Training GAN with runwayML
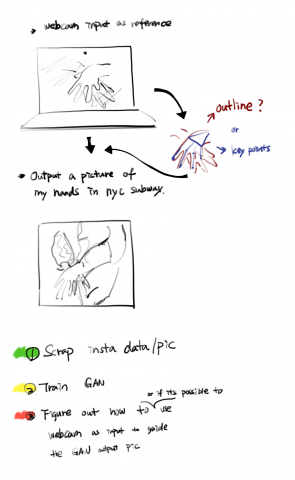
subwayHands
-
- Process:
- Instagram image scrape using selenium and bs4.
- This part took me the most time. Instagram makes it really difficult to scrape, I had to make several test dummy accounts to avoid having my own account banned by Instagram.
- Useful Tutorial: https://www.youtube.com/watch?v=FH3uXEvvaTg&t=869s&ab_channel=SessionWithSumit
- Image cleanup, crop(square) and resize(640*640px)
- After I scrapped this ig account’s entire page, I manually cleaned up the dataset to get rid of any images with face, more than two hands or no hands at all. And the remaining 1263 pictures are cropped and resized to be better processed by runwayML.
- Feed dataset to runwayML and let it do its magic.
- Instagram image scrape using selenium and bs4.
- Result: Link to google folder Link to runwayML Model
- When looking at the generated images zoomed out, thy defiantly share a visual proximity with the ig:subwayhands images.
- Process:
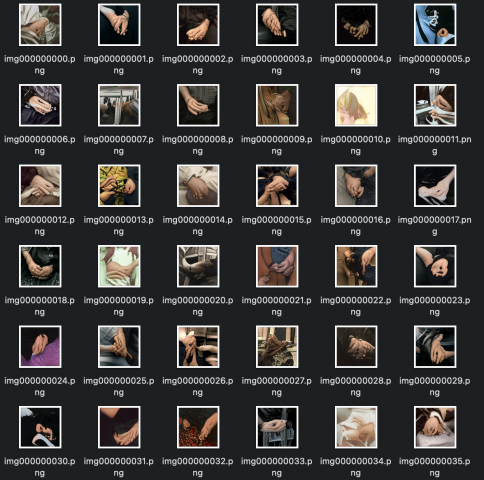
generated
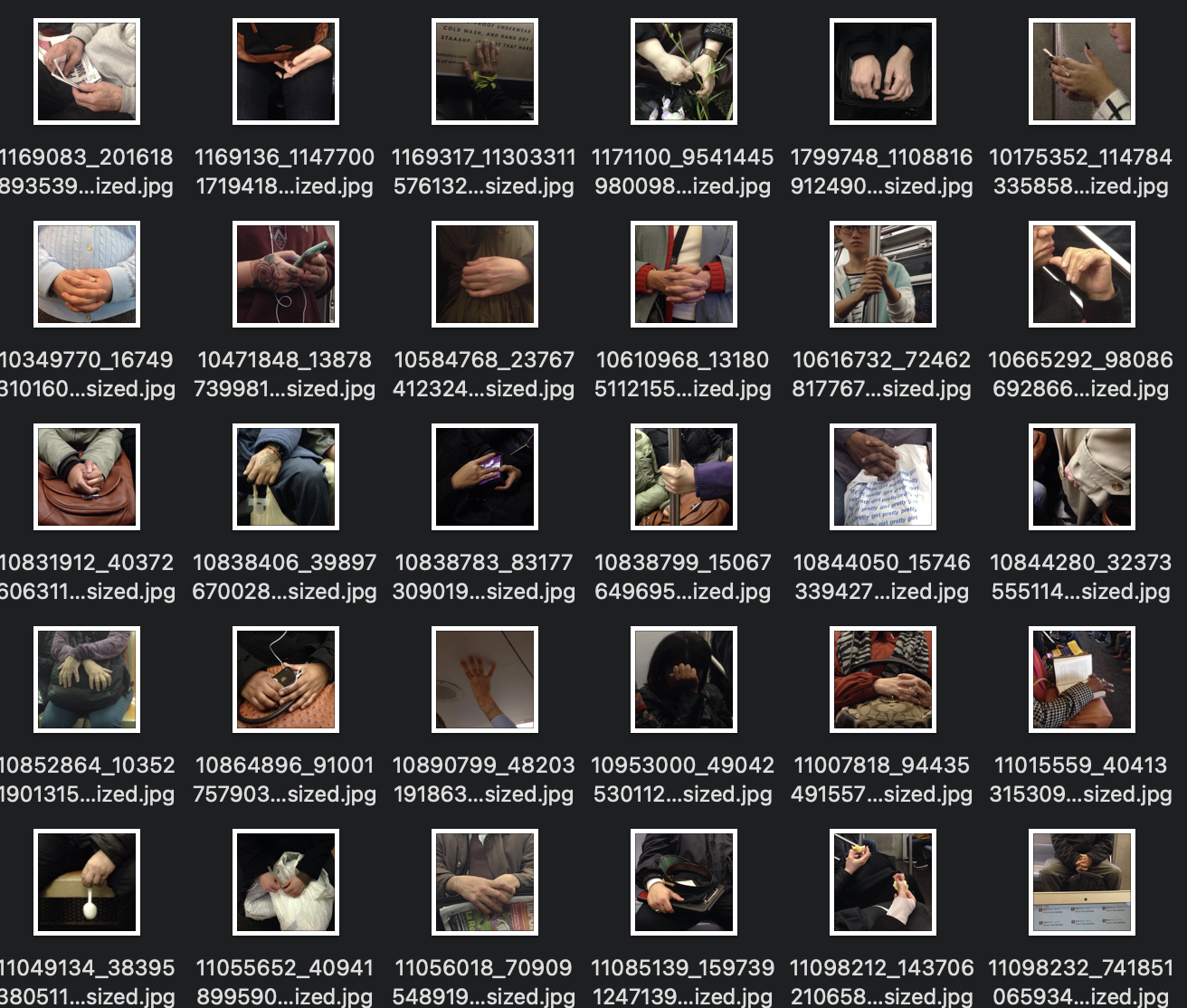
original
However, looking at the enlarged generated images, it’s clearly not quite at the level of actual hands. You can vaguely make out where the hand will be and what’s the posture of the hand/hands.




My Hair
-
- process:
- scan my hairs:

- I had this notebook full of my hairs that I collected throughout my freshmen year. I scanned them in to unified(1180px*1180px) squares, and at the end I was able to get an image dataset with 123 images of my own lost hairs.


- Feed dataset to runwayML and let it do its magic.
- scan my hairs:
- Result: Link to google folder Link to runwayML model




- Despite the small size of this dataset, the generated images exceeded my expectations and seems to more successfully resemble an actual picture of shower drain hair piece. This is probably because the hair dataset is much more regularized compared to the subway hands dataset. The imagery is also much simpler.
- process:








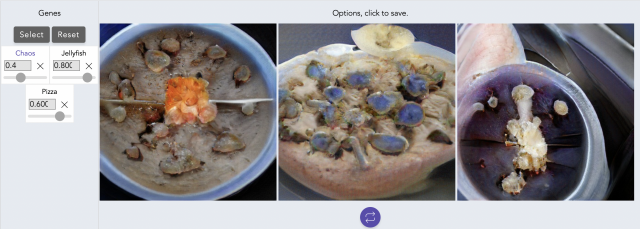
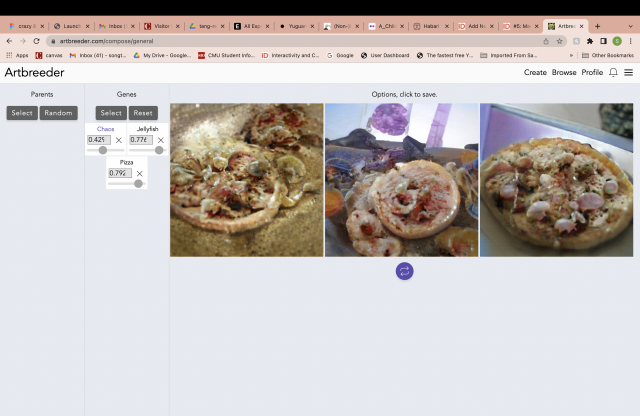
 It’s actually really hard to imagine what the outcome will be just based on the sliders. The resulted images aren’t really what I was expecting, but they do have somewhat distinguishable features from the genes.
It’s actually really hard to imagine what the outcome will be just based on the sliders. The resulted images aren’t really what I was expecting, but they do have somewhat distinguishable features from the genes.