕手腕 (Rào shǒuwàn) “around the wrist”
The next step I took was to write and a script to turn every point into spheres, this is initially where I stopped.
The interpreting process as a whole has been open ended and non-conclusive. I originally wanted to actually copy the SCAD Renderman method (link: http://www.fundza.com/rfm/ri_mel/mocap/index.html) before realizing that since it was renderman, the effects were only in the renders. I’d also hoped to use blenders meta balls because they have a cool sculptural quality but those posed a challenge to give separate materials to (also it crashed my entire file once so I gave up on them).
Even after figuring out a pipeline, it took a long time (for me) to do relatively little developmentally and (though I also didn’t really optimize the mesh-creation process) each cloud of 500-3000 balls took around 30 minutes to generate and then finagle into an exportable .obj format. As for the motions’ readability, it was OK: I found the results to be somewhat cool as abstract forms (I was familiar with the movements and shapes at this point). I played around a lot with assigning different colors across frames or body part to varying visual success I think (was a bit burnt out by all the coding so I did this by hand in excel and this gradient website).
On Nov. 1, during work time in class, while trying to figure out ways to get Sketchfab to display correctly on WordPress, Golan took a look at the models I had so far and said I should visualize motion trails instead of just disparate points. He was able to very quickly create a processing sketch that took every frame of data (I’d been using every 5th or 10th) and make lines and then turn those lines into an exportable mesh.
Example of alternate way to see motion with both points and lines (did not screen record well):
After exporting the .obj files, I took the models back into blender and turned the lines into tubes before exporting the final models you can see below.
For this project, I recorded my housemates eating various noodles with various cameras.
Process:
My primary research questions for this project were: Do my my housemates eat noodles differently? And if so, how?
I settled on this idea after spending some time with my family over fall break. During one dinner with my parents, I noticed how me and my dad peeled clementines differently: I peeled mine in a single continuous spiral while my dad preferred to peel off tiny scraps until a sizable pile accumulated on the dinner table.
This prompted me to think about how eating habits affect and translate to personalities. If you eat loudly and slouch, I assume you’re a lively and boisterous person. Similarly, if you eat quietly then I assume you’re a quiet person :/
I knew that I wanted to capture the quiddity of my housemates, for two reasons:
I have known these people for all four years of undergrad, some for even longer.
We live together and have lived together for the past 2 years. They already know about all of my shenanigans.
One of the hardest dishes to eat “politely” has got to be (in my opinion) a soupy bowl of noodles. If you’re not careful, they can splash everywhere. If your slurp game is nonexistent, you could end up with soup dribbling down your chin when you try to take a bite of noodle.
So I voiced my ideas to both Golan and Nica. After a couple of conversations with both of them, they each gave me many ideas about different ways I could record my housemates with a bowl of noodles.
So while I had initially just wanted to record some slurps, I realized I had to give my housemates a real challenge.
Experiment 1: Normal Eating
For this experiment, I just wanted a baseline for noodle comparisons. It didn’t take a lot of persuasion to get my housemates on board with this project (trade offer: I give you free food, you let me record you). I borrowed a camcorder and a shotgun microphone and sat each of my housemates down and recorded them all eating a bowl of noodles in one night. While there were some ingredients that varied between bowls (upon request of the eater to add ingredients they’d like) the base of the dish was still the same: ramen.
Here’s the video:
Something that was quite interesting about this result was that after filming, many of them said they felt the pressure from the camera just being pointed at them, that the noodles were very hot (oops), and they ate quicker because of the pressure. This was unfortunately expected from a direct recording. I had initially planned on putting a hidden camera somewhere in the house so that they wouldn’t notice they were being filmed, but I found it quite hard to find suitable hiding places for my camera. Plus, it’s very hard for me to lie to my housemates about random things, the moment I asked if I could make bowls of ramen for everyone out of nowhere I just spilled the beans.
I do think a hidden camera would have been interesting, perhaps in a different setting it would be a viable /more reliable experiment.
Experiment 2: 360 camera
This experiment entailed making a rig that would go in front of the wearer’s face while they were eating a bowl of noodles.
At first, I was given a Samsung Gear 360 camera to test out. Ultimately, after a night of fiddling with the camera, I decided that the accompanying software was shite (refused to work both on my phone and on my mac, they stopped supporting the app/desktop year ago) and gave up. I tried to manually unwarp the footage I got (double fisheye) with some crude methods.
Here’s a video of me eating some cheese + some other things.
I used very crude methods to unwarp the footage, and have included the ffmpeg commands used for the later two clips. Although I ultimately did not create the rig for the camera, since I couldn’t get the warp to look seamless enough, I do this think this is also a future experiment. Sidenote: (what I call) flat face photography is blowing my mind and I will be making more.
Experiment 3: a single noodle
For this experiment, I tried creating a single noodle to slurp. Since regular store bought noodles don’t come in outrageous sizes, I decided that making my own dough wouldn’t be too hard (first mistake).
I simply combined 11+ ounces of all-purpose flour with 5.5 ounces (combined) of water and 2 eggs. After kneading for a while, I knew I messed up the recipe. The dough was too sticky, and I most likely over-kneaded the dough trying to get the dough to a manageable consistency.
After I cut the dough into one continuous piece the “noodle” looked like this:
I then boiled the noodle, added some sauce, and gave it to one of my housemates to try.
This one in particular was a failure. Although they didn’t taste bad (according to said housemate), the noodles were way too thick and brittle, and it was almost like eating a pot full of dumpling skin. I think a future experiment would be to experiment with other dough recipes (using bread flour instead of all purpose, tweaking the water to flour ratio, time to let dough rest, adding oil) to see which would yield the longest “slurpable” noodle.
Experiment 4: Owl camera + Binaural Audio
This experiment was brought about after talking with Nica about my project. They asked if I had ever heard of the Owl camera, and I was surprised to learn that these hotshots are 360 footage + AI in ONE (wow :0 mind kablow). They’re used for hotshot zoom company meetings to allow people who are speaking at a meeting table to be broadcasted on the screen. I paired this device with a 3Dio Free Space binaural audio device, in hopes that I could capture some 360 SLURPING action.
These devices were relatively easy to use, the main difficulty was locating a circular table on campus: this one in particular is by the post office in the UC.
For the meal I prepared biang biang noodles in a cold soup with some meat sauce (a strange combination, but I wanted soup to be present for slurping). Biang Biang noodles are also super thick, so I thought it would be an interesting noodle to try. Ultimately this experiment became a mukbang of sorts.
Takeaways:
Overall, I think I was successful with this project in the fact that I completed what I set out to do with my initial research question. There were definitely many failures along the way as mentioned previously, but these failures only open up more pathways for exploration (in my opinion).
I’d definitely continue iterating on this project. There were many proposed experiments tossed around that ultimately I couldn’t do this time (but would love to do with more time). I also wanted to capture a group noodle eating session (out of one bowl). Another idea I had was to create a slurp detector (inspired by Sam Lavigne’s videogrep) so I could compile all the slurps from my noodle sessions, but I couldn’t get my audio detector to work in time. Golan had mentioned candele noodles as a kind of noodle particularly hard to slurp, and I think my housemates would be up to the challenge.
How would human flesh represent in the world of temperature? With our own body, silhouette, and skin, with touch, interaction and exchange? In the gradient of ink, I am using this opportunity to explore – how can I use temperature as my pigment, and how intimate, sensuous bodies compose a poetic song.
experiment & findings:
it’s cold to do it in winter./cold body in hot water works. /depending on your body temperature image has different contrast. the temperature of your body even on a small portion is not even./it not only detects temperature but also contrasts – the exposure. the movement would make it recalculate.
Special thanks to Steffi Narareth! *permission granted*
Cre·ate (verb) is a participatory video installation that invites the audience to create their own butterfly that follows the path of their hands using their hands. Regardless of background, anyone can create a butterfly of their own that flies along a distinctive path they defined.
Inspiration:
As AI based art generation tools like Dall E become more accessible to the public, I started to wonder what it means to create. What makes one to be the author of the creation? If an audience prompted the software like Dall E, which is developed by another person, and the software generates the artwork, does this work created by the audience or a developer or the software? Through this project, I wanted to explore what makes creation belong to an individual and how much of an authorship do the viewers take into consideration when seeing a collection of generated creations.
What I decide to capture:
Since creations are often made with hands, I decided to capture the movement of the creator’s hand during the act of creation. I also decided to make this an interactive audience participatory project instead of a project focusing on an artisan’s hands to challenge the general public’s misbelief in art making that only artists can make art.
Inspiration work:
Design-IO’s Connected Worlds project from 2015 is a real-time interactive piece that captures people’s pose and motion along with object placement then responds with changes in visuals on surrounding screens. Although my project doesn’t have a real-time interaction component that allows audience to change the positions of butterflies at any given time, both projects embodies the idea of inviting the audience to make changes in the piece.
Capture System Workflow:
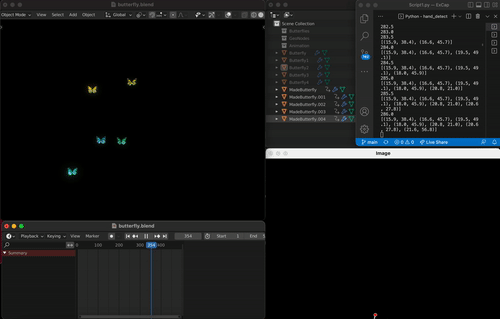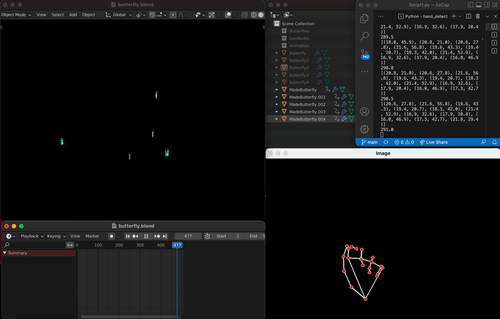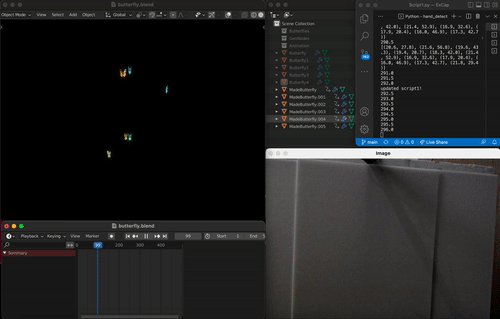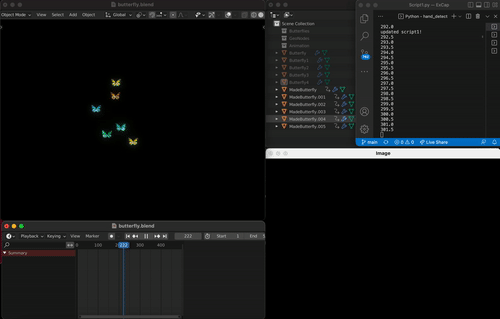
To make audience be the creator, I developed a workflow where the creation happens upon a hand motion of opening a fist is detected (as if you’re showing something that you caught or made with your hand).
I used mediapipe and open CV to gather hand gesture and position information. The path a new butterfly follows would be determined by the trace of audience’s thumb root joint. When the audience is ready to create a new butterfly that would be following their hand trace, they would close their fingers to make a fist then open up the hand to release the butterfly. Doing so would write the path list to a file, which would then be read by Blender python at each frame to generate a new butterfly with an animation key points of the hand path locations. I limited the path list length so that Blender won’t freeze importing and creating large number of frame key points.
(Recorded Trace Shown)
(Pipeline view of interaction above)
I made the butterfly model and used color ramp node in shader graph to randomize the color of the generated butterfly. I randomized the color with intention of giving a bit of diversity in the generated butterflies, but now that I’m looking back, perhaps I should have the butterflies to take the creator’s visual information as part of the generation so that each butterfly can be more customized to the creator. One idea of this would be having the butterfly wing texture to use creator’s hand image as a base color.
(Installation Views)
As also mentioned in my project proposal, I chose butterfly as an object to be created because creation starts with one’s idea. Butterfly often symbolizes metamorphosis and soul/mind, which fits well to this project’s exploration of act of creation (bringing an idea to a physical space) and authorship (idea/concept). The collective colorful glow of the generated butterflies let the viewers to both appreciate the group of butterflies from far or identify the specific butterfly one has created based on the path it follows.
Reflection:
Despite my initial prediction that the viewers would be able to easily identify the butterfly they created based on the trace they drew by moving their hand, I realized this wasn’t the case especially if there are more butterflies flying around on screen. As I mentioned earlier, I wish I made the function to generate butterflies with more customization so that anyone can easily find their creation while also appreciating the overall harmony of their work being part of those of many others. Even though this project was a great opportunity for me to learn and explore mediapipe and hand tracking using open cv, I also realized I could’ve utilized the hand tracking data more than just gather a past locations of a specific point of the hand. If I work on this project again, I would also take the data of how people move their hands in addition to where they move their hands. I think exploring how would bring more interesting insights to people in time, as different people move their bodies in a different manner even if they’re prompted to do the same movement.
A few weeks ago, I visited the Westmoreland Museum of Art. There, I saw a piece entitled “Between the Days” by Matt Bollinger, as part of the museum’s show on American realism:
As a painter, I enjoyed this Bollinger’s combination of painting realism with a digital medium to enable a narrative. You see his “hand” in that you have to imagine painting and repainting each frame in a way that you don’t with static paintings.
My own painting practice is nearly entirely private. My finished pieces go either on my wall, on the wall of whoever commissioned the piece, or under my bed. The only exception is that I occasionally send pictures to my loved ones, or –increasingly rarely – post them on social media.
I seek to demonstrate the awkward intermediate steps of creating a painting as a way of expressing and assembling my own quiddity. In this way, people are able to see how a painting develops over time, but also the missteps and context in which it is created.
I first engaged in data archeology to find these progress paintings. This proved to be an awkward endeavor in itself. Not only was it technologically challenging, in extracting digital ephemera from various devices and social media accounts over multiple years, but somewhat traumatizing in seeking for the needles of painting pictures amidst the haystack of past and sad parts of my life.
The result is a time lapse video where each intermediate picture is given 0.07 seconds on the screen. This represents an enormous compression of time – each of the two paintings presented took approximately 6 months each to complete, yet the resulting video is less than one minute. I have not cropped or sought to standardize the images in order to keep their context intact – context kept hidden to viewers of finished work.
At first, without sound, I found the result awkward. However, I found this awkwardness funny, so I decided to lean into this, so recorded a non-verbal but vocalized audio track of my reaction to each frame. In doing so, these grunts, cheers, and urghs provide an optional interpretive frame for the viewer to understand how I reacted to seeing my own process assembled – but I encourage viewers to first watch the video on mute to first collect their own interpretation.
***
David Gray Widder is a Doctoral Student in the School of Computer Science at Carnegie Mellon University where he studies how people creating “Artificial Intelligence” systems think about the downstream harms their systems make possible. He has previously worked at Intel Labs, Microsoft Research, and NASA’s Jet Propulsion Laboratory. He was born in Tillamook, Oregon and raised in Berlin and Singapore. You can follow his research on Twitter, art on Instagram, and life on both.