
To those who are reading, just don’t.
This is for presentation purposes only, will update a more readable version by the documentation deadline.
https://docs.google.com/presentation/d/1ms6qwQ3NxZzsNMV57IJTkCHsFD9nOZ2XZltgs-Xm-H8/edit?usp=sharing
CONTEXT:

Inside China’s Dystopian Dreams: A.I., Shame and Lots of Cameras
Chinese Abroad: Worried, Wary and Protesting


SHOW:
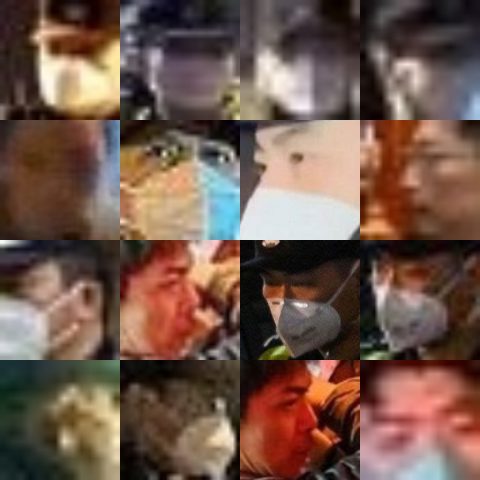

PRODUCT:
YOLO -> ViT -> Mediapipe
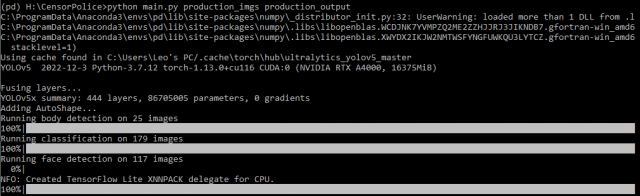
PROCESS:
Image scraping
Labeling
Training ViT
Building pipelines to link all 3 models together
get a face embedding using face-recognition
reduce dimension
cluster
visualize
Garbage:
Teachable machine
Face-recognition